SpringCloud-Netflix(Usage of Eureka)
前面聊了Ribbon的使用,因为使用Ribbon带出了两个痛点,所以我们来聊聊Eureka,当他和Ribbon结合后,会解决一定的问题。并且本篇会聊聊它的使用,关于SpringCloud-Netflix系列的源码我会在聊完对他们的使用后,然后再和大家进行剖析。
Outline of Eureka
前面说没有Eureka,Ribbon单独使用造成的痛点是【微服务目标地址的维护、监测微服务的健康状态】,那Eureka做的事情其实就是:
- 服务地址的统一维护
- 服务提供者的动态上下线感知
要做到上面的两点,Eureka实际上做的事情是非常多的,因为
- 我们服务调用者需要知道哪些微服务的地址是有用的,那就有两种方式解决
- 【pull】:服务调用者主动去eureka上获取可用的微服务地址
- 【push】:eureka主动推送微服务地址给服务调用方,那就需要和这些服务调用方建立心跳,及时的把最新的微服务地址传递给服务调用方
- eureka需要知道哪些微服务是存活的,那就需要和这些微服务建立心跳
如果Eureka做到了上面的这些,就可以解决Ribbon带来的痛点->Ribbon从Eureka上获取服务地址
- 自己就不用手动维护地址,解决了目标地址的维护问题
- Eureka对这些微服务的健康状态进行监听,解决了监测微服务的健康状态
Usage of Eureka
Eureka我们都知道它是一个注册中心,和其他的注册中心不同的是,他也是一个项目,所以我们需要创建一个项目,我们在创建项目的时候,把eureka相关的包勾选上即可。
因为他默认的端口是8761,所在application中修改他的端口为8761,上面说了他是一个项目,所以我们要做还有把他自己注册到自己上面,否则会报错。
 View Codespring.application.name=eureka-server server.port=8761 #自己注册自己 eureka.client.service-url.defaultZone=http://localhost:8761/eureka
View Codespring.application.name=eureka-server server.port=8761 #自己注册自己 eureka.client.service-url.defaultZone=http://localhost:8761/eureka并且在springBoot的启动类上加上@EnableEurekaServer,后面的源码,我会带大家聊这个。启动之后,我们发现,eureka已经把自己注册上去了。
并且在想注册到eureka的微服务中加上eureka的client的pom
View Code<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-eureka-client</artifactId> </dependency>同时每个微服务的application中指定一下默认eureka server
View Codeeureka.client.service-url.defaultZone=http://localhost:8761/eureka这样,我们的相关的微服务在启动的时候就注册到了eureka中
另外我们需要加上actuator对微服务进行健康检查
View Code<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-actuator</artifactId> </dependency>这个时候,我们就可以删除在单独使用Ribbon的时候在application中维护的各个微服务地址,Ribbon会从Eureka上获取地址。



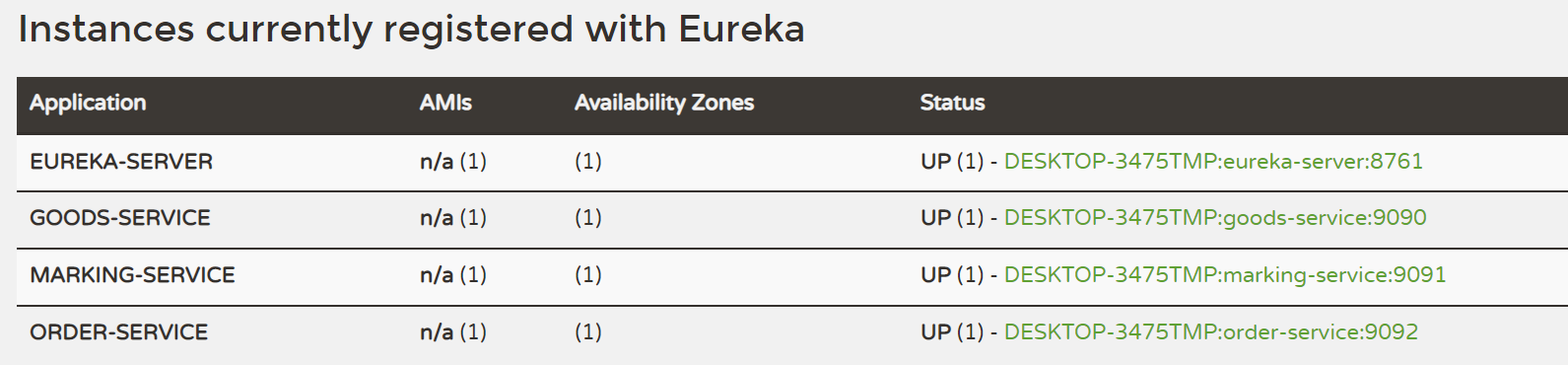
Framework of Eureka
Eureka满足了cap理论中的ap的特性,也就是可用性,和分区容错性,他的集群是一个去中心化的集群节点。因为如果有中心节点,那就会造成短时间内不可用的状态,就像之前的zk一样。引入集群后,他的流程如下:
- 服务提供者启动的时候把自己注册到eureka上,然后建立心跳包。
- 客户端通过定时的轮询去获取eureka上的服务地址。
- 如果服务提供者的请求落到了某个eureka节点上的话,eureka就会把数据同步到其他的eureka节点上
【搭建集群】:实际上就是搭建多个相同的eureka项目,然后把彼此注册到对方中,比如我们现在有一个8761的节点,那就在application中维护8762的信息,反之亦然。eureka因为不像zk那样,所以只要保证高可用,无论部署几个节点。
View Codespring.application.name=eureka-server-replica server.port=8762 eureka.client.service-url.defaultZone=http://localhost:8761/eurekaeureka的数据同步流程(基于http协议进行api接口之间的通信):
服务提供者随机调用eureka的服务注册/下线api,在eureka底层提供了一个数据副本同步的机制,他会进行多个节点之间的同步
- 当服务提供这随机调用一个eureka的api,比如说默认到eureka1上,eureka1会首先更新自己节点上的数据,
- 然后它遍历所有的eureka实例,
- 最后逐一发送数据同步的请求
问题:那么既然eureka集群没有中心节点,它是如何避免死循环同步问题呢?(比如有一个服务提供者上线,并且发送消息到eureka1这个时候eureka1更新了它本地,并且发送一个他同步数据给了eureka2,这个时候eureka2收到了同步消息,更新了自己的本地,并且把这个数据也同步给了eureka1,这样就造成了死循环)
解决:这个通过加时间戳解决就可以了,判断最新就行,这个和zk的zxid一样,后面源码我会和大家聊。
relevant questions
【eureka心跳续约机制的流程】
- 服务提供者每隔30s会发送一次心跳请求给eureka-server,在eureka上维护了所有服务提供者的实例,当一次心跳请求过来的时候,他会更新发送心跳的服务的时间。在eureka上,它会每隔60s去检查所有的实例的过期时间,如果维护的某个服务提供者的上一次的心跳时间距离当前时间大于90s就认为服务提供者过期,并且会剔除它(但是eureka如果开启了自我保护机制是不会剔除)
【eureka自我保护机制】
- 上面说到当某个服务提供者的心跳时间距离当前的时间大于90s那就被认为已经宕机,然而如果开启了自我保护机制那就不会剔除。这是因为有的时候因为网络的问题,eureka通过心跳判定某个服务提供者可能已经宕机,所以把一个健康的因为网络问题的服务提供者给剔除了。为了规避这种原因,eureka会默认开启这种机制【eureka.server.enable-self-preservation=true/false】.
【什么时候会打开自我保护的开关】:
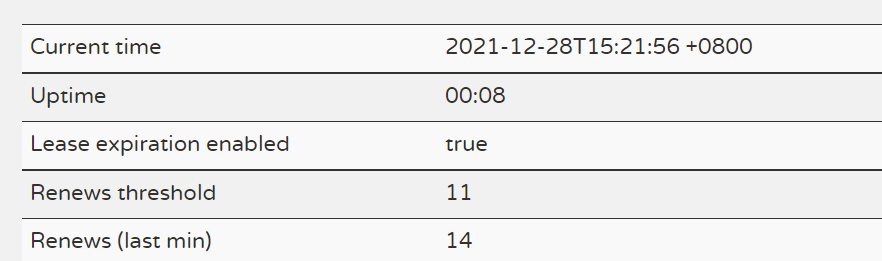
- 如果超过85%的客户端节点,都没有发起正常的心跳(renew),那么eureka就认为客户端和服务端出现了网络故障,eureka就会进入自我保护状态。当然我们可以修改【eureka.server.renewal-percent-threshold = 0.85】。那具体表现为Renews (last min) < Renews threshold。这两个数值我们都可以在eureka的dashboard上看见。
【Renews threshold】:Eureka Server 期望每分钟收到客户端实例续约的总数。这个数字15分钟更新一次。 (服务总数*每分钟的续约数量(60s/客户端续约间隔时间)* 0.85->现在我们的服务总数为为7个 那就等于【7*2*0.85=11.9(11)】)
【Renews (last min)】:Eureka Server 最后 1 分钟收到客户端实例续约的总数。
注:这两个参数我们可以在eureka的dashboard中看见。
【模拟自我保护机制】
通过配置,让它在5s之内,保证所有的服务都成功。这显然是不可能的,所以我们这样就可以模拟。
View Codeeureka.server.wait-time-in-ms-when-sync-empty=5000 eureka.server.renewal-percent-threshold=1
【Eureka多级缓存机制】:
他的缓存只是为了解决读写服务提供者信息的冲突问题,从而使用多个容器作为读写分离,他的服务提供者的信息是存储在ConcurrentHashMap<String, Map<String, Lease<InstanceInfo>>>中的。下面为缓存流程:
- 当服务注册或者服务下线,这些服务提供者的信息会更新到ConcurrentHashMap,然后同时更新到readWriteCacheHahMap中。
- 当查询这些服务提供者信息的时候,
- 他不会直接读取ConcurrentHashMap,而是从只读缓存中获取数据(readOnlyCacheHashMap)。
- 这个只读缓存(readOnlyCacheHashMap)的信息是从一个readWriteCacheHahMap的容器中同步过来的。
- readWriteCacheHahMap中的数据是,当ConcurrentHashMap中的信息变更后,就会马上同步到readWriteCacheHahMap中
- readOnlyCacheHashMap会每隔30s从readWriteCacheHahMap中获取数据,readWriteCacheHahMap中的数据每隔180s会过期,过期后会从ConcurrentHashMap中重新同步。