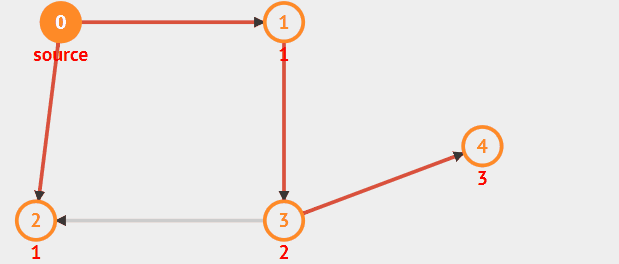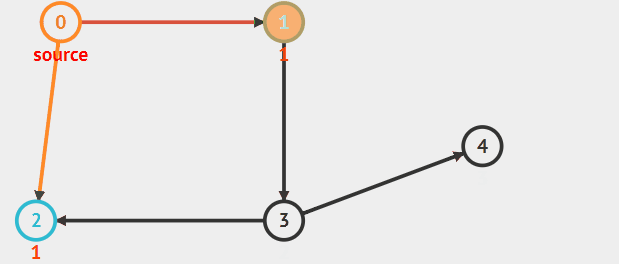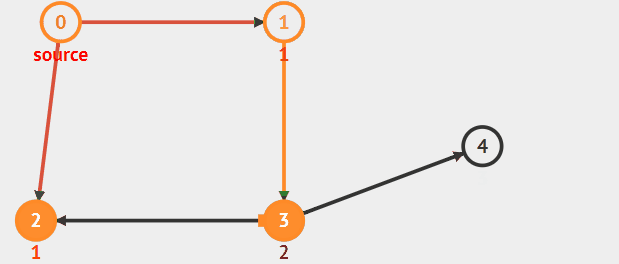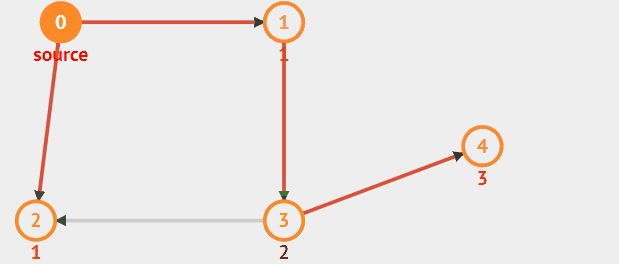
广度优先搜索的策略是:
从起始点开始遍历其邻接的节点,由此向外不断扩散。
从图中某顶点v出发,在访问了v之后依次访问v的各个未曾访问过的邻接点,
然后分别从这些邻接点出发依次访问它们的邻接点,
并使得“先被访问的顶点的邻接点先于后被访问的顶点的邻接点被访问,
直至图中所有已被访问的顶点的邻接点都被访问到。如果此时图中尚有顶点未被访问,
则需要另选一个未曾被访问过的顶点作为新的起始点,
重复上述过程,直至图中所有顶点都被访问到为止。
基本代码格式:
BFS() { //输入起始点; //初始化所有顶点标记为未遍历; //初始化一个队列queue并将起始点放入队列; while(queue不为空) { //从队列中删除一个顶点s并标记为已遍历; //将s邻接的所有还没遍历的点加入队列; } }
深度优先遍历的策略是:
从一个顶点v出发,首先将v标记为已遍历的顶点,
然后选择一个邻接于v的尚未遍历的顶点u,如果u不存在,
本次搜素终止。如果u存在,那么从u又开始一次DFS。
如此循环直到不存在这样的顶点。

基本代码模板:
DFS(顶点v) { //标记v为已遍历; for(对于每一个邻接v且未标记遍历的点u) DFS(u); }