1.准备utf-8编码的文本文件file
2.通过文件读取字符串 str
3.对文本进行预处理
4.分解提取单词 list
5.单词计数字典 set , dict
6.按词频排序 list.sort(key=)
7.排除语法型词汇,代词、冠词、连词等无语义词
8.输出TOP(20)
英文词频统计:
f = open('strgc.txt','r',encoding="utf-8") #从同一目录下读取文件 strgc = f.read().lower() #小写 f.close() print(strgc) seq ='.,' for ch in seq: strgc=strgc.replace(ch," ") #用for循环replace函数将.和,替换成空格 print(strgc) strList = strgc.split() #拆分 print(len(strList),strList) #分隔一个一个单词并统计英文单词个数 strSet = set(strList) #将列表转化成集合 exclude={"and","if","a","or","in","the"} strSet=strSet-exclude #去掉排除语法型词汇,代词、冠词、连词等无语义词 print(strSet) strDict={} for word in strSet: #再将集合转化成字典来统计每个单词出现次数 strDict[word] = strList.count(word) #只有列表可以统计 print(len(strDict),strDict) wclist =list(strDict.items()) #以列表返回可遍历的(键, 值) 元组数组 wclist.sort() #简单排序 print(strDict.items()) #def takeSecond(elem): #定义函数 # x=elem[1] # return x #wclist.sort(key=takeSecond,reverse=True) #排序,默认升序,reverse=true降序 法① wclist.sort(key=lambda x:x[1],reverse=True) #方法② 用lambda函数排序 print(wclist) for i in range(20): #输出前20个 print(wclist[i])
运行结果:

中文词频统计:
jieba是第三方库,需要在命令行输入 pip install jieba 下载安装,或者在:https://pypi.python.org/pypi/jieba/ 下载,解压:f:jieba-0.39 安装:python setup.py install
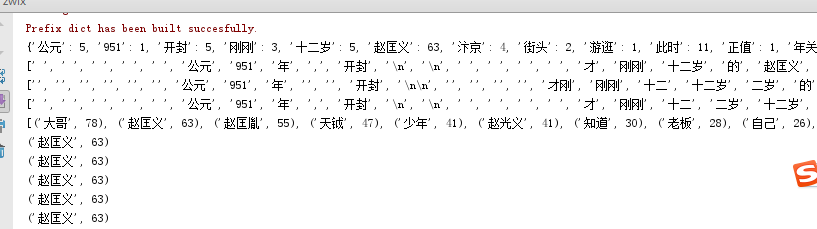
import jieba; f = open('xs.txt','r',encoding='utf-8') zwxs=f.read() f.close() wordsls = jieba.lcut(zwxs) #用字典形式统计每个词的字数 wcdict = {} for word in wordsls: if len(word)==1: continue else: wcdict[word]=wcdict.get(word,0)+1 print(wcdict) print(list(jieba.cut(zwxs))) #精确模式,将句子最精确的分开,适合文本分析 print(list(jieba.cut(zwxs,cut_all=True))) #全模式,把句子中所有的可以成词的词语都扫描出来,速度快,但不能解决歧义 print(list(jieba.cut_for_search(zwxs))) #搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词 wcls = list(wcdict.items()) #以列表返回可遍历的(键, 值) 元组数组 wcls.sort(key = lambda x:x[1],reverse=True) #出现词汇次数由高到低排序 print(wcls) for i in range(5): #第一个词循环遍历输出5次 print(wcls[1])
运行结果: