1、hashMap数据结构
jdk8 : 数组 + 列表 + 红黑树
2、JDK1.8中对hash算法和寻址算法的优化?
jdk1.8对hash算法的优化: 将key的hash值和它的高16位做了异或运算,因为寻址算法的时候,与hash的低十六位进行与运算,所以要让低十六位同时保持高低十六位的特征(假如两个hash值的高十六位不一样,低十六位一样,如果不进行高低异或那么可能计算出来的位置是相同的),可以减少hash冲突。
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }
寻址算法优化:取模运算效率比较低,所以采用了与运算。当n为2的次方时,hash对n取模 = (n-1)& hash
3、为什么是2的n次方
- 当n为2的次方时,hash对n取模 = (n-1)& hash
- 假如DEFAULT_INITIAL_CAPACITY为15,那么(n - 1) & hash 就变成了 14 & hash 即 01110 & hash,因为01110的尾数为0,那么01110 & hash 不可能出现尾数为1的情况,导致table上尾数为1的位置不能存放元素,空间浪费大,使用的位置比数组长度小很多,导致碰撞的几率增大,所以hashmap的初始化大小都是2的次方。
4、put流程
- 判断table是否创建,不存在就创建table
- 根据key的hash值定位在数组中的位置,如果为null就直接插入桶中
- 判断定位到桶位置的首节点是否和key一样,一样则直接覆盖,然后进行扩容判断
- 如果key不一致,判断是不是treeNode,如果是执行红黑树的添加
- 如果不是红黑树,则遍历链表尾插的方式插入链表,判断如果数量大于等于阈值(8)就转换为红黑树。中途如果发现key相同就进行覆盖。
- 插入成功之后判断是否需要扩容
5、hash碰撞
在碰撞的位置挂了一个链表,在链表中存放多个元素。get的时候如果发现位置挂了一个链表,遍历链表找到自己找的key-value对就可以了
如果链表很长,查询性能O(n)
优化:链表长度超过8,会转换为红黑树。时间复杂度O(logn),查询性能高
6、resize()优化
元素在重新计算hash之后,因为n变为2倍,那么n-1就是在高位多1bit(红色),因此有原有的hash值进行与运算的时候,只要查看hash值中n-1多出来的1的位置是0还是1,如果是0那么位置不变。如果是1那么新的索引就是原来的索引 + 扩容的大小
https://blog.csdn.net/weixin_30814319/article/details/95851285
7、HashMap的环
假如new HashMap(2),有三个entry待加入: (3,A)、(7,B)、(5,C)
- 线程A, transfer方法的Entry next = e.next这一句 ,此时(3,A)的next指向7,时间片耗尽
- 线程B,执行并且resize()完成,容量变为4,重新计算后(7,B)的next指向(3,A)
- 线程A,重新调度,添加完(3,A)后,添加(7,B),线程B已经将(7,B)的next改为(3,A)了,就会形成环形链表,死循环
- JDK1.8以后使用了尾插法,在扩容时会保持链表原本的顺序,就不会出现链表死循环的问题了
8、ConcurrentHashMap的结构
在JDK1.7中ConcurrentHashMap采用了数组+Segment+分段锁的方式实现。
1.Segment(分段锁)
ConcurrentHashMap中的分段锁称为Segment,它即类似于HashMap的结构,即内部拥有一个Entry数组,数组中的每个元素又是一个链表,同时又是一个ReentrantLock(Segment继承了ReentrantLock)。
2.内部结构
ConcurrentHashMap使用分段锁技术,将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问,能够实现真正的并发访问。如下图是ConcurrentHashMap的内部结构图:
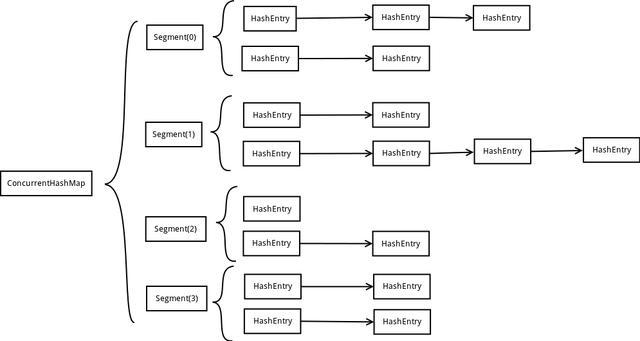
从上面的结构我们可以了解到,ConcurrentHashMap定位一个元素的过程需要进行两次Hash操作。
第一次Hash定位到Segment,第二次Hash定位到元素所在的链表的头部。
3.该结构的优劣势
坏处
这一种结构的带来的副作用是Hash的过程要比普通的HashMap要长
好处
写操作的时候可以只对元素所在的Segment进行加锁即可,不会影响到其他的Segment,这样,在最理想的情况下,ConcurrentHashMap可以最高同时支持Segment数量大小的写操作(刚好这些写操作都非常平均地分布在所有的Segment上)。
所以,通过这一种结构,ConcurrentHashMap的并发能力可以大大的提高。
JDK8中ConcurrentHashMap参考了JDK8 HashMap的实现,采用了数组+链表+红黑树的实现方式来设计,内部大量采用CAS操作
JDK8 PUT流程
* 当添加一对键值对的时候,首先会去判断保存这些键值对的数组是不是初始化了,
* 如果没有的话就初始化数组
* 然后通过计算hash值来确定放在数组的哪个位置
* 如果这个位置为空则直接添加,如果不为空的话,则取出这个节点来
* 如果取出来的节点的hash值是MOVED(-1)的话,则表示当前正在对这个数组进行扩容,复制到新的数组,则当前线程也去帮助复制
* 最后一种情况就是,如果这个节点,不为空,也不在扩容,则通过synchronized来加锁,进行添加操作
* 然后判断当前取出的节点位置存放的是链表还是树
* 如果是链表的话,则遍历整个链表,直到取出来的节点的key来个要放的key进行比较,如果key相等,并且key的hash值也相等的话,
* 则说明是同一个key,则覆盖掉value,否则的话则添加到链表的末尾
* 如果是树的话,则调用putTreeVal方法把这个元素添加到树中去
* 最后在添加完成之后,会判断在该节点处共有多少个节点(注意是添加前的个数),如果达到8个以上了的话,
* 则调用treeifyBin方法来尝试将处的链表转为树,或者扩容数组
9、ConcurrentHashMap使用什么技术来保证线程安全
jdk1.7:Segment(继承ReentrantLock)+HashEntry来进行实现的;
jdk1.8:放弃了Segment臃肿的设计,采用Node+CAS+Synchronized来保证线程安全;
10、ConcurrentHashMap1.7和1.8的区别
- JDK1.7版本的ReentrantLock+Segment+HashEntry,到JDK1.8版本中synchronized+CAS+HashEntry+红黑树。
- 数据结构:取消了Segment分段锁的数据结构,取而代之的是数组+链表+红黑树的结构。
- 保证线程安全机制:JDK1.7采用segment的分段锁机制实现线程安全,其中segment继承自ReentrantLock。JDK1.8采用CAS+Synchronized保证线程安全。
- 锁的粒度:原来是对需要进行数据操作的Segment加锁,现调整为对每个数组元素加锁(Node)。
- 链表转化为红黑树:定位结点的hash算法简化会带来弊端,Hash冲突加剧,因此在链表节点数量大于8时,会将链表转化为红黑树进行存储。
- 查询时间复杂度:从原来的遍历链表O(n),变成遍历红黑树O(logN)。
11. synchronized和Lock的区别(必考)
- Lock是一个接口,sychronized是关键字
- synchronized发生异常的时候会自动释放锁,lock发生异常的时候,如果没有主动释放锁,极有可能造成死锁
- lock可以让等待锁的线程响应中断,syn不能响应中断
- lock可以知道有没有获取锁,syn不行
- lock的等待时需要 调用await()、signal()、singnalAll()。syn是调用的wait()、notify()、notifyAll()
- Lock可以提高多个线程进行读操作的效率。(可以通过readwritelock实现读写分离)
用法:
syn可以修饰方法或者代码块。
lock一般使用ReentrantLock作为锁,在加锁和解锁的时候通过lock() 和 unlock()显示调用
性能:
synchronized是托管给JVM执行的,
而lock是java写的控制锁的代码。
在Java1.5中,synchronize是性能低效的。因为这是一个重量级操作,需要调用操作接口,导致有可能加锁消耗的系统时间比加锁以外的操作还多。相比之下使用Java提供的Lock对象,性能更高一些。
但是到了Java1.6,发生了变化。synchronize在语义上很清晰,可以进行很多优化,有适应自旋,锁消除,锁粗化,轻量级锁,偏向锁等等。导致在Java1.6上synchronize的性能并不比Lock差。官方也表示,他们也更支持synchronize,在未来的版本中还有优化余地。
2种机制的具体区别:
synchronized原始采用的是CPU悲观锁机制,即线程获得的是独占锁。独占锁意味着其他线程只能依靠阻塞来等待线程释放锁。而在CPU转换线程阻塞时会引起线程上下文切换,当有很多线程竞争锁的时候,会引起CPU频繁的上下文切换导致效率很低。
而Lock用的是乐观锁方式。所谓乐观锁就是,每次不加锁而是假设没有冲突而去完成某项操作,如果因为冲突失败就重试,直到成功为止。乐观锁实现的机制就是CAS操作(Compare and Swap)。我们可以进一步研究ReentrantLock的源代码,会发现其中比较重要的获得锁的一个方法是compareAndSetState。这里其实就是调用的CPU提供的特殊指令。
现代的CPU提供了指令,可以自动更新共享数据,而且能够检测到其他线程的干扰,而 compareAndSet() 就用这些代替了锁定。这个算法称作非阻塞算法,意思是一个线程的失败或者挂起不应该影响其他线程的失败或挂起的算法
12. ThreadLocal的原理和实现
https://www.cnblogs.com/TripL/p/13396312.html
13. 为什么要使用线程池(必考)
- 避免频繁创建和销毁线程
- 在JVM中创建过多的线程可能会导致过度的内存消耗
- 避免线程过多引起的上下文切换
- 重用线程可以使程序响应更快
- 控制线程的数量
9. 核心线程池ThreadPoolExecutor的参数(必考)
10. ThreadPoolExecutor的工作流程(必考)
11. 如何控制线程池线程的优先级
12. 线程之间如何通信
13. Boolean占几个字节
理由来源是《Java虚拟机规范》一书中的描述:“虽然定义了boolean这种数据类型,但是只对它提供了非常有限的支持。在Java虚拟机中没有任何供boolean值专用的字节码指令,Java语言表达式所操作的boolean值,在编译之后都使用Java虚拟机中的int数据类型来代替,而boolean数组将会被编码成Java虚拟机的byte数组,每个元素boolean元素占8位”。这样我们可以得出boolean类型占了单独使用是4个字节,在数组中又是1个字节。
显然第三条是更准确的说法,那虚拟机为什么要用int来代替boolean呢?为什么不用byte或short,这样不是更节省内存空间吗。大多数人都会很自然的这样去想,我同样也有这个疑问,经过查阅资料发现,使用int的原因是,对于当下32位的处理器(CPU)来说,一次处理数据是32位(这里不是指的是32/64位系统,而是指CPU硬件层面),具有高效存取的特点
14. jdk1.8/jdk1.7都分别新增了哪些特性
15. Exception和Error
16. Object类内的方法
* 当添加一对键值对的时候,首先会去判断保存这些键值对的数组是不是初始化了,
* 如果没有的话就初始化数组
* 然后通过计算hash值来确定放在数组的哪个位置
* 如果这个位置为空则直接添加,如果不为空的话,则取出这个节点来
* 如果取出来的节点的hash值是MOVED(-1)的话,则表示当前正在对这个数组进行扩容,复制到新的数组,则当前线程也去帮助复制
* 最后一种情况就是,如果这个节点,不为空,也不在扩容,则通过synchronized来加锁,进行添加操作
* 然后判断当前取出的节点位置存放的是链表还是树
* 如果是链表的话,则遍历整个链表,直到取出来的节点的key来个要放的key进行比较,如果key相等,并且key的hash值也相等的话,
* 则说明是同一个key,则覆盖掉value,否则的话则添加到链表的末尾
* 如果是树的话,则调用putTreeVal方法把这个元素添加到树中去
* 最后在添加完成之后,会判断在该节点处共有多少个节点(注意是添加前的个数),如果达到8个以上了的话,
* 则调用treeifyBin方法来尝试将处的链表转为树,或者扩容数组