聚类,与其说他是机器学习,不如说是数据挖掘,对数据直接进行处理
前提假设:
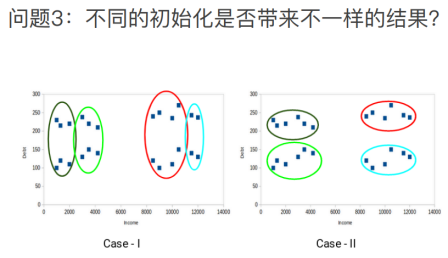
假设你的数据分布是均匀的,不希望你的数据是稀疏或密集时候,用k-means是不理想的;对异常值比较敏感,对初始化也很敏感。
假设数据特征之间的联合分布是椭圆的,这个条件在真实世界很难满足。
K-means算法:
初始化 :随机选择K个点,作为初始中心点,每个点代表一个group
交替更新:
- 计算每个点到所有中心点的距离,把最近的距离记录下来并
赋把group赋给当前的点 - 针对于每一个group里的点,计算其平均并作为这个group的
新的中心点。


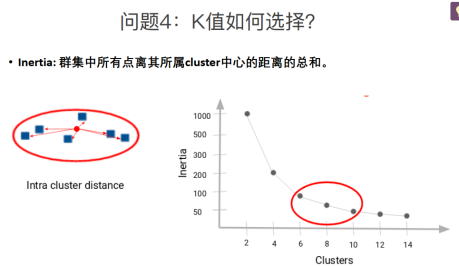
问题4:K值如何选择:找Inertia的拐点
K-Means++
与k-means初始化不同:
1.从数据点中随机选择一个中心。
2. 对于每个数据点x, 计算D(x), 即x与已经选择的最接近中心之间的距离。
3. 使用加权概率分布随机选择一个新的数据点作为新的中心,其中选择点 x
的概率与D(x)^2成正比。
4. 重复步骤2和3,直到选择了k个中心。
5. 现在已经选择了初始中心,继续使用标准k均值聚类。
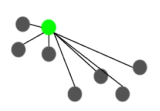
例子:假设k=3时,

-->
-->
-->