比赛简介:
任务1:推荐最佳交通方式
任务描述:给定用户的一些信息,预测用户使用何种最佳交通方式由O(起点)到D(终点)
数据描述:

profiles.csv:
属性pid:用户的ID;
属性p0~p65:用户的个人信息(如身高,年龄,职业等)

训练集(2018.10.1~2018.11.30两个月的数据):
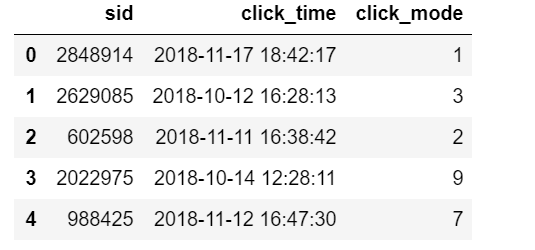
train_clicks.csv:
属性sid:用户的会话ID,如用户登陆一个app去使用就会有一个会话ID(可以百度了解);
属性click_time: 用户点击某种方案的时间;
属性click_mode:用户选择了某种出行方式(****这是训练集的label标签****)
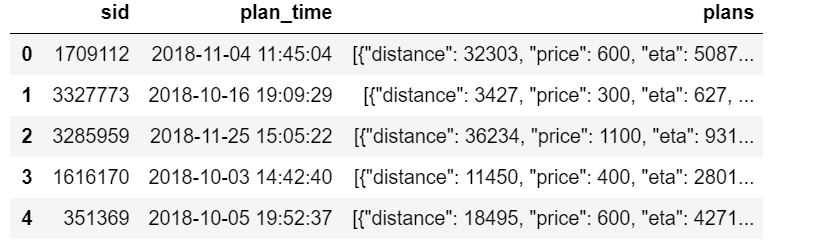
train_plans.csv:
属性sid:用户的会话ID,如用户登陆一个app去使用就会有一个会话ID(可以百度了解);
属性plan_time:APP显示出提供的可选方案的时间;
属性plans:这个信息是基于百度地图推荐的方案(包括距离,需要的时间,价格,交通方式),注:交通方式可能是某些组合,如taxi-bus
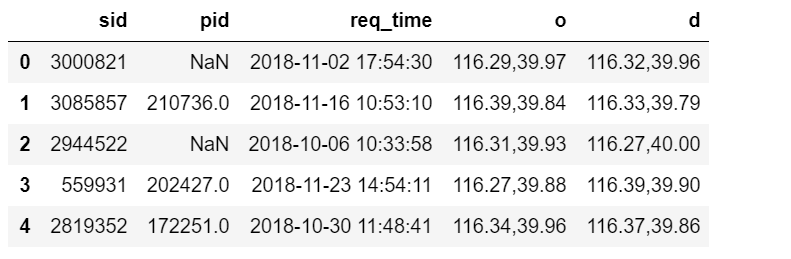
train_queries.csv:
属性sid:用户的会话ID,如用户登陆一个app去使用就会有一个会话ID(可以百度了解);
属性pid:用户的ID;
属性req_time:和plan_time几乎一样,用户查询的时间(并不是完全一样的,有的有一些时间差,猜测可能是手机的网速等问题);
属性o:起点的经纬度;
属性d:终点的经纬度
测试集(2018.12.1~2018.12.7七天的数据):
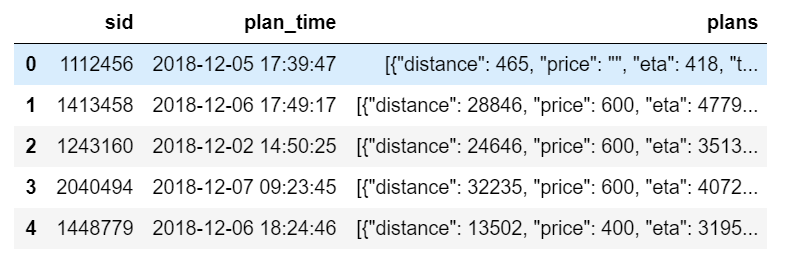
test_plans.csv:
属性sid:用户的会话ID,如用户登陆一个app去使用就会有一个会话ID(可以百度了解);
属性plan_time:用户准备查询如何去目的点的时间;
属性plans:这个信息是基于百度地图推荐的方案(包括距离,需要的时间,价格,交通方式),注:交通方式可能是某些组合,如taxi-bus
test_queries.csv:
属性sid:用户的会话ID,如用户登陆一个app去使用就会有一个会话ID(可以百度了解);
属性pid:用户的ID;
属性req_time:和plan_time几乎一样,用户查询的时间(并不是完全一样的,有的有一些时间差,猜测可能是手机的网速等问题);
属性o:起点的经纬度;
属性d:终点的经纬度
任务就是根据训练集的数据来训练模型,然后将测试集的特征放入模型,预测每个用户出行的交通选择方式(即训练集中的click_mode属性)
开源代码如下:
2.1 工具包导入
import numpy as np
import pandas as pd
import lightgbm as lgb
import os
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
import warnings
warnings.filterwarnings("ignore")
from tqdm import tqdm
import json
from sklearn.metrics import f1_score
from sklearn.model_selection import StratifiedKFold
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.decomposition import TruncatedSVD
from itertools import product
import ast
2.2 数据读取
path = 'E:/data/data_set_phase1/'
train_queries = pd.read_csv(path + 'train_queries.csv', parse_dates=['req_time'])
train_plans = pd.read_csv(path + 'train_plans.csv', parse_dates=['plan_time'])
train_clicks = pd.read_csv(path + 'train_clicks.csv')
profiles = pd.read_csv(path + 'profiles.csv')
test_queries = pd.read_csv(path + 'test_queries.csv', parse_dates=['req_time'])
test_plans = pd.read_csv(path + 'test_plans.csv', parse_dates=['plan_time'])
3 特征工程
-
此处我们对所有表格进行合并,这样方便提取表格之间的交互特征,注意因为初赛的数据相对较少,所以我们才合在一起,不然尽量不要做,这样会给机器的内存带来非常大的负担.
3.1 数据集合并
train = train_queries.merge(train_plans, 'left', ['sid'])
test = test_queries.merge(test_plans, 'left', ['sid'])
train = train.merge(train_clicks, 'left', ['sid'])
train['click_mode'] = train['click_mode'].fillna(0).astype(int)
data = pd.concat([train, test], ignore_index=True)
data = data.merge(profiles, 'left', ['pid'])
3.2 od(经纬度)特征
-
因为经纬度是组合字符串特征,此处我们对其进行还原,因为o,d本身是有相对大小关系的,我们不再对其进行编码。
data['o_lng'] = data['o'].apply(lambda x: float(x.split(',')[0]))
data['o_lat'] = data['o'].apply(lambda x: float(x.split(',')[1]))
data['d_lng'] = data['d'].apply(lambda x: float(x.split(',')[0]))
data['d_lat'] = data['d'].apply(lambda x: float(x.split(',')[1]))
3.3 plan_time & req_time特征
3.3.1 原始特征
时间信息会影响我们的决定,比如大晚上从A地到B地其实很多人是不会选择步行的,更多的会选择打车之类的,因为太黑了,怕迷路等;而如果是早高峰,而且离公司就几公里的情况, 那么一般就不会打车,因为特别会容易堵车,这个时候大家更喜欢骑自行车.
-
此处我们提取weekday来标志是周几; hour来标志是当日几点.
time_feature = []
for i in ['req_time']:
data[i + '_hour'] = data[i].dt.hour
data[i + '_weekday'] = data[i].dt.weekday
time_feature.append(i + '_hour')
time_feature.append(i + '_weekday')
3.3.2 plan_time & req_time差值特征
我们做EDA的时候发现plan_time和req_time并不是完全一样的,有的有一些时间差,我们猜测可能是手机的网速等问题,所以我们做差值来标志用户的手机信号等信息.
data['time_diff'] = data['plan_time'].astype(int) - data['req_time'].astype(int)
time_feature.append('time_diff')
3.4 plans特征
plans这个数据集包含的信息非常多,因为这个信息是基于百度地图推荐的。所以毫无疑问是本次比赛的关键之一,我们对其进行展开并提取相关的特征。
此处我发现kdd已经有大佬开源了plans的特征提取关键代码,我感觉很不错,此处我便直接引用,至于其他的特征欢迎去作者的Github下载.
此处关于plans的特征主要可以归纳为如下的特征:
-
百度地图推荐的距离的统计值(mean,min,max,std)
-
各种交通方式的价格的统计值(mean,min,max,std)
-
各种交通方式的时间的统计值(mean,min,max,std)
-
一些其他的特征,最大距离的交通方式,最高价格的交通方式,最短时间的交通方式等.
data['plans_json'] = data['plans'].fillna('[]').apply(lambda x: json.loads(x))
def gen_plan_feas(data):
n = data.shape[0]
mode_list_feas = np.zeros((n, 12))
max_dist, min_dist, mean_dist, std_dist = np.zeros((n,)), np.zeros((n,)), np.zeros((n,)), np.zeros((n,))
max_price, min_price, mean_price, std_price = np.zeros((n,)), np.zeros((n,)), np.zeros((n,)), np.zeros((n,))
max_eta, min_eta, mean_eta, std_eta = np.zeros((n,)), np.zeros((n,)), np.zeros((n,)), np.zeros((n,))
min_dist_mode, max_dist_mode, min_price_mode, max_price_mode, min_eta_mode, max_eta_mode, first_mode =
np.zeros((n,)), np.zeros((n,)), np.zeros((n,)), np.zeros((n,)), np.zeros((n,)), np.zeros((n,)), np.zeros((n,))
mode_texts = []
for i, plan in tqdm(enumerate(data['plans_json'].values)):
if len(plan) == 0:
cur_plan_list = []
else:
cur_plan_list = plan
if len(cur_plan_list) == 0:
mode_list_feas[i, 0] = 1
first_mode[i] = 0
max_dist[i] = -1
min_dist[i] = -1
mean_dist[i] = -1
std_dist[i] = -1
max_price[i] = -1
min_price[i] = -1
mean_price[i] = -1
std_price[i] = -1
max_eta[i] = -1
min_eta[i] = -1
mean_eta[i] = -1
std_eta[i] = -1
min_dist_mode[i] = -1
max_dist_mode[i] = -1
min_price_mode[i] = -1
max_price_mode[i] = -1
min_eta_mode[i] = -1
max_eta_mode[i] = -1
mode_texts.append('word_null')
else:
distance_list = []
price_list = []
eta_list = []
mode_list = []
for tmp_dit in cur_plan_list:
distance_list.append(int(tmp_dit['distance']))
if tmp_dit['price'] == '':
price_list.append(0)
else:
price_list.append(int(tmp_dit['price']))