概述
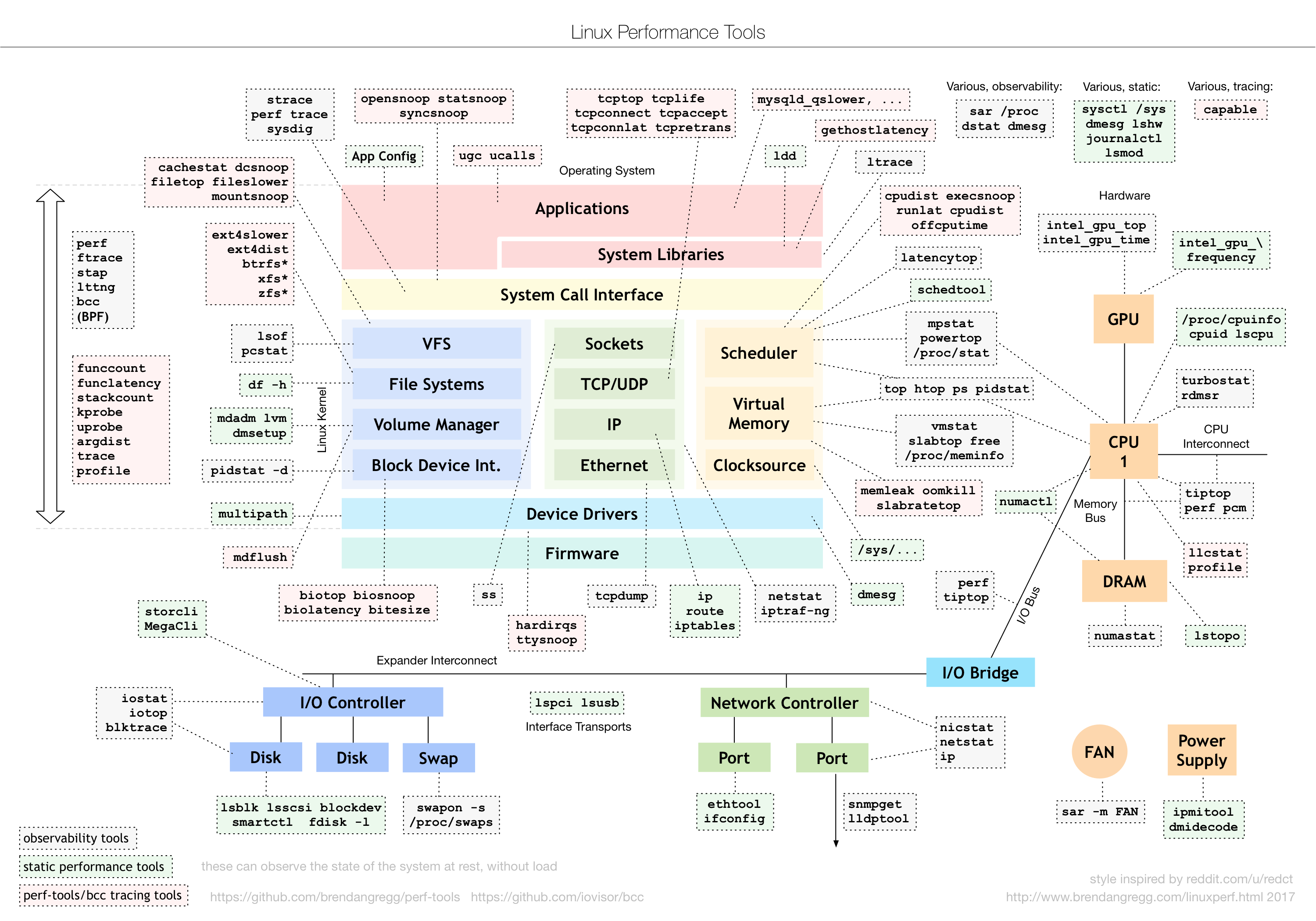
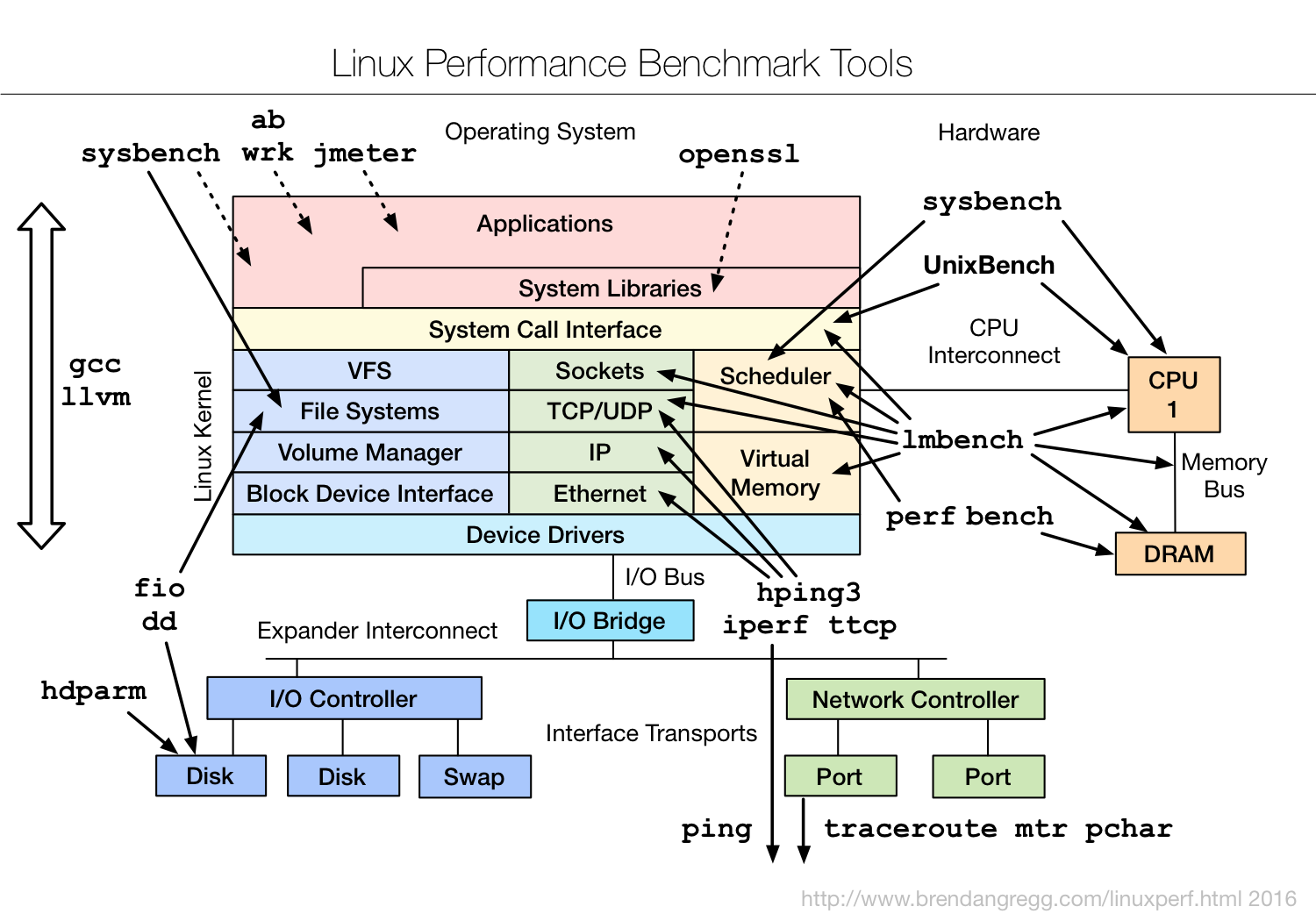
一个基于 Linux 操作系统的服务器运行的同时,也会表征出各种各样参数信息。通常来说运维人员、系统管理员会对这些数据会极为敏感,但是这些参数对于开发者来说也十分重要,尤其当你的程序非正常工作的时候,这些蛛丝马迹往往会帮助快速定位跟踪问题。这里只是一些简单的工具查看系统的相关参数,当然很多工具也是通过分析加工 /proc、/sys 下的数据来工作的,而那些更加细致、专业的性能监测和调优,可能还需要更加专业的工具(perf、systemtap 等)和技术才能完成哦。毕竟来说,系统性能监控本身就是个大学问。Linux 内核的各个子系统出发,汇总了对各个子系统进行性能分析时,你可以选择的工具。不过,虽然这个图是性能分析最好的参考资料之一,它其实还不够具体。比如,当你需要查看某个性能指标时,这张图里对应的子系统部分,可能有多个性能工具可供选择。但实际上,并非所有这些工具都适用,具体要用哪个,还需要你去查找每个工具的手册,对比分析做出选择。
形成认识框架认识框架(也就是知识大纲)非常重要,宏观上有了理解之后:1)才能有的放矢的深入细节,并能将繁杂多样的细节串联起来;2)在遇到问题的时候,才有能够正确的思考,有头绪、有方法、有步骤的调查问题、解决问题。下面这张图是最宏观的图片,从上往下是“应用->库->系统调用->内核->设备”,如果发现一个应用的性能特别不理想,可以按照这个顺序查找问题所在,即先查应用、再查依赖库、然后查系统、最后查硬件。
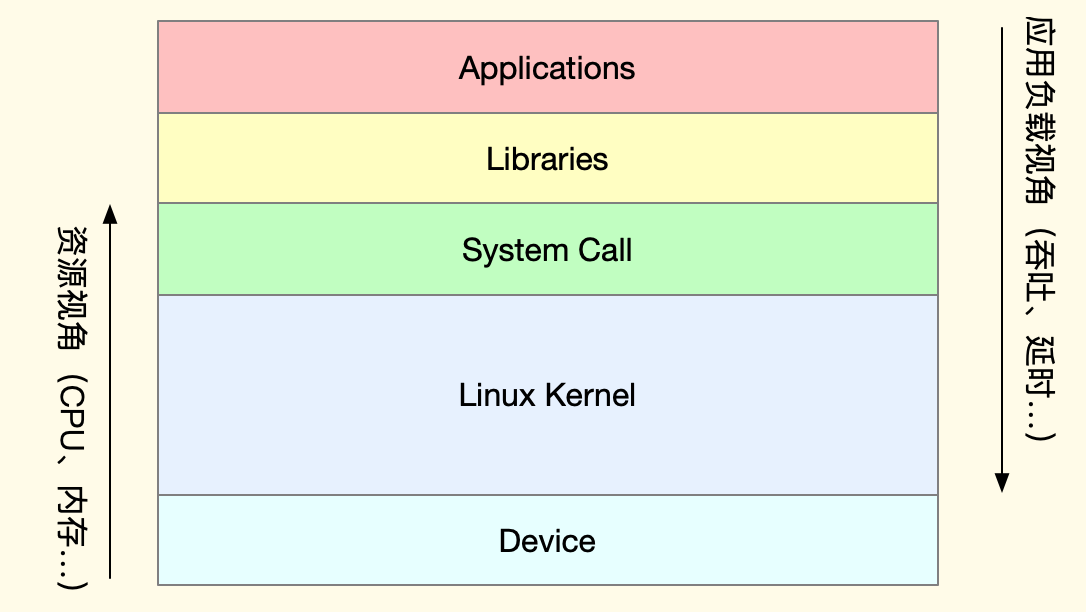
排查顺序
整体情况:
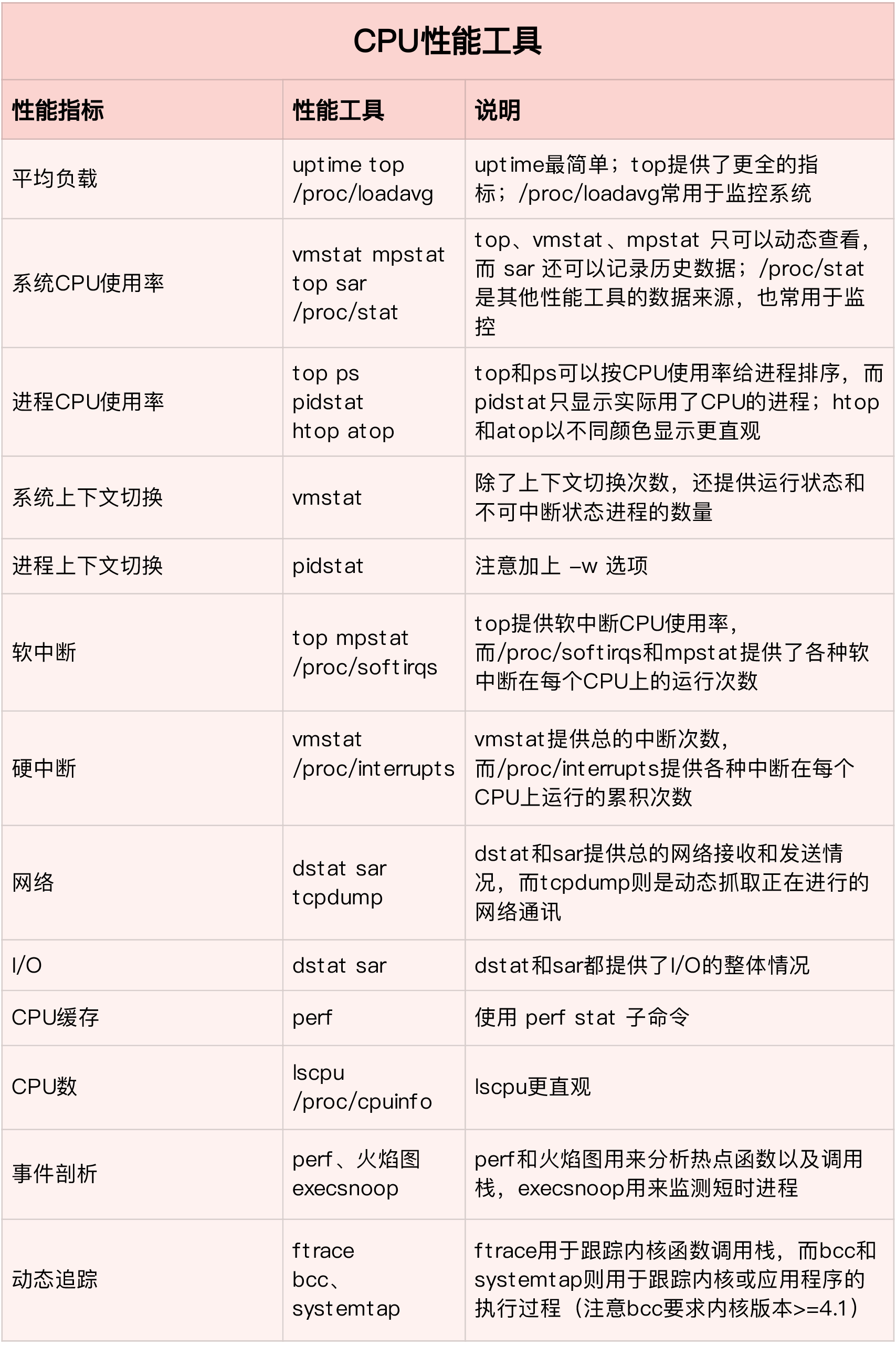
top/htop/atop命令查看进程/线程、CPU、内存使用情况,CPU使用情况;dstat 2查看CPU、磁盘IO、网络IO、换页、中断、切换,系统I/O状态;vmstat 2查看内存使用情况,内存状态;iostat -d -x 2查看所有磁盘的IO情况,系统I/O状态;iotop查看IO靠前的进程,系统的I/O状态;perf top查看占用CPU最多的函数,CPU使用情况;perf record -ag -- sleep 15;perf report查看CPU事件占比,CPU使用情况;sar -n DEV 2查看网卡的吞吐,网卡状态;/usr/share/bcc/tools/filetop -C查看每个文件的读写情况,系统的I/O状态;/usr/share/bcc/tools/opensnoop显示正在被打开的文件,系统的I/O状态;- mpstat -P ALL 1单核CPU是否被打爆;
- ps aux --sort=-%cpu 按CPU使用率排序,找出CPU消耗最多进程;
- ps -eo pid,comm,rss | awk '{m=$3/1e6;s["*"]+=m;s[$2]+=m} END{for (n in s) printf"%10.3f GB %s\n",s[n],n}' | sort -nr | head -20 统计前20内存占用;
- awk 'NF>3{s["*"]+=s[$1]=$3*$4/1e6} END{for (n in s) printf"%10.1f MB %s\n",s[n],n}' /proc/slabinfo | sort -nr | head -20 统计内核前20slab的占用;
进程分析,进程占用的资源:
pidstat 2 -p 进程号查看可疑进程CPU使用率变化情况;pidstat -w -p 进程号 2查看可疑进程的上下文切换情况;pidstat -d -p 进程号 2查看可疑进程的IO情况;lsof -p 进程号查看进程打开的文件;strace -f -T -tt -p 进程号显示进程发起的系统调用;
协议栈分析,连接/协议栈状态:
netstat -nat|awk '{print awk $NF}'|sort|uniq -c|sort -n查看连接状态分布;ss -ntp或者netstat -ntp查看连接队列;- netstat -nat|awk '{print awk $NF}'|sort|uniq -c|sort -n查看连接状态分布;
- ss -ntp或者netstat -ntp查看连接队列;
- netstat -s 查看协议栈情况;
方法论
RED方法:监控服务的请求数(Rate)、错误数(Errors)、响应时间(Duration)。Weave Cloud在监控微服务性能时提出的思路。
USE方法:监控系统资源的使用率(Utilization)、饱和度(Saturation)、错误数(Errors)。
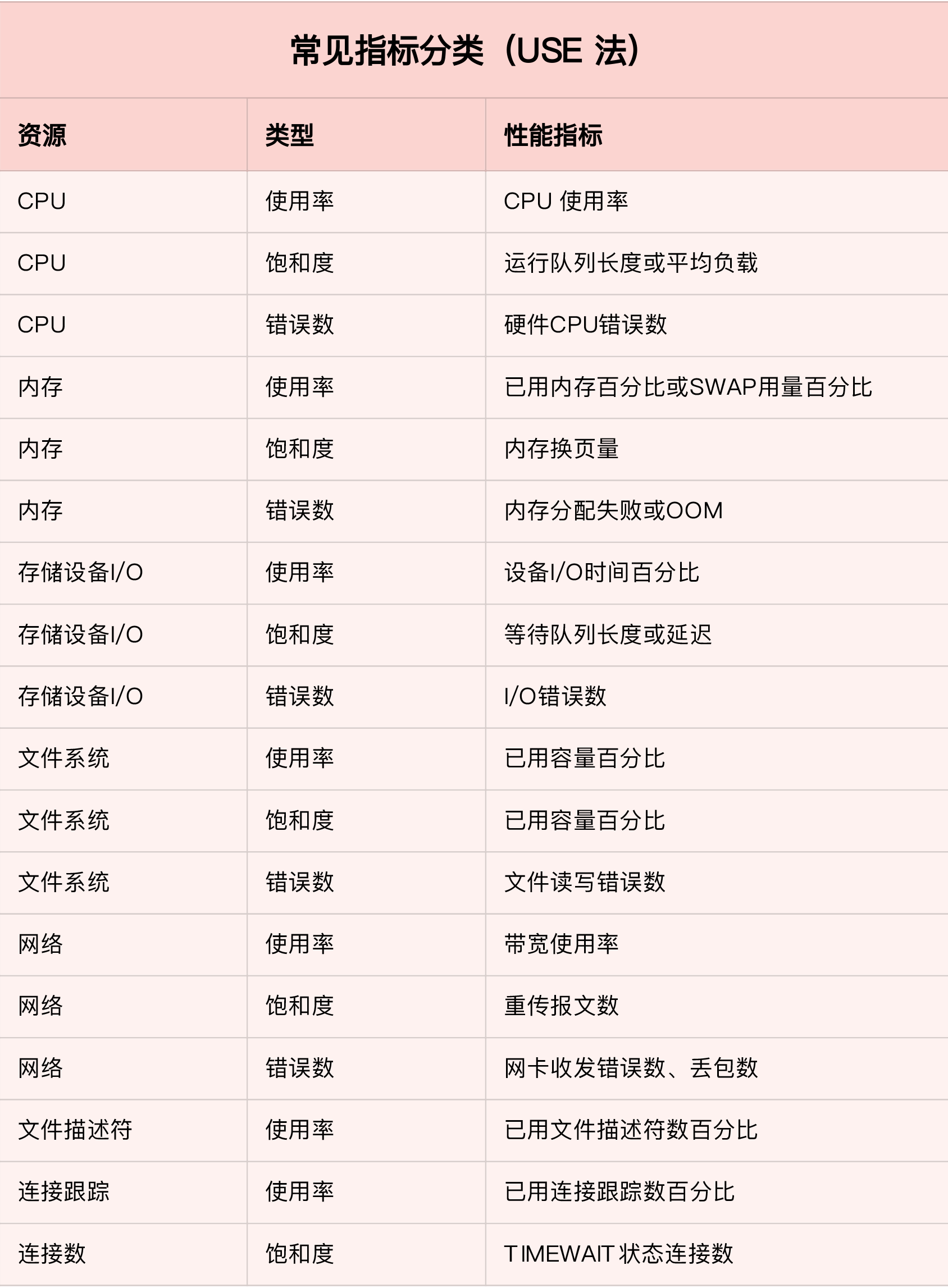
性能分析工具
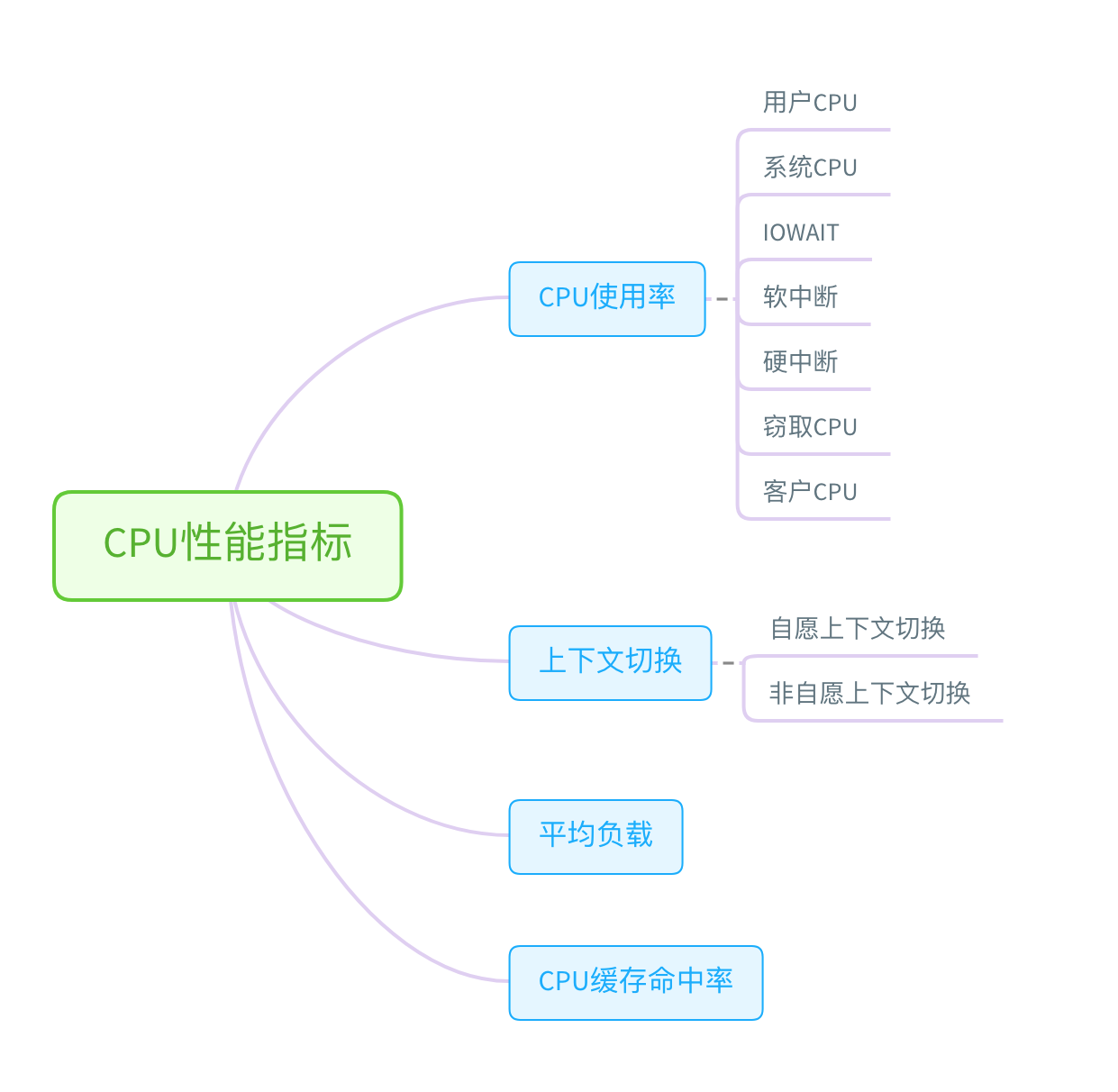
CPU分析思路
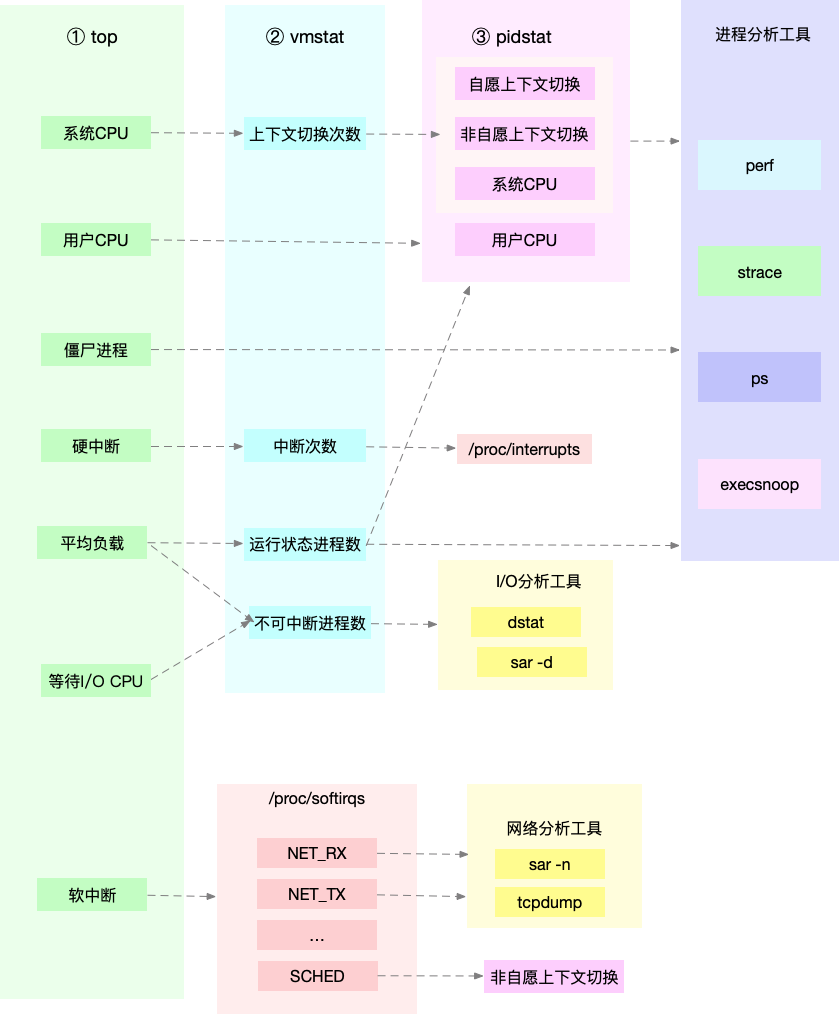
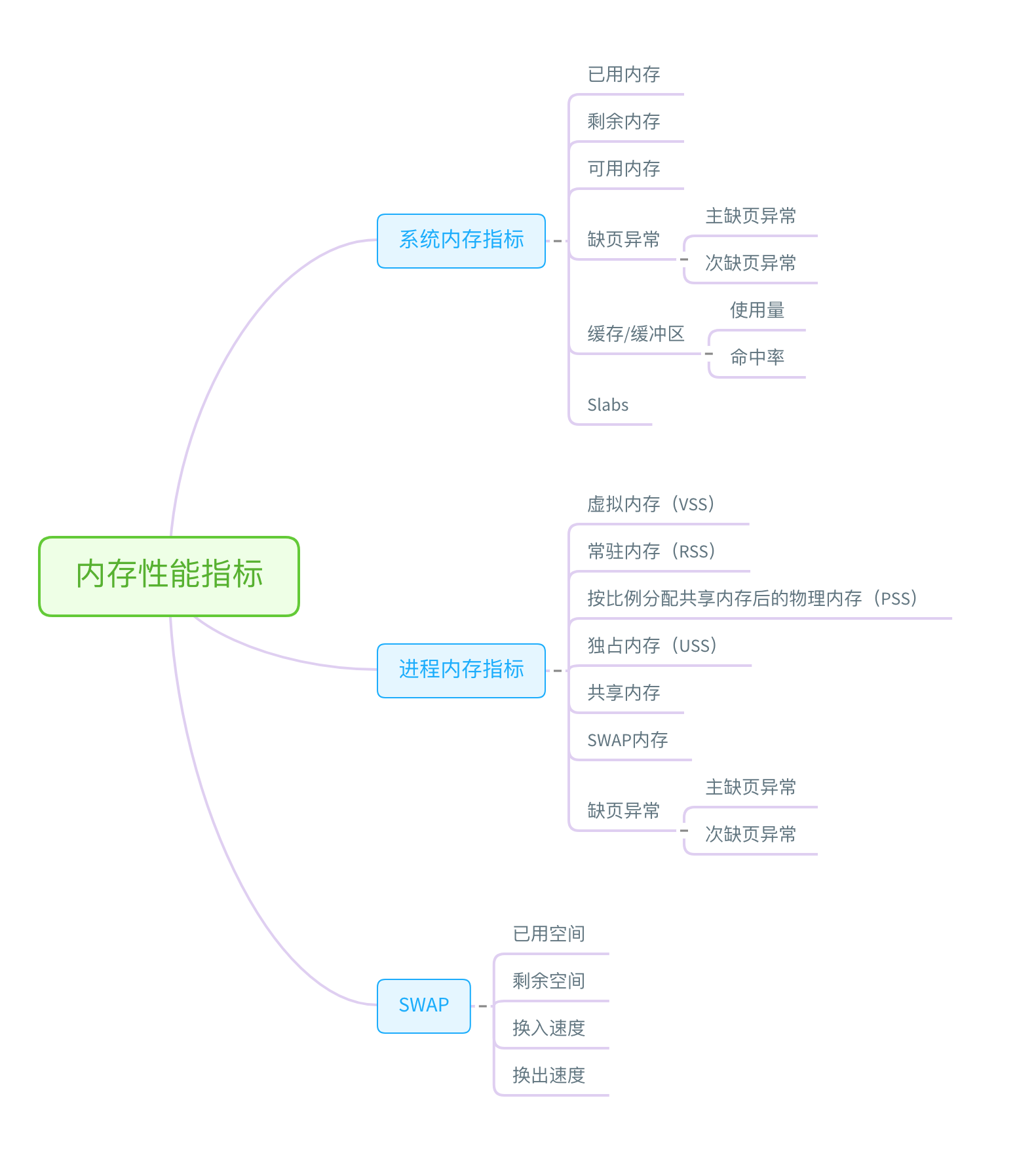
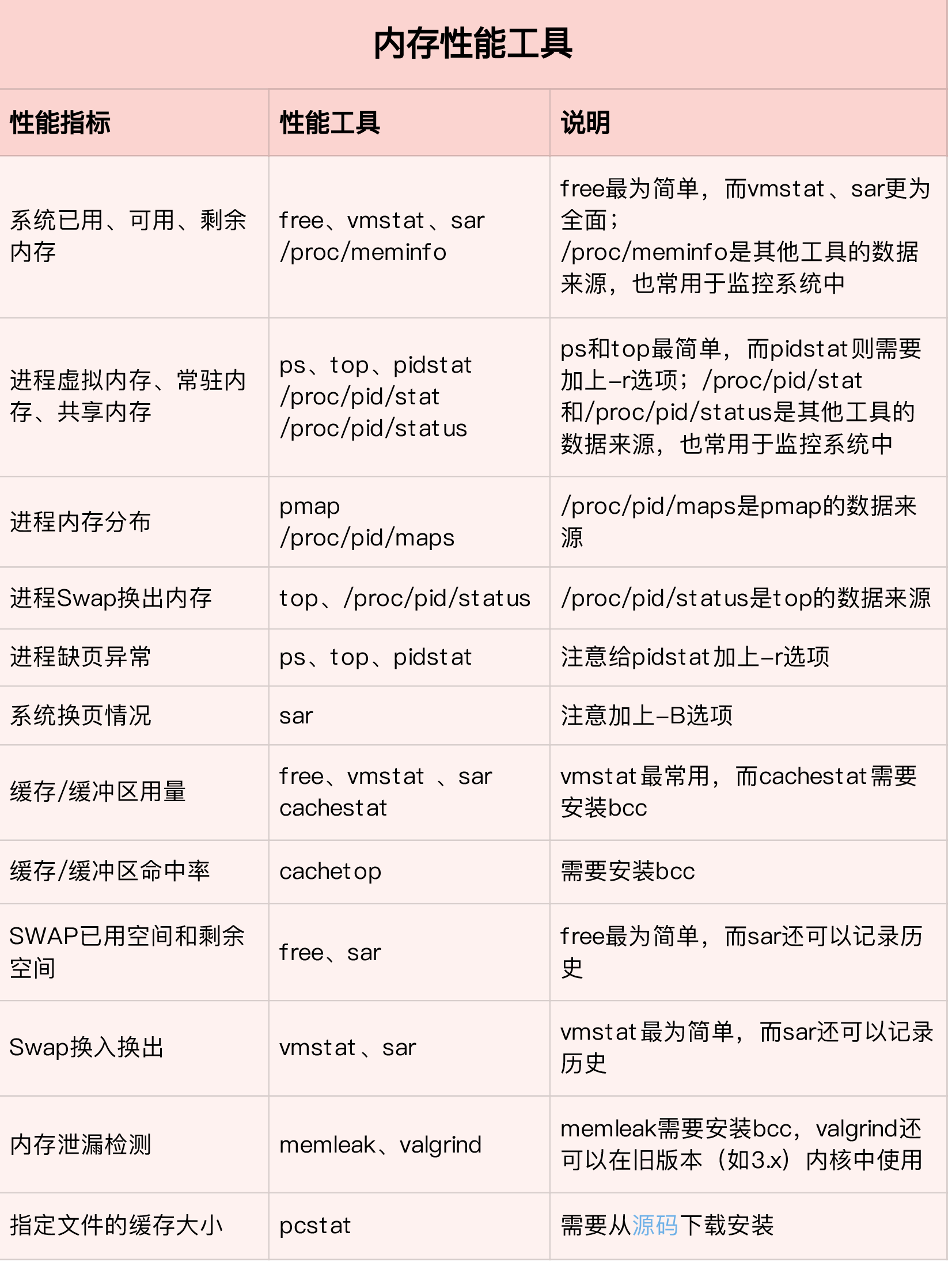
内存分析思路
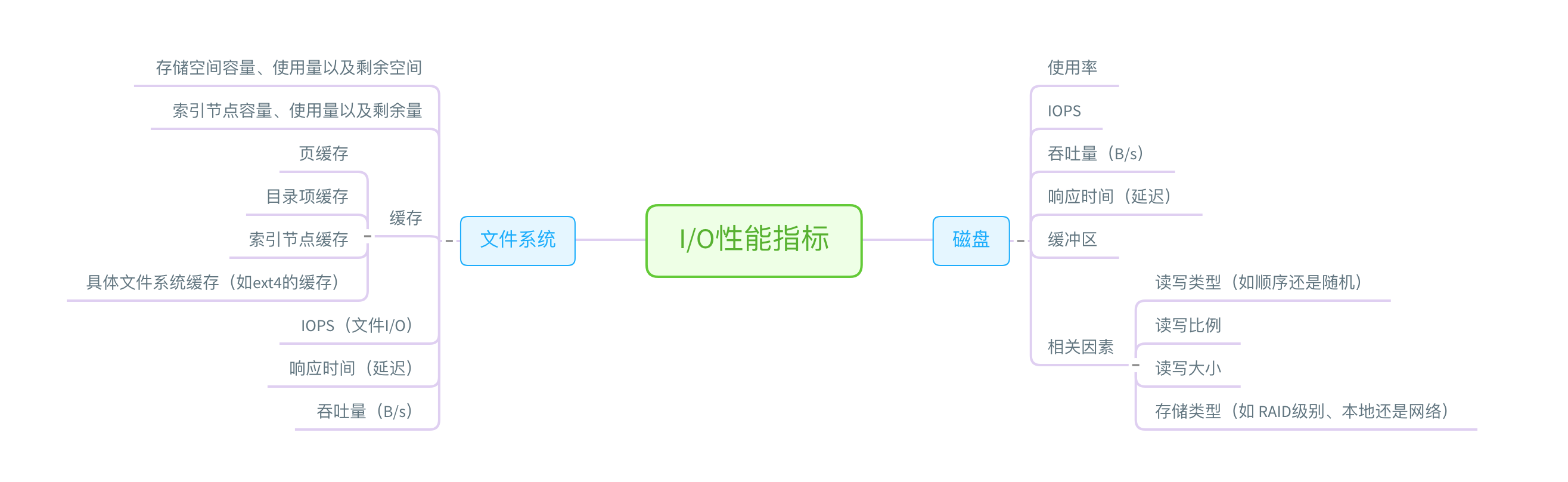
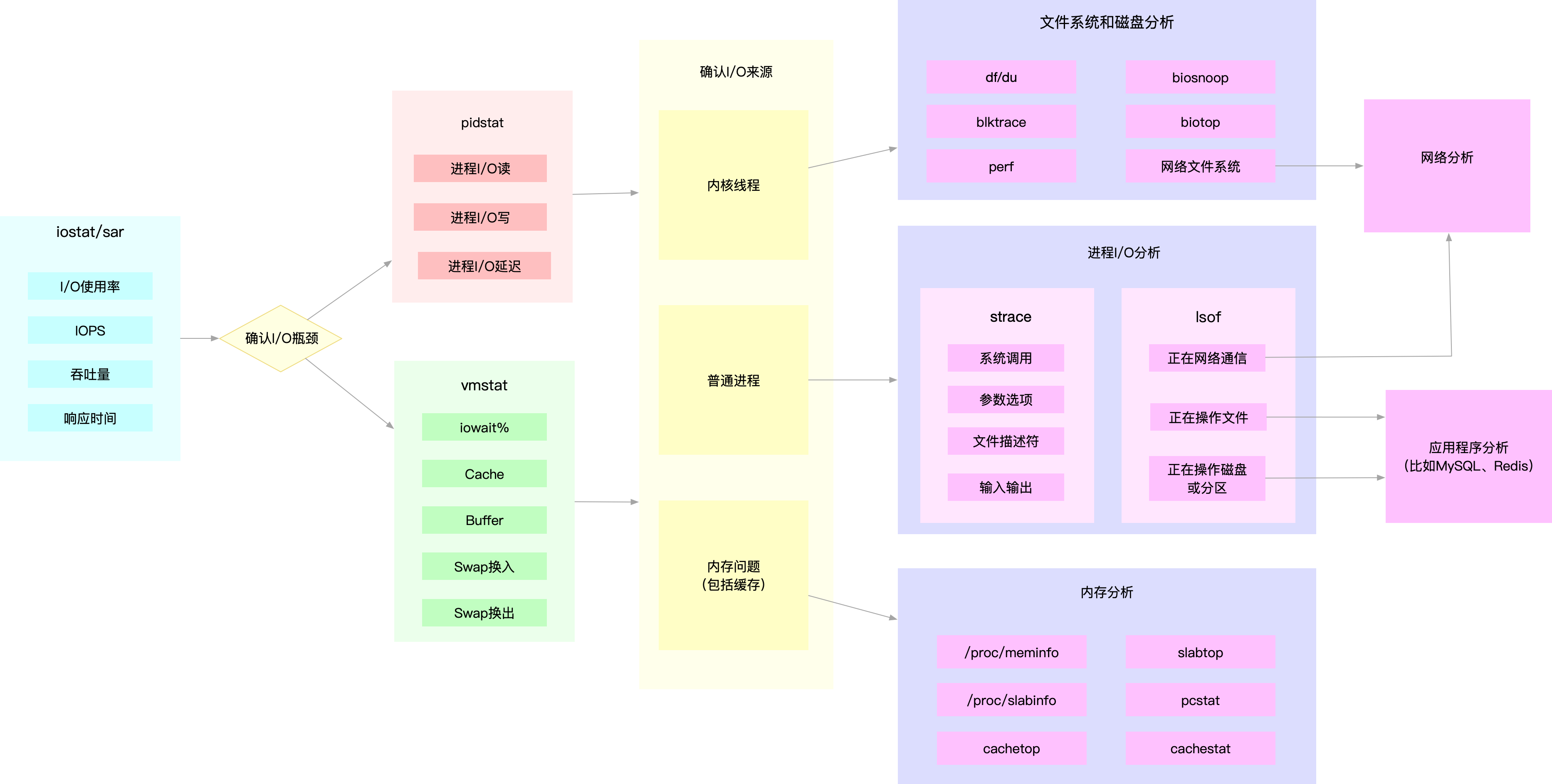
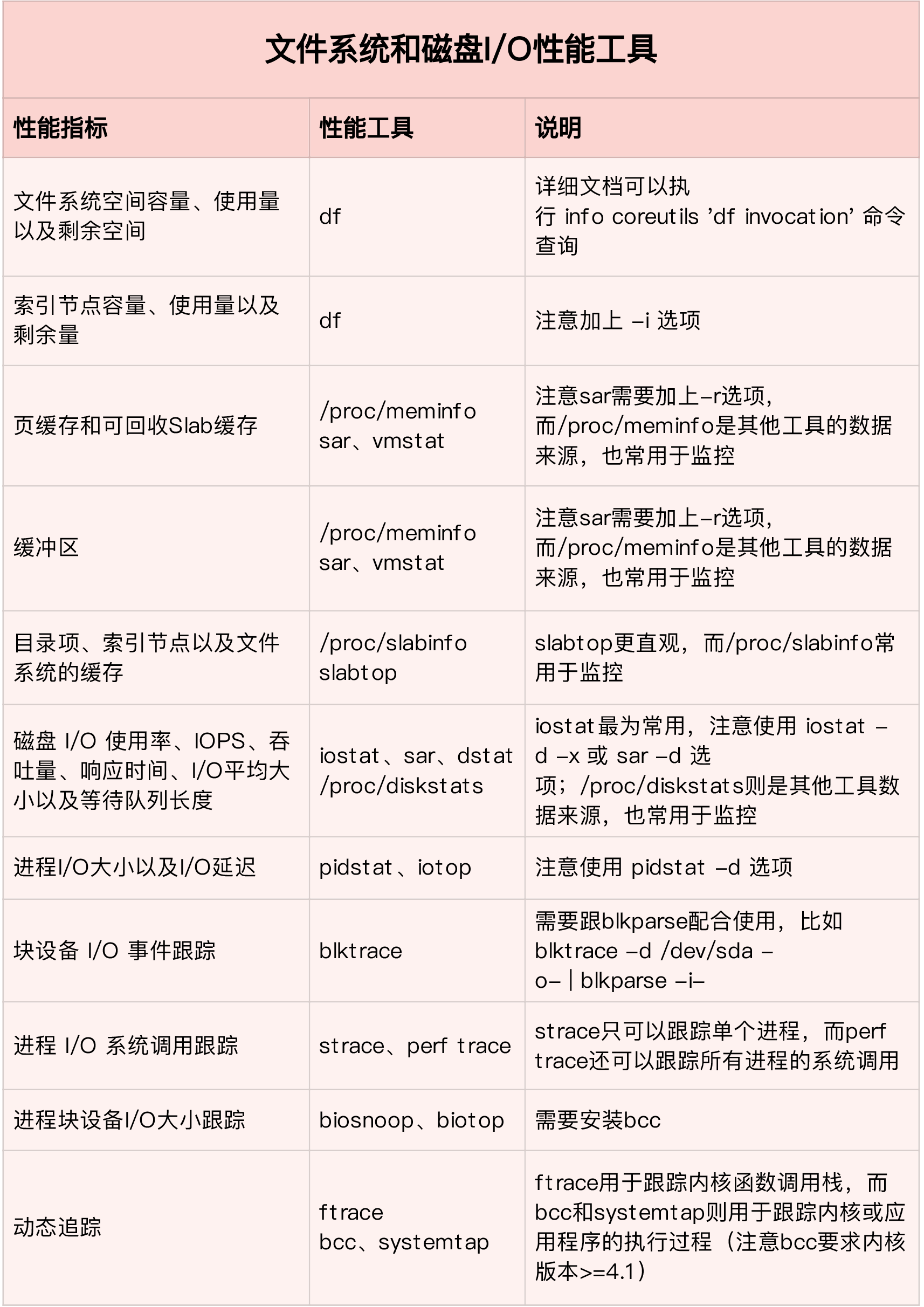
IO分析思路
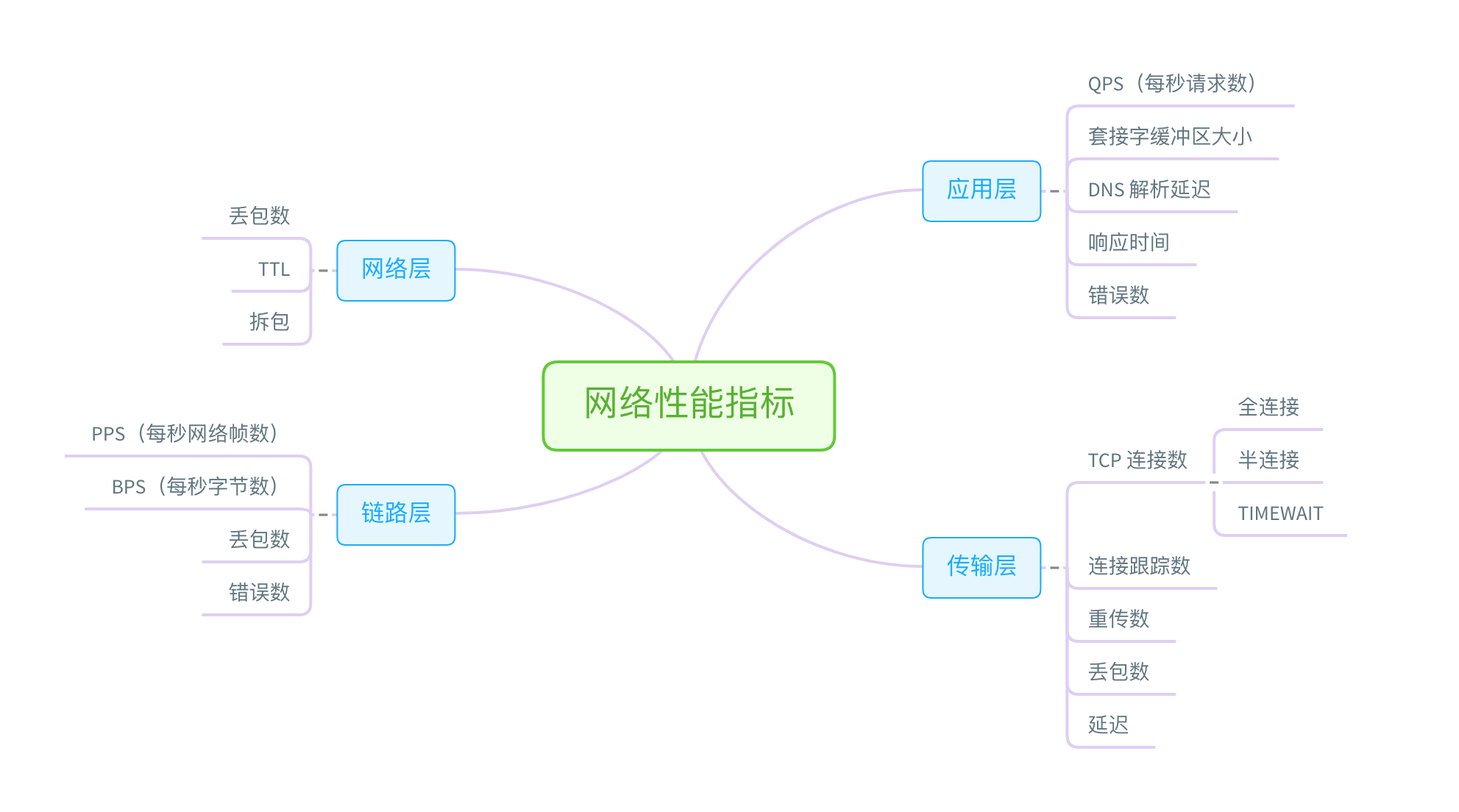
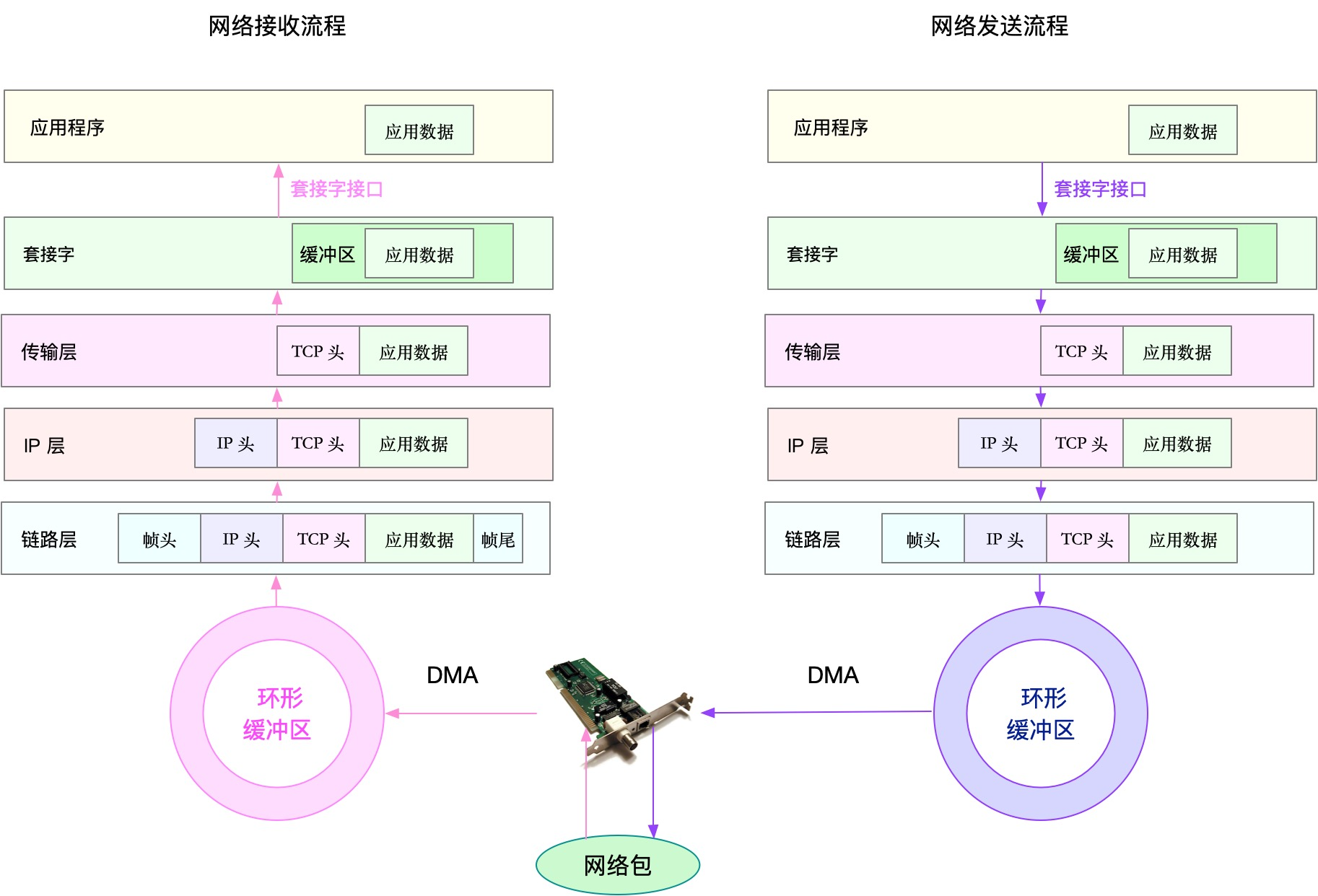
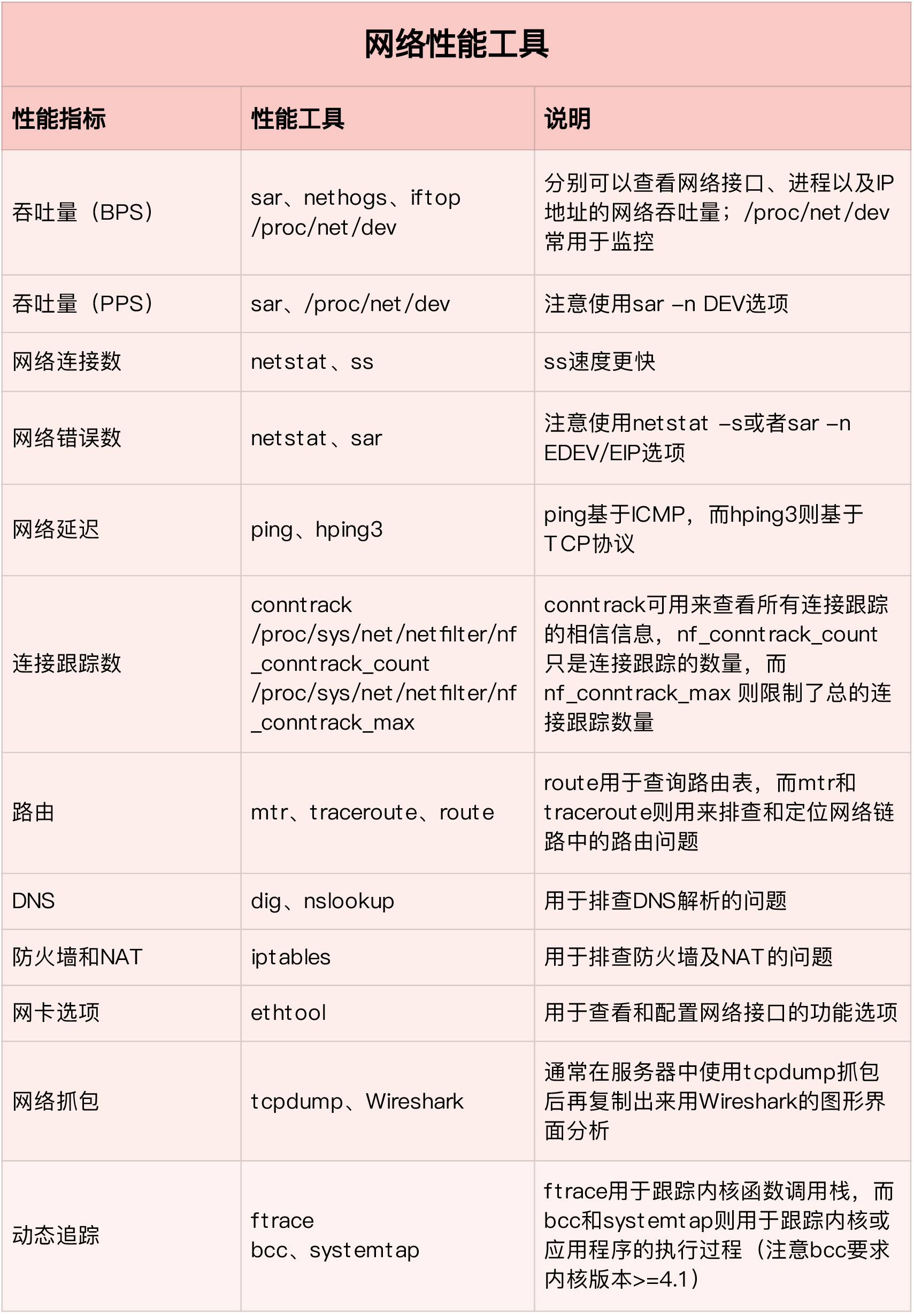
网络分析思路
基准测试工具
参考
相当一部分内容来自极客时间出品的倪鹏飞专栏《Linux性能优化》,是这个专栏的学习笔记。
另一份资料是IBM红宝书Linux性能调优指南。
此外,The Linux Documentation Project是一个非常好的资料库。
将硬件中断的处理任务分配个多个CPU:SMP affinity and proper interrupt handling in Linux