HiveServer
查看/home/hadoop/bigdatasoftware/apache-hive-0.13.1-bin/bin目录文件,其中有hiveserver2
启动hiveserver2,如下图:

打开多一个终端,查看进程

有RunJar进程说明hiveserver正在运行;
beeline
启动beeline
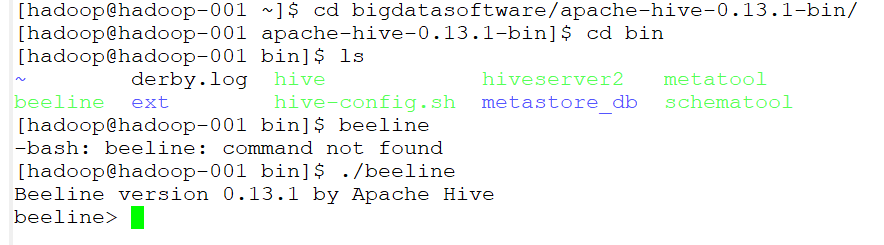
连接到jdbc
!connect jdbc:hive2://hadoop-001:10000 hadoop hadooporg.apache.hive.jdbc.HiveDriver;

然后就可以进行一系列操作了
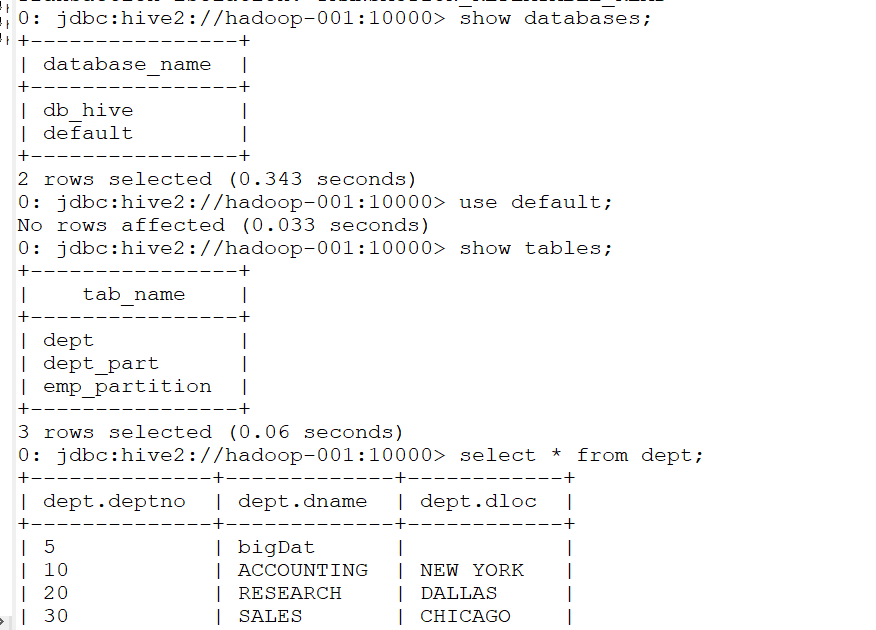
IDEA上jdbc客户端操作hive
Using JDBC
You can use JDBC to access data stored in a relational database or other tabular format.
-
Load the HiveServer2 JDBC driver. As of 1.2.0 applications no longer need to explicitly load JDBC drivers using Class.forName().
For example:
Class.forName("org.apache.hive.jdbc.HiveDriver");
-
Connect to the database by creating a
Connectionobject with the JDBC driver.
For example:
Connection cnct = DriverManager.getConnection("jdbc:hive2://<host>:<port>", "<user>", "<password>");
The default
<port>is 10000. In non-secure configurations, specify a<user>for the query to run as. The<password>field value is ignored in non-secure mode.
Connection cnct = DriverManager.getConnection("jdbc:hive2://<host>:<port>", "<user>", "");
In Kerberos secure mode, the user information is based on the Kerberos credentials.
-
Submit SQL to the database by creating a
Statementobject and using itsexecuteQuery()method.
For example:
Statement stmt = cnct.createStatement(); ResultSet rset = stmt.executeQuery("SELECT foo FROM bar");
- Process the result set, if necessary.
These steps are illustrated in the sample code below.
代码如下:
package com.gec.demo; import java.sql.SQLException; import java.sql.Connection; import java.sql.ResultSet; import java.sql.Statement; import java.sql.DriverManager; public class HiveJdbcClient { private static final String DRIVERNAME = "org.apache.hive.jdbc.HiveDriver"; /** * @param args * @throws SQLException */ public static void main(String[] args) throws SQLException { try { Class.forName(DRIVERNAME); } catch (ClassNotFoundException e) { // TODO Auto-generated catch block e.printStackTrace(); System.exit(1); } //replace "hive" here with the name of the user the queries should run as Connection con = DriverManager.getConnection("jdbc:hive2://hadoop-001:10000/default", "hadoop", "hadoop"); Statement stmt = con.createStatement(); String tableName = "dept"; // stmt.execute("drop table if exists " + tableName); // stmt.execute("create table " + tableName + " (key int, value string)"); // show tables String sql = "show tables '" + tableName + "'"; System.out.println("Running: " + sql); ResultSet res = stmt.executeQuery(sql); if (res.next()) { System.out.println(res.getString(1)); } // describe table sql = "describe " + tableName; System.out.println("Running: " + sql); res = stmt.executeQuery(sql); while (res.next()) { System.out.println(res.getString(1) + " " + res.getString(2)); } // load data into table // NOTE: filepath has to be local to the hive server // NOTE: /tmp/a.txt is a ctrl-A separated file with two fields per line // String filepath = "/"; // sql = "load data local inpath '" + filepath + "' into table " + tableName; // System.out.println("Running: " + sql); // stmt.execute(sql); // select * query sql = "select * from " + tableName; System.out.println("Running: " + sql); res = stmt.executeQuery(sql); while (res.next()) { System.out.println(String.valueOf(res.getInt(1)) + " " + res.getString(2)); } // regular hive query sql = "select count(1) from " + tableName; System.out.println("Running: " + sql); res = stmt.executeQuery(sql); while (res.next()) { System.out.println(res.getString(1)); } } }
pom.xml配置文件如下:
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <parent> <artifactId>BigdataStudy</artifactId> <groupId>com.gec.demo</groupId> <version>1.0-SNAPSHOT</version> </parent> <modelVersion>4.0.0</modelVersion> <artifactId>HiveJdbcClient</artifactId> <name>HiveJdbcClient</name> <!-- FIXME change it to the project's website --> <url>http://www.example.com</url> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <maven.compiler.source>1.8</maven.compiler.source> <maven.compiler.target>1.8</maven.compiler.target> <hadoop.version>2.7.2</hadoop.version> <!--<hive.version> 0.13.1</hive.version>--> </properties> <dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.11</version> <scope>test</scope> </dependency> <dependency> <groupId>org.apache.logging.log4j</groupId> <artifactId>log4j-core</artifactId> <version>2.8.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.7.2</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>${hadoop.version}</version> </dependency> <dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-jdbc</artifactId> <version>0.13.1</version> </dependency> <dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-exec</artifactId> <version>0.13.1</version> </dependency> </dependencies> </project>