1,.为什么要用激活函数?
答:如果不用激励函数,每一层输出都是上层输入的线性函数,无论神经网络有多少层,输出都是输入的线性组合。
如果使用的话,激活函数给神经元引入了非线性因素,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以应用到众多的非线性模型中。
2.常用的激活函数以及它们的优缺点?
答:
1)sigmoid函数:目前几乎被淘汰

sigmoid函数也叫 Logistic 函数,用于隐层神经元输出,取值范围为(0,1),它可以将一个实数映射到(0,1)的区间,可以用来做二分类。在特征相差比较复杂或是相差不是特别大时效果比较好。
缺点:
a.饱和时梯度值非常小。由于BP算法反向传播的时候后层的梯度是以乘性方式传递到前层,因此当层数比较多的时候,传到前层的梯度就会非常小,网络权值得不到有效的更新,即梯度耗散。如果该层的权值初始化使得f(x) 处于饱和状态时,网络基本上权值无法更新。
b.激活函数计算量大,反向传播求误差梯度时,求导涉及除法
2)tanh函数:
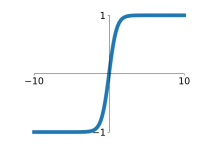
也称为双切正切函数,取值范围为[-1,1],tanh在特征相差明显时的效果会很好,在循环过程中会不断扩大特征效果。与 sigmoid 的区别是,tanh 是 0 均值的,因此实际应用中 tanh 会比 sigmoid 更好。
缺点:仍然具有饱和的问题
3)relu函数:

Alex在2012年提出的一种新的激活函数。该函数的提出很大程度的解决了BP算法在优化深层神经网络时的梯度耗散问题
优点:
a.x>0 时,梯度恒为1,无梯度耗散问题,收敛快
b.增大了网络的稀疏性。当x<0 时,该层的输出为0,训练完成后为0的神经元越多,稀疏性越大,提取出来的特征就约具有代表性,泛化能力越强。即得到同样的效果,真正起作用的神经元越少,网络的泛化性能越好
c.运算量小而且用 ReLU 得到的 SGD 的收敛速度会比 sigmoid/tanh 快很多
缺点:
训练的时候很”脆弱”,很容易就”die”了例如,一个非常大的梯度流过一个 ReLU 神经元,更新过参数之后,这个神经元再也不会对任何数据有激活现象了,那么这个神经元的梯度就永远都会是 0.如果 learning rate 很大,
那么很有可能网络中的 40% 的神经元都”dead”了
3)Leaky ReLU函数:
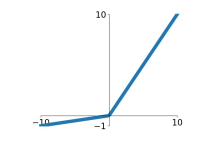
改善了ReLU的死亡特性,但是也同时损失了一部分稀疏性,且增加了一个超参数,目前来说其好处不太明确
总结:真实使用的时候最常用的还是ReLU函数,注意学习率的设置以及死亡节点所占的比例即可,对于输出层,应当尽量选择适合因变量分布的激活函数:
1.对于只有0,1取值的双值因变量,logistic函数是一个比较好的选择;
2.对于有多个取值的离散因变量,比如0到9数字识别,softmax激活函数是logistic激活函数的自然衍生;
3.对于有限值域的连续因变量logistic或者tanh激活函数都可以用,但是需要将因变量的值域伸缩到logistic或tanh对应的值域中
4.如果因变量取值为正,但是没有上限,那么指数函数是一个较好的选择
5.如果因变量没有有限值域,或者虽然有限值域但是边界未知,那么最好采用线性函数作为激活函数
更详细的介绍,可以查看这篇博客