一. 列表查询
"""
要求:从列表中查询指定元素
输入:列表,待查询元素
输出:元素下标或未查找到元素
方法:
1. 顺序查找
2. 二分查找(列表为升序)
"""
# 顺序查找 def linear_search(data_set, value): for i in range(len(data_set)): if data_set[i] == value: return i return print(linear_search([12, 3, 4, 5, 3, 6, 7], 3))
# 二分查找 def bin_search(data_set, value): left = 0 right = len(data_set) - 1 while left < right: mid = (left + right) // 2 if data_set[mid] == value: return mid elif data_set[mid] > value: right = mid - 1 elif data_set[mid] < value: left = mid + 1 print(bin_search(sorted([12, 3, 4, 5, 3, 6, 7]), 3))
# 二分查找(递归版) def bin_search_rec(data_set, value, left, right): if left < right: mid = (left + right) // 2 if data_set[mid] == value: return mid elif data_set[mid] > value: return bin_search_rec(data_set, value, left, mid - 1) elif data_set[mid] < value: return bin_search_rec(data_set, value, mid + 1, right) print(bin_search_rec(sorted([12, 3, 4, 5, 3, 6, 7]), 3, 0, 6))
二、列表排序
参考博客:http://blog.csdn.net/mrlevo520/article/details/77829204
"""
方法:
1. 冒泡排序 (稳定)
2. 选择排序
3. 插入排序 (稳定)
4. 快速排序
5. 堆排序
6. 归并排序 (稳定)
7. 希尔排序
"""


# #################################### 计时装饰器 #################################### import time def cal_time(func): def wrapper(*args, **kwargs): t1 = time.time() result = func(*args, **kwargs) t2 = time.time() print("%s running time: %s secs." % (func.__name__, t2 - t1)) return result return wrapper
# 1. 冒泡排序
# 原理:从索引为0的位置开始,比较索引0和1的值的大小,索引0的值大,则互换位置。再比较索引1和2的值,一趟下来,最大值换到末尾,再从头比较。
# i: 趟
# j: 指针位置
# 时间复杂度:O(n2)
def bubble_sort(li): for i in range(len(li) - 1): for j in range(len(li) - 1 - i): if li[j] > li[j + 1]: li[j], li[j + 1] = li[j + 1], li[j] li = [12, 3, 4, 5, 3, 6, 7] bubble_sort(li) print(li)
# 冒泡优化
# 执行一趟没有交换,则说明列表有序,结束排序
def bubble_sort_op(li): for i in range(len(li) - 1): exchange = False for j in range(len(li) - 1 - i): if li[j] > li[j + 1]: li[j], li[j + 1] = li[j + 1], li[j] exchange = True if not exchange: return

# 2. 选择排序
# 原理:从索引位置0开始,与位置1的值比较,记录较小值的索引,再比较1和2的值,一趟下来讲位置0和最小索引的值交换。下一趟从索引1开始比较。
# 关键点:无序区,最小值索引
# i:趟
# j:指针
# 时间复杂度:O(n2)
def select_sort(li): for i in range(len(li) - 1): min_index = i for j in range(i + 1, len(li)): if li[j] < li[min_index]: min_index = j if min_index != i: li[i], li[min_index] = li[min_index], li[i]
# 写法二:注意与冒泡排序的区分,趟数区到最后一位。 def select_sort(li): for i in range(len(li)): for j in range(len(li) - i): if li[i] > li[i + j]: li[i], li[i + j] = li[i + j], li[i] li = [12, 3, 4, 5, 3, 6, 7] select_sort(li) print(li)

# 3. 插入排序
# 原理:是每一步都将一个待排数据按其大小插入到已经排序的数据中的适当位置,直到全部插入完毕。
# 从索引1开始,取值存为一个临时值与有序区的元素比较,遇到第一个比临时值大的值,此值的下表为j,将临时值插入到j的位置,其后面的值依次后移。
# 关键点:默认序列中的第0个元素是有序的,插入值后,pop出原来的值
# i:趟
# j:指针
# 时间复杂度:O(n2)
def insert_sort(li): for i in range(1, len(li)): for j in range(i): if li[i] < li[j]: li.insert(j, li[i]) # 首先碰到第一个比自己大的数字,赶紧刹车,停在那,所以选择insert li.pop(i + 1) # 因为前面的insert操作,所以后面位数+1,这个位置的数已经insert到前面去了,所以pop弹出 break li = [12, 3, 4, 5, 3, 6, 7] insert_sort(li) print(li)

# 4. 快速排序
# 原理:从数列中取出一个值,区分过程,将比这个值大的放在它的右边,将比这个值小的放在它的左边,再最左右两个区域重复这个过程,直到各个区域只有一个数。
# 时间复杂度:O(nlogn)
# 最坏的情况:每次的取值为最大值或最小值,造成分区不均匀。性能解决插入排序,时间复杂度为O(n2)。
# pivot:枢
def quick_sort(li): if len(li) < 2: return li else: pivot = li[0] less = [i for i in li[1:] if i < pivot] greater = [j for j in li[1:] if j > pivot] return quick_sort(less) + [pivot] + quick_sort(greater) print(quick_sort([1, 5, 2, 6, 9, 3]))

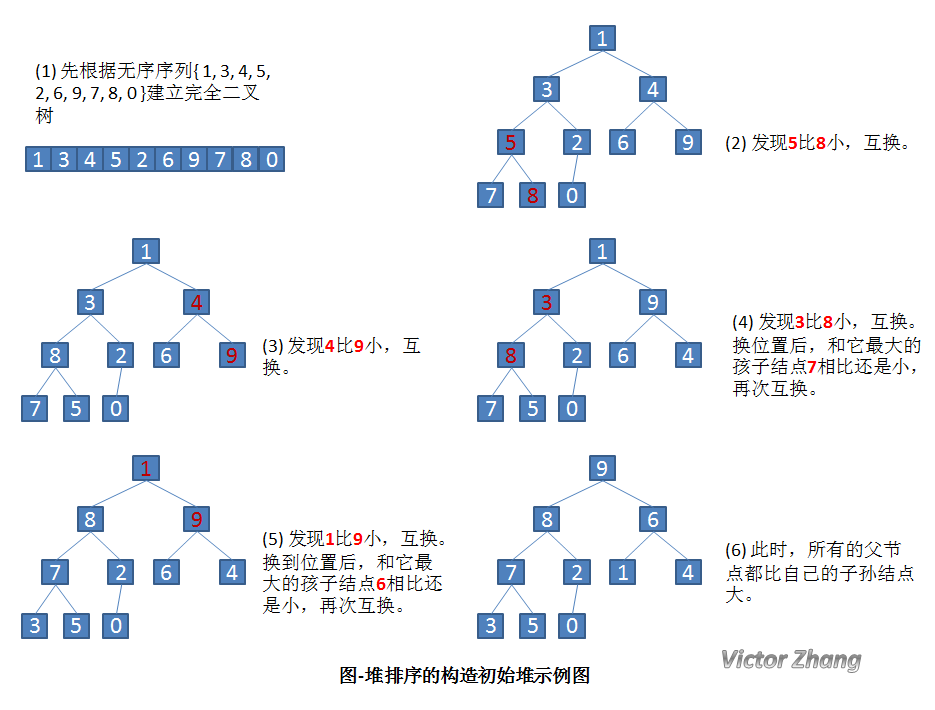
# 5. 堆排序
# 堆是一棵顺序存储的完全二叉树。
# 其中每个结点的关键字都不大于其孩子结点的关键字,这样的堆称为小根堆。
# 其中每个结点的关键字都不小于其孩子结点的关键字,这样的堆称为大根堆。
# 原理:
# 1. 多次调整建立堆,得到堆顶为最大元素
# 2. 取出堆顶,将最后一个元素放到堆顶,经过一次调整重新变成堆。
# 3. 重复建堆,取堆顶元素。
# 时间复杂度:O(nlogn)
def sift(li, left, right): i = left j = 2 * i + 1 tmp = li[i] while j <= right: if j + 1 <= right and li[j] < li[j + 1]: j = j + 1 if tmp < li[j]: li[i] = li[j] i = j j = 2 * i + 1 else: break li[i] = tmp def heap_sort(li): n = len(li) for i in range(n // 2 - 1, -1, -1): # 建立堆 sift(li, i, n - 1) for i in range(n - 1, -1, -1): # 挨个出数 li[0], li[i] = li[i], li[0] sift(li, 0, i - 1) li = [6, 8, 1, 9, 3, 0, 7, 2, 4, 5] heap_sort(li) print(li)

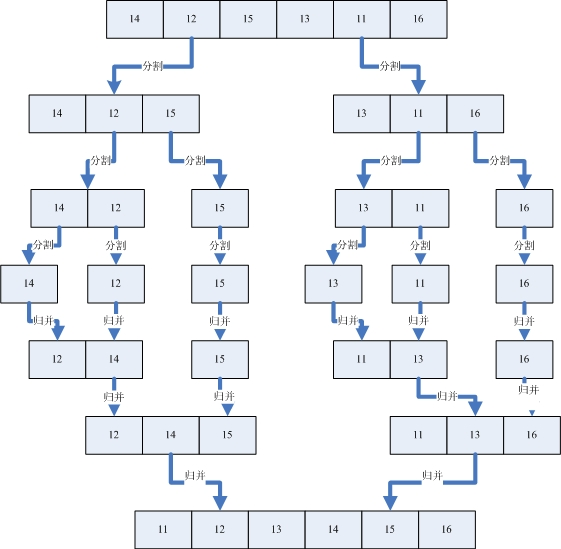
# 6.归并排序
# 原理:用分割的方法将序列分割成一个个已经排好序的序列,再利用归并的方法将一个个子序列合并成排序好的序列。
# 关键点:递归分解,归并
# 时间复杂度:O(nlogn)
def merge(left, right): result = [] while left and right: result.append(left.pop(0) if left[0] <= right[0] else right.pop(0)) while left: result.append(left.pop(0)) while right: result.append(right.pop(0)) # if left: # result.extend(left) # if right: # result.extend(right) return result def merge_sort(li): if len(li) <= 1: return li mid_index = len(li) // 2 left = merge_sort(li[:mid_index]) # 递归拆解的过程 right = merge_sort(li[mid_index:]) return merge(left, right) # 合并的过程 print(merge_sort([1, 5, 2, 6, 9, 3]))

# 一般情况下,就运行时间而言:
# 快速排序 < 归并排序 < 堆排序
# 三种排序算法的缺点:
# 快速排序:极端情况下排序效率低
# 归并排序:需要额外的内存开销
# 堆排序:在快的排序算法中相对较慢
# 7. 希尔排序
# 原理:一种分组插入排序算法。每次按照gap间隔的分组,对每组进行插入排序。
# 关键点:gap——间隙
# 时间复杂度:O((1+τ)n) ≈≈ O(1.3n)
def shell_sort(li): n = len(li) gap = n // 2 # 初始步长 while gap > 0: for i in range(gap, n): temp = li[i] # 每个步长进行插入排序 j = i - gap # 插入排序 while j >= 0 and li[j] > temp: li[j + gap] = li[j] j -= gap li[j + gap] = temp gap = gap // 2 # 得到新的步长 return li print(shell_sort([1, 5, 2, 6, 9, 3]))