必备知识
-
计算机又叫电脑,即通电的大脑,发明计算机是为了让他通电之后能够像人一样去工作,并且它比人的工作效率更高,因为可以24小时不间断
-
计算机五大组成部分
控制器
运算器
存储器
输入设备
输出设备
计算机的核心真正干活的是CPU(控制器+运算器=中央处理器)
-
程序要想被计算机运行,它的代码必须要先由硬盘读到内存,之后cpu取指再执行
操作系统发展史
参考博客即可:https://www.cnblogs.com/Dominic-Ji/articles/10929381.html
- 穿孔卡片

- 联机批处理系统
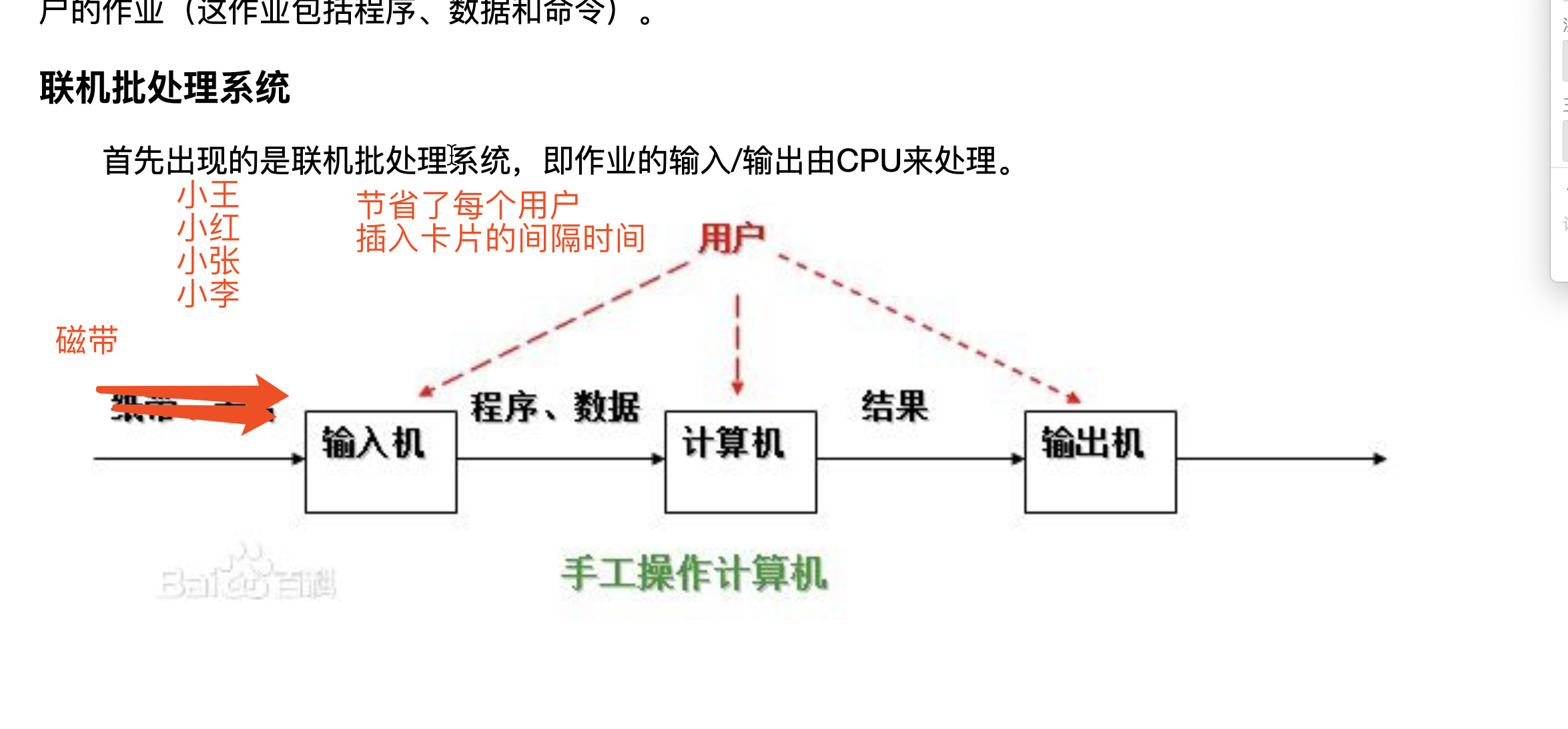
- 脱机批处理系统
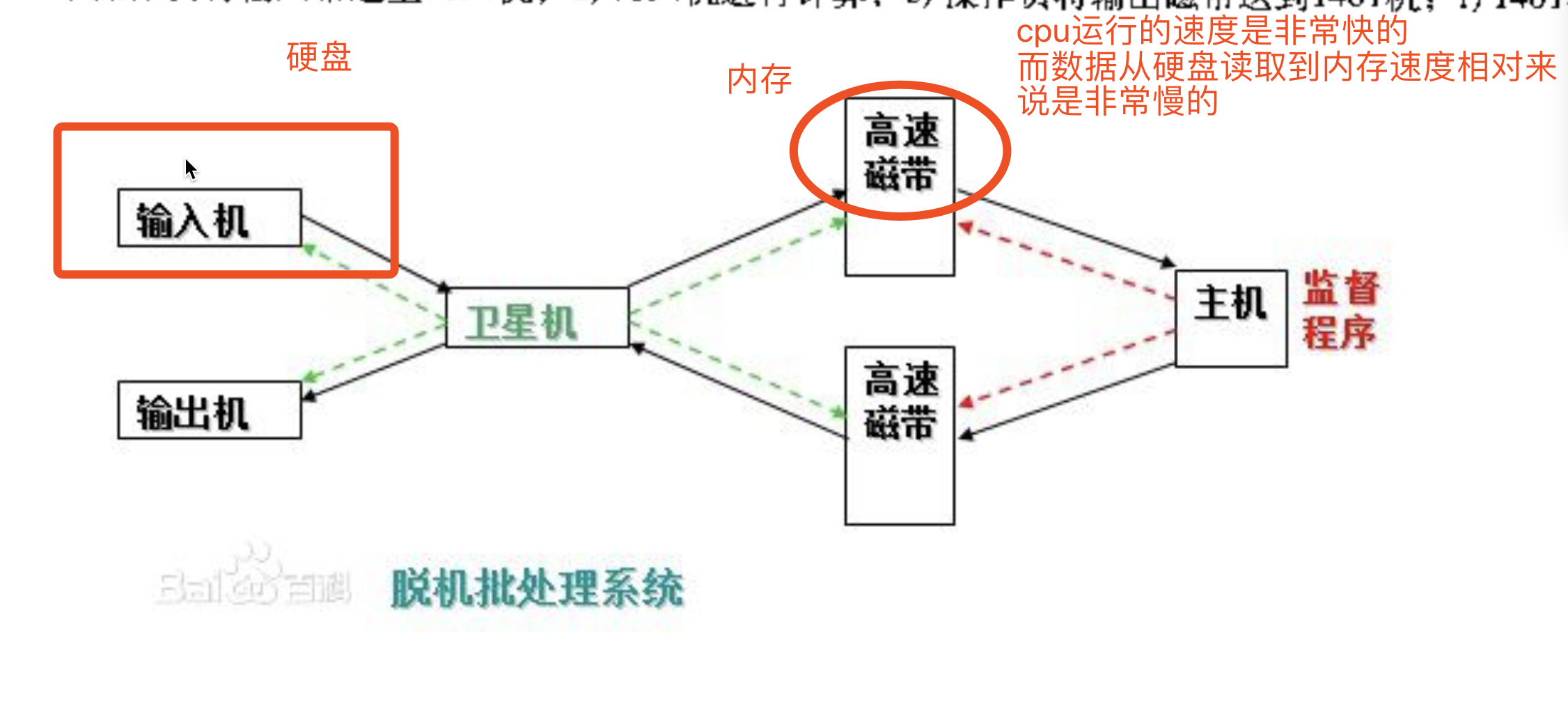
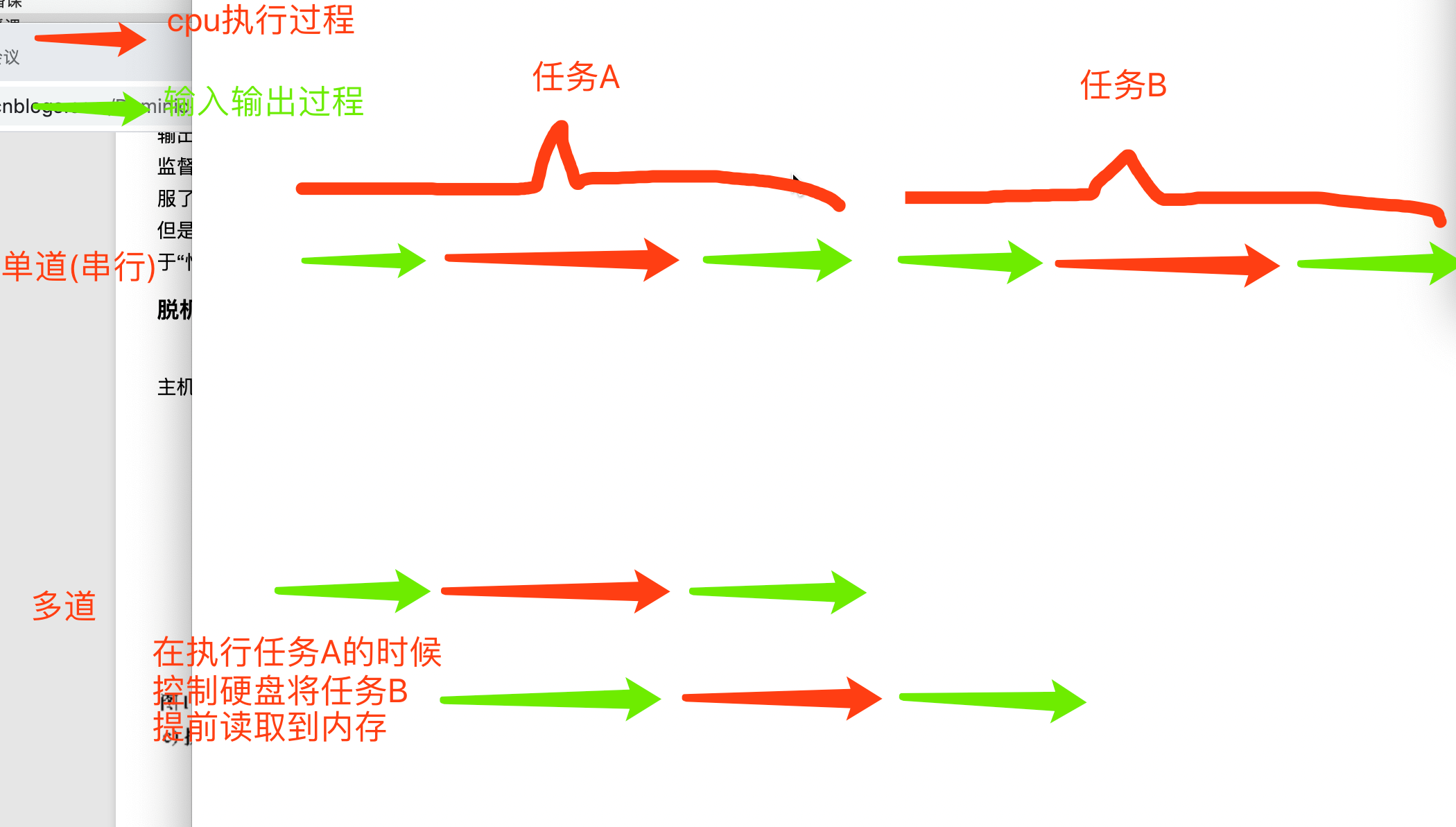
多道技术
单核实现并发的效果
必备知识点
-
并发
看起来像同时运行的就可以称之为并发
-
并行
真正意义上的同时执行
ps:
- 并行肯定算并发
- 单核的计算机肯定不能实现并行,但是可以实现并发!!!
补充:我们直接假设单核就是一个核,干活的就一个人,不要考虑cpu里面的内核数
多道技术图解
节省多个程序运行的总耗时
多道技术重点知识
空间上的服用与时间上的服用
-
空间上的复用
多个程序公用一套计算机硬件
-
时间上的复用
例子:洗衣服30s,做饭50s,烧水30s
单道需要110s,多道只需要任务做长的那一个 切换节省时间
例子:边吃饭边玩游戏 保存状态
切换+保存状态
""" 切换(CPU)分为两种情况 1.当一个程序遇到IO操作的时候,操作系统会剥夺该程序的CPU执行权限 作用:提高了CPU的利用率 并且也不影响程序的执行效率 2.当一个程序长时间占用CPU的时候,操作吸引也会剥夺该程序的CPU执行权限 弊端:降低了程序的执行效率(原本时间+切换时间) """
进程理论
程序与进程的区别
程序就是一堆躺在硬盘上的代码,是“死”的 进程则表示程序正在执行的过程,是“活”的
进程调度
-
先来先服务调度算法
"""对长作业有利,对短作业无益"""
- 短作业优先调度算法
"""对短作业有利,多长作业无益"""
- 时间片轮转法:当你要打开新程序的时候会停下当前在执行的先把你新程序给他开
进程运行的三状态图
所有的程序想要被执行必须先经历就绪态

事件请求包括input,print,open一类
阻塞态到就绪态:input获取到值,文件读取完成,timesleep结束

两对重要概念
同步和异步
描述的是任务的提交方式
-
同步:任务提交之后,原地等待任务的返回结果,等待的过程中不做任何事,程序层面上表现的感觉就是卡住了
-
异步:任务提交之后,不原地等待任务的返回结果,直接去做其他事情,等待任务的返回结果
任务的返回结果会有一个异步的回调机制
阻塞和非阻塞
描述的是程序的运行状态
- 阻塞:阻塞态
- 非阻塞:就绪态,运行态
最高效的一种组合就是异步+非阻塞
理想状态:我们应该让我们写的代码永远处于就绪态和运行态,没有阻塞
开启进程的两种方式
代码开启进程和线程的方式,代码书写基本是一样的,学会了如何开启进程就学会了如何开启线程
两种方式
from multiprocessing import Process
import time
def task(name):
print('%s is running'%name)
time.sleep(3)
print('%s is over'%name)
if __name__ == '__main__':
# 1 创建一个对象
p = Process(target=task, args=('jason',))
# 容器类型哪怕里面只有1个元素 建议要用逗号隔开
# 2 开启进程
p.start() # 告诉操作系统帮你创建一个进程 异步
print('主')
# 第二种方式 类的继承
from multiprocessing import Process
import time
class MyProcess(Process):
def run(self):
print('hello bf girl')
time.sleep(1)
print('get out!')
if __name__ == '__main__':
p = MyProcess()
p.start()
print('主')
windows操作系统下,创建进程一定要在main内创建,因为windows下创建进程类似于模块导入的方式,会从上往下执行
第一种方式用的比较多
总结
创建进程就是在内存中申请一块内存空间,将需要运行的代码丢进去,一个进程对应在内存中就是一块独立的内存空间,多个进程对应的是多块独立的内存空间
进程与进程之间的数据在默认状态下无法直接交互,如果想交互可以借助别的工具,模块
join方法
主进程等待子进程结束之后,再继续往后执行
结果就是把异步变成同步
from multiprocessing import Process
import time
def task(name, n):
print('%s is running'%name)
time.sleep(n)
print('%s is over'%name)
if __name__ == '__main__':
# p1 = Process(target=task, args=('jason', 1))
# p2 = Process(target=task, args=('egon', 2))
# p3 = Process(target=task, args=('tank', 3))
# start_time = time.time()
# p1.start()
# p2.start()
# p3.start() # 仅仅是告诉操作系统要创建进程
# # time.sleep(50000000000000000000)
# # p.join() # 主进程等待子进程p运行结束之后再继续往后执行
# p1.join()
# p2.join()
# p3.join()
start_time = time.time()
p_list = []
for i in range(1, 4):
p = Process(target=task, args=('子进程%s'%i, i))
p.start()
p_list.append(p)
for p in p_list:
p.join()
print('主', time.time() - start_time)
进程之间数据相互隔离
from multiprocessing import Process
money = 100
def task():
global money # 局部修改全局
money = 666
print('子',money)
if __name__ == '__main__':
p = Process(target=task)
p.start()
p.join()
print(money)
进程对象的其他方法
"""
一台计算机上面运行着很多进程,那么计算机是如何区分并管理这些进程服务端的呢?
计算机会给每一个运行的进程分配一个PID号
如何查看
windows电脑
进入cmd输入tasklist即可查看
tasklist |findstr PID查看具体的进程
mac电脑
进入终端之后输入ps aux
ps aux|grep PID查看具体的进程
"""
from multiprocessing import Process, current_process
import time
import os
def task():
# print('%s is running' % current_process().pid) # 查看当前进程的进程号
print('子进程 %s is running' % os.getpid()) # 查看当前进程的进程号
print('子进程的主进程号: %s' % os.getppid()) # 查看当前进程的父进程的进程号
time.sleep(30)
if __name__ == '__main__':
p = Process(target=task)
p.start()
p.terminate() # 杀死当前
# 是告诉操作系统帮你去杀死当前进程 但是需要一定的时间 而代码的运行速度极快
time.sleep(0.1)
print(p.is_alive()) # 判断当前进程是否存活
# print('主pid:', current_process().pid)
print('主pid:', os.getpid())
print('主主pid:', os.getppid())
僵尸进程与孤儿进程(了解)
# 僵尸进程 """ 死了但是没有死透 当你开设了子进程之后 该进程死后不会立刻释放占用的进程号 因为我要让父进程能够查看到它开设的子进程的一些基本信息 占用的pid号 运行时间。。。 所有的进程都会步入僵尸进程 父进程不死并且在无限制的创建子进程并且子进程也不结束 回收子进程占用的pid号 父进程等待子进程运行结束 父进程调用join方法 """ # 孤儿进程 """ 子进程存活,父进程意外死亡 操作系统会开设一个“儿童福利院”init进程(进程号1)所收养,专门管理孤儿进程回收相关资源 """
守护进程
from multiprocessing import Process
import time
def task(name):
print('%s公公正在活着'% name)
time.sleep(3)
print('%s正在死亡' % name)
if __name__ == '__main__':
p = Process(target=task,args=('矮跟',))
# p = Process(target=task,kwargs={'name':'矮跟'})
p.daemon = True # 将进程p设置成守护进程 这一句一定要放在start方法上面才有效否则会直接报错
p.start()
print('皇帝鸡哥寿终正寝')
互斥锁
多个进程操作同一份数据的时候,会出现数据错乱的问题
针对上述问题,解决方式就是加锁处理:将并发变成串行,牺牲效率但是保证了数据的安全
from multiprocessing import Process, Lock
import json
import time
import random
# 查票
def search(i):
# 文件操作读取票数
with open('data','r',encoding='utf8') as f:
dic = json.load(f)
print('用户%s查询余票:%s'%(i, dic.get('ticket_num')))
# 字典取值不要用[]的形式 推荐使用get 你写的代码打死都不能报错!!!
# 买票 1.先查 2.再买
def buy(i):
# 先查票
with open('data','r',encoding='utf8') as f:
dic = json.load(f)
# 模拟网络延迟
time.sleep(random.randint(1,3))
# 判断当前是否有票
if dic.get('ticket_num') > 0:
# 修改数据库 买票
dic['ticket_num'] -= 1
# 写入数据库
with open('data','w',encoding='utf8') as f:
json.dump(dic,f)
print('用户%s买票成功'%i)
else:
print('用户%s买票失败'%i)
# 整合上面两个函数
def run(i, mutex):
search(i)
# 给买票环节加锁处理
# 抢锁
mutex.acquire()
buy(i)
# 释放锁
mutex.release()
if __name__ == '__main__':
# 在主进程中生成一把锁 让所有的子进程抢 谁先抢到谁先买票
mutex = Lock()
for i in range(1,11):
p = Process(target=run, args=(i, mutex))
p.start()
"""
扩展 行锁 表锁
注意:
1.锁不要轻易的使用,容易造成死锁现象(我们写代码一般不会用到,都是内部封装好的)
2.锁只在处理数据的部分加来保证数据安全(只在争抢数据的环节加锁处理即可)
"""
进程间的通信
队列Queue模块
"""
管道:subprocess
stdin stdout stderr
队列:管道+锁
队列:先进先出
堆栈:先进后出
"""
from multiprocessing import Queue
# import queue
# q = queue.Queue()
q = Queue(3) # 括号中的数字代表生成的队列可同时存放的最大数据量
q.put(111) # 向队列中存入数据
q.put(222)
q.put(333)
print('队列是否已满:', q.full()) # 判断生成的对列是否已满
# q.put(444) # 当存入的数据量大于最大数据量时,程序会进入阻塞态,并不会报错
v1 = q.get() # 获取队列中的数据
v2 = q.get()
v3 = q.get()
print(v1, v2, v3)
print('队列的数据是否取完:', q.empty()) # 判断队列中的数据是否取完
# v4 = q.get() # 当获取的数据量大于最大数据量时,程序也会进入阻塞态, 等待队列传数据,同样也不会报错
"""
存取数据 存是为了更好的取
千方百计的存、简单快捷的取
"""
# 去队列中取数据
v1 = q.get()
v2 = q.get()
v3 = q.get()
print(v1, v2, v3)
# V4 = q.get_nowait() # 没有数据直接报错queue.Empty
# v4 = q.get(timeout=3) # 没有数据之后原地等待三秒之后再报错 queue.Empty
try:
v4 = q.get(timeout=3)
print(v4)
except Exception as e:
print('队列的数据是否取完:', q.empty()) # 判断队列中的数据是否取完
# v4 = q.get() # 队列中如果已经没有数据的话 get方法会原地阻塞
"""
q.full()
q.empty()
q.get_nowait()
在多进程的情况下是不精确
"""
IPC机制
"""
研究思路
1.主进程跟子进程借助于队列通信
2.子进程跟子进程借助于队列通信
"""
from multiprocessing import Queue, Process
def producer(q):
q.put('工号9527 为您服务')
def consumer(q):
print(q.get())
if __name__ == '__main__':
q = Queue()
p1 = Process(target=producer, args=(q, ))
v1 = Process(target=consumer, args=(q,))
p1.start()
v1.start()
生产者消费者模型
"""
生产者:生产/制造东西的
消费者:消费/处理东西的
该模型除了上述两个之外还需要一个媒介
生活中的例子做包子的将包子做好后放在蒸笼(媒介)里面,买包子的取蒸笼里面拿
厨师做菜做完之后用盘子装着给你消费者端过去
生产者和消费者之间不是直接做交互的,而是借助于媒介做交互
生产者(做包子的) + 消息队列(蒸笼) + 消费者(吃包子的)
"""
# from multiprocessing import Queue, Process
from multiprocessing import JoinableQueue, Process
import random
import time
def producer(name, food, q):
for num in range(1, 4):
print('%s 制作 %s 1笼' % (name, food))
# 模拟网络延迟
time.sleep(random.randint(1, 2))
# 将数据加入队列
q.put(food)
def consumer(name, q):
while True:
food = q.get() # 假如没有数据,程序就会在此处进入堵塞态
# 判断当前是否有结束的标识
# if food is None:break
time.sleep(random.randint(1, 3))
print('%s食用了%s' % (name, food))
q.task_done() # 告诉队列你已经从里面取出了一个数据并且处理完毕了
if __name__ == '__main__':
# q = Queue()
q = JoinableQueue()
p1 = Process(target=producer, args=('大厨', '小笼包', q))
p2 = Process(target=producer, args=('大厨', '灌汤包', q))
c1 = Process(target=consumer, args=('umi', q))
p1.start()
p2.start()
# 将消费者设置成守护进程
c1.daemon = True
c1.start()
p1.join()
p2.join()
# 等待生产者生产完毕之后 往队列中添加特定的结束符号
# q.put(None) # 有多少消费者就往队列中添加多少None,新添加的None必定在队列的末尾
q.join() # 等待队列中所有的数据被取完再执行往下执行代码
"""
JoinableQueue 每当你往该队列中存入数据的时候 内部会有一个计数器+1
没当你调用task_done的时候 计数器-1
q.join() 当计数器为0的时候 才往后运行
"""
# 只要q.join执行完毕 说明消费者已经处理完数据了 消费者就没有存在的必要了
线程理论
什么是线程
''' 进程:资源单位 线程:执行单位 将CPU比喻成一个工厂,那么进程就是工厂的一个个车间,线程就是车间中的流水线作业 每一个进程必定会自带一个线程 总结: 进程:资源单位(起一个进程仅仅只是在cpu中申请一块独立的空间) 线程:执行单位(cpu真正执行的其实是进程中的线程,线程指的就是代码的执行过程,执行代码时所需的资源都跟自己所在的进程索取) 进程和线程都是虚拟单位,只是为了我们更加方便的描述问题 '''
为何要有线程
""" 开设进程 1.申请内存空间 耗资源 2.“拷贝代码” 耗资源 开线程 一个进程内可以开设多个线程,在同一个进程内开设多个线程无需再次申请内存空间操作 总结: 开设线程的开销要远远的小于进程的开销 同一个进程下的多个线程数据是共享的!!! """ 假设开发一个文本编辑器 1、获取用户输入的功能 2、实时展示到屏幕的功能 3、自动保存到硬盘的功能 要实现上述三个功能,开设线程跟进程哪个更合适? 开三个线程处理上面的三个功能更加的合理。