2017-2018-1 20155303 《信息安全系统设计基础》第四周学习总结
————————CONTENTS————————
本周学习内容:完成课本第十章、附录A的学习;参考《The Art of Debugging with GDB, DDD and Eclipse》第四章进行知识点补充;使用Unix I/O函数,并按照MVC模式,实现对Myod的重构优化;了解head,tail的使用,完成对相关API的分析以及伪代码、产品代码和测试代码的编写
- 程序崩溃处理
- 《The Art of Debugging with GDB, DDD and Eclipse》第四章
- 附录A:错误处理
- Linux系统编程
- 第十章:系统级I/O
- Myod(系统调用版本)
- head、tail命令
- 代码托管
- 学习感悟和思考
- 学习进度条
- 参考资料
程序崩溃处理
【《The Art of Debugging with GDB, DDD and Eclipse》第四章】
- 为什么程序会崩溃?
- 当某个错误导致程序突然和异常地停止执行时,程序崩溃。最常见的原因时试图在未经允许的情况下访问一个内存单元。在Unix系列的平台上,操作系统一般会宣布程序导致了“段错误”(seg fault),并停止程序的执行。
一、内存中的程序布局
在Unix平台上,为程序分配的虚拟地址的布局通常类似于下面所示的图:
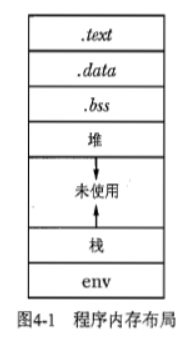
在教材第七章我们曾见到过Linux x86-64运行时的内存映像,下面再来详细了解一下各部分的作用:
- 文本区域(.text):由程序源代码中的编译器产生的机器指令组成。
- 数据区域:包含在编译时分配的所有程序变量,即全局变量。
- 第一个子区域称为.data,由初始化过的变量组成,如:int x = 5;
- 另外一种用于存放未初始化数据的.bss区域,如:int y;
- 堆:当程序在运行时从操作系统中请求额外的内存时(如在C语言中调用malloc()),请求的内存在这一区域中分配。如果堆空间不够,可以调用brk()来扩展堆。
- 栈:用来动态分配数据的空间。函数调用的数据(包括参数、局部变量和返回地址)都存储在栈上。每次函数调用时栈都会增长,每次函数返回到其调用者时栈都会收缩。
- 动态链接代码:由于位置的平台依赖性,图中没有显示程序的动态链接代码,但其确实存在。
以下面程序为例,探索一下虚拟地址空间的布局:
#include <stdio.h>
int q[200];
int main(void){
int i, n, *p;
p = malloc(sizeof(int));
scanf("%d", &n);
for(i = 0; i < 200; i++)
q[i] = i;
printf("%x %x %x %x %x
", main, q, p, &i, scanf);
return 0;
}
运行结果为:

从运行结果可以看到文本区域、数据区域、堆、栈和动态链接函数分别是0x00400646、0x00601080、0x00adc010、0xa268ad18、0x00400530。
二、页的概念
虚拟地址空间是通过组织成称为“页”的块来查看的。操作系统为每个过程设立了一个页表(page table),这一过程的每个虚拟页在表中都有一个对应的项,包含:
- 该页的物理位置,如在内存中或者磁盘上;
- 该页的权限:读、写和执行
程序中的程序错误会导致权限不匹配,并在上面列出的任何类型的内存访问期间生成段错误。例如,假设程序中包含如下全局声明:
int x[100];
并假设代码包含以下语句:
x[i] = 3;
x[i]等价于*(x+i),即地址x+i指向的内存位置的内容。如果偏移量i为200,那么这个表达式可能会产生虚拟内存,它超出了操作系统为该程序的数据区域指定的页组范围,当试图执行写操作时会发生段错误。
但是,轻微的内存访问程序错误可能不会导致段错误。执行下面代码时,其运行结果表明:在预料有段错误的地方不一定都会发生段错误。
int q[200];
main(){
int i;
for(i = 0; i < 2000; i++){
q[i] = i;
}
}
从运行结果可以看出,发生了段错误:

但调试时我们发现,段错误并不是发生在i=200处。当i=251时,仍没有错误提示:
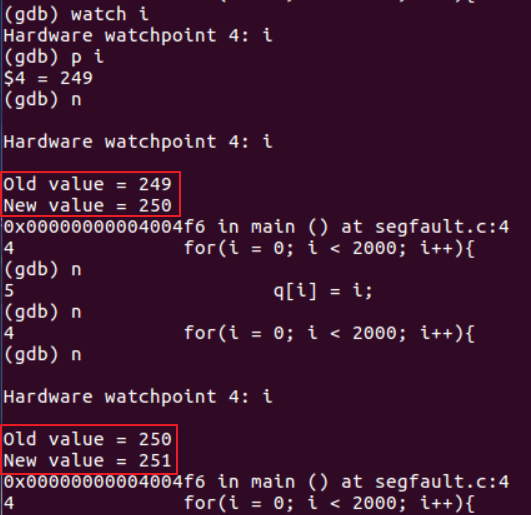
通过之前的学习,我们大致能够明白其原因:
Intel的页大小是4096字节,且页时虚拟内存系统能够操作的最小内存单元。比如说,如果要运行的程序大约有10000字节,如果完全加载,会占3个内存页,而不是2.5个。因此,除去q[200]占用的部分,分配给q的内存页仍有剩余字节,可以存放一定量的整数变量,所以这种越界的读写操作仍然在具有读写权限的页上执行的,因此不会触发段错误。
总之:不能根据有没有发生段错误来得出内存操作正确的结论。
三、段错误与Unix信号
段错误一般导致程序的终止,但对于重大调试,还应了解更多的内容,如Unix信号。
通过man 7 signal查看完整的信号列表,下图展示了一部分:
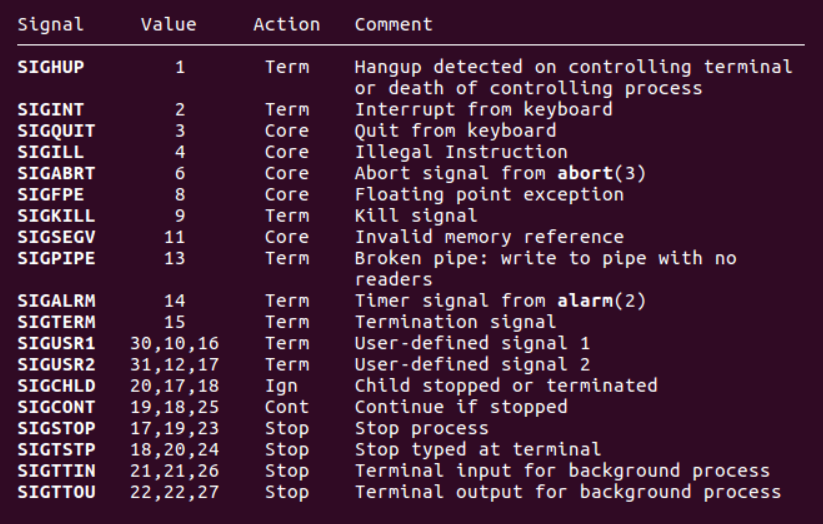
当程序违反内存访问权限时,在进程上发出SIGSEGV信号。默认段错误处理程序终止该程序,并向磁盘上写一个“核心文件”(Core文件)。
————TO BE CONTINUED——
【附录A:错误处理】
Unix系统中的错误处理:
系统级函数调用使用以下三种不同风格的返回错误:Unix风格、Posix风格和GAI风格。
下面展示了这些错误报告函数的代码:
void unix_error(char *msg) //Unix-style error
{
fprintf(stderr, "%s: %s
", msg, strerror(errno));
exit(0);
}
void posix_error(int code, char *msg) //Posix-style error
{
fprintf(stderr, "%s: %s
", msg, strerror(code));
exit(0);
}
void gai_error(int code, char *msg) //Getaddrinfo-style error
{
fprintf(stderr, "%s: %s
", msg, gai_strerror(code));
exit(0);
}
void app_error(char *msg) //Application error
{
fprintf(stderr, "%s
", msg);
exit(0);
}
Linux系统编程
【第十章:系统级I/O】
『问题一』:如何通过Unix I/O函数打开/关闭文件,以及读/写文件?
『问题一解决』:
课堂上介绍过,可以通过man 2 open命令查看与系统调用相关的函数(这里以open为例,其他同理),较易理解,所以不再赘述。这里只总结open/close/read/write函数的用法:
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int open(char *filename, int falgs, mode_t mode);
/* 成功则返回新文件描述符,出错返回-1;
char *filename:函数将filename转换为一个文件描述符,并返回描述符数字;返回的描述符总是在进程中当前没有打开的最小描述符;
int flags:指明进程打算如何访问这个文件;
mode_t mode:指定了新文件的访问权限位。
*/
int close(int fd);
/* 成功则返回0,出错则为-1。 */
ssize_t read(int fd, void *buf, size_t n);
/* 成功则返回读的字节数,若EOF则为0,若出错则为-1。 */
ssize_t write(int fd, const void *buf, size_t n);
/* 成功则返回写的字节数,若出错则为-1。 */
『问题二』:如何理解Linux中的文件描述符与打开文件之间的关系 ?
『问题二解决』:
在Linux系统中一切皆可以看成是文件,文件又可分为:普通文件、目录文件、链接文件和设备文件。文件描述符(file descriptor)是内核为了高效管理已被打开的文件所创建的索引,其是一个非负整数(通常是小整数),用于指代被打开的文件,所有执行I/O操作的系统调用都通过文件描述符。程序刚刚启动的时候,0是标准输入,1是标准输出,2是标准错误。如果此时去打开一个新的文件,它的文件描述符会是3。
每一个文件描述符会与一个打开文件相对应,同时,不同的文件描述符也会指向同一个文件。相同的文件可以被不同的进程打开也可以在同一个进程中被多次打开。系统为每一个进程维护了一个文件描述符表,该表的值都是从0开始的,所以在不同的进程中你会看到相同的文件描述符,这种情况下相同文件描述符有可能指向同一个文件,也有可能指向不同的文件。具体情况要具体分析,要理解具体其概况如何,需要查看由内核维护的3个数据结构。
- 1. 进程级的文件描述符表
- 2. 系统级的打开文件描述符表
- 3. 文件系统的i-node表
下图展示了文件描述符、打开的文件句柄以及i-node之间的关系,图中,两个进程拥有诸多打开的文件描述符。
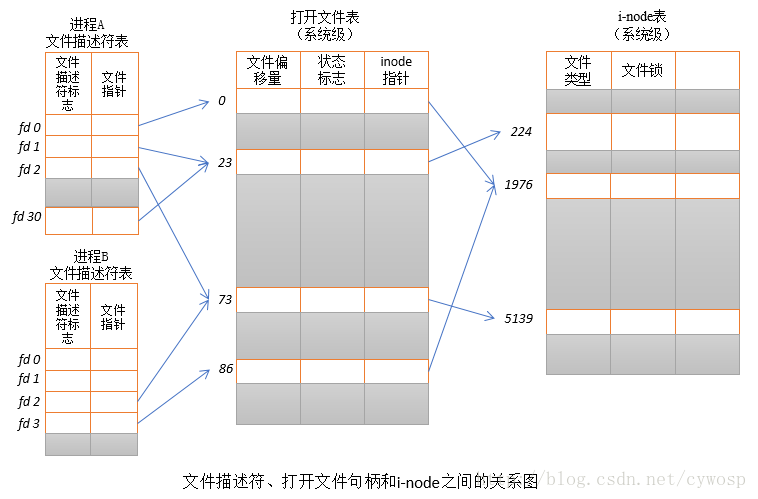
在进程A中,文件描述符1和30都指向了同一个打开的文件句柄(标号23)。这可能是通过调用dup()、dup2()、fcntl()或者对同一个文件多次调用了open()函数而形成的。
进程A的文件描述符2和进程B的文件描述符2都指向了同一个打开的文件句柄(标号73)。这种情形可能是在调用fork()后出现的(即,进程A、B是父子进程关系),或者当某进程通过UNIX域套接字将一个打开的文件描述符传递给另一个进程时,也会发生。再者是不同的进程独自去调用open函数打开了同一个文件,此时进程内部的描述符正好分配到与其他进程打开该文件的描述符一样。
此外,进程A的描述符0和进程B的描述符3分别指向不同的打开文件句柄,但这些句柄均指向i-node表的相同条目(1976),换言之,指向同一个文件。发生这种情况是因为每个进程各自对同一个文件发起了open()调用。同一个进程两次打开同一个文件,也会发生类似情况。
参考以下程序:
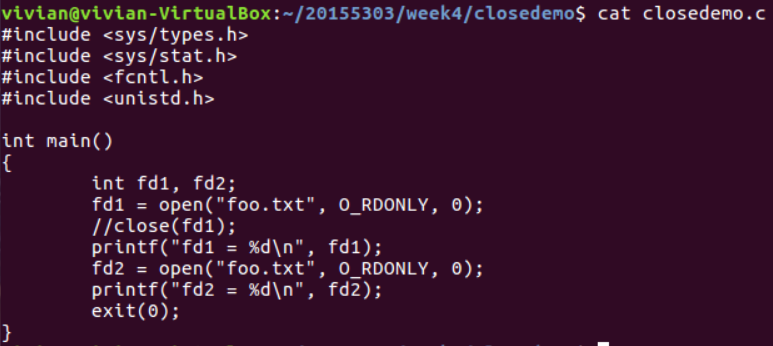
该进程两次打开了同一个文件,运行结果为:

但需要注意的是,关闭一个已关闭的描述符会出错,如:
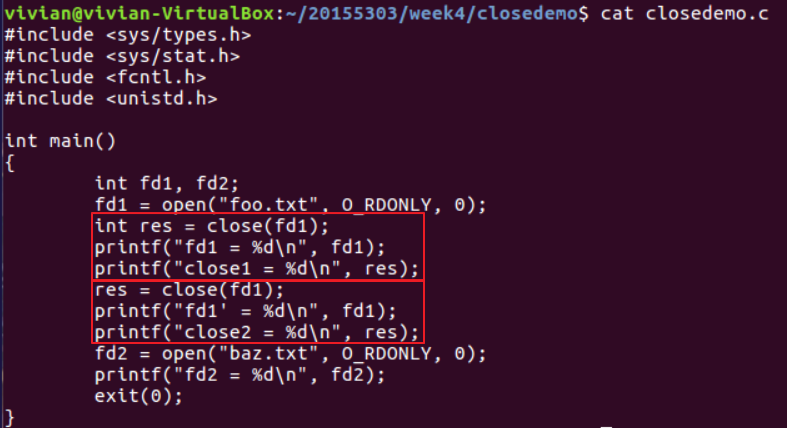
运行结果为:

『问题三』:如何理解并使用I/O重定向?
『问题三解决』:
使用ls > foo.txt,可以将标准输出重定向到磁盘文件foo.txt。I/O重定向是如何工作的呢?一种方式是使用dup2函数。

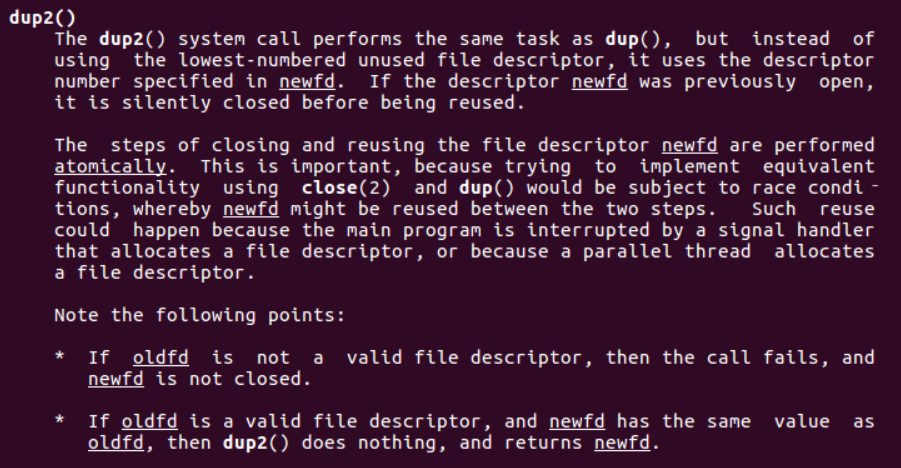
通过查阅手册我们了解到,dup2函数复制描述表项oldfd到描述符表项newfd,覆盖描述表表项newfd以前的内容。如果newfd已经打开了,dup2会在复制oldfd之前关闭newfd。
如以下程序:
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
int main(){
int fd1, fd2;
char c;
fd1 = open("foobar.txt", O_RDONLY, 0);
fd2 = open("foobar.txt", O_RDONLY, 0);
read(fd2, &c, 1);
printf("c1 = %c
", c);
dup2(fd2, fd1);
read(fd1, &c, 1);
printf("c2 = %c
", c);
exit(0);
}
运行结果

【Myod(系统调用版本)】
在前面的博客中,我们通过调用标准I/O函数(fopen、fread等)实现了od命令的效果。这次,根据对系统调用函数的了解和学习,稍作改动即可:
FILE *file=fopen(argv[3],"r");改为int fd=open(argv[3],O_RDONLY,0);;fgets(ch,17,file)改为read(fd,&ch,BUFFERSIZE)fclose(file);改为close(fd);- ......
『MVC模式』:
在上一次的博客中,娄老师提出改进意见:
可以了解一下设计模式中的MVC模式,可以体会函数设计的不合理性。不同的显示方式可以是数据(M)的视图(V),数据一份就够。
在我的原设计中,函数传递的参数为文件指针,需要把数据获取很多次;而且,如果遇到不需要传递文件指针的情况(比如这次需要用到系统调用),函数还需要做较大的改动。
因此,函数的参数设计为数据的数组比较好,这样,主函数中读取一次就可以了。
基于对MVC模式的理解,在主函数中将文件中的内容存入数组,把数组作为参数传递给函数进行处理。如果以后遇到数据从其他地方获取的情况(比如数据库等等),直接复用函数即可。
修改后的程序如下:
head.h:
#ifndef HEAD_H
#define HEAD_H
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
void tx(char ch[], int size);
void to(char ch[], int size);
void td(char ch[], int size);
#endif
main.c:
#include "head.h"
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#define BUFFERSIZE 4096
int main(int argc,char *argv[])
{
int fd=open(argv[3],O_RDONLY,0);
char ch[BUFFERSIZE];
int size = read(fd,&ch,BUFFERSIZE);
close(fd);
if(strcmp(argv[2], "-tx1")==0){
tx(ch,size);
}
else if(strcmp(argv[2], "-to1")==0){
to(ch,size);
}
else if(strcmp(argv[2], "-td1")==0){
td(ch,size);
}
return 0;
}
tx.c:
#include "head.h"
#define BUFFERSIZE 4096
void tx(char ch[], int size)
{
//char ch[BUFFERSIZE];
int i=0,j=0;
//int size = read(fd,&ch,BUFFERSIZE);
while(size/16!= (j-1)){
printf("%07o",16*j);
j++;
putchar(' ');
for(i=16*(j-1);i<16*j;i++)
{
if(ch[i]=='
')
{ i++;
putchar(' ');
printf("\n");
}
if(ch[i]=='�')
break;
putchar(' ');
putchar(' ');
printf("%c", ch[i]);
putchar(' ');
}
printf("
");
printf(" ");
for(i=16*(j-1);i<16*j;i++)
{
if(ch[i]=="
")
{ i++;
printf("%3x ",'
');
}
if(ch[i]=='�')
break;
printf("%3x ",ch[i]);
}
printf("
");
}
printf("%07o
",i);
}
其他如实现-td1/-to1等的函数与tx()类似,只需略微调整输出格式,完整代码已上传至码云。
运行对比图如下:
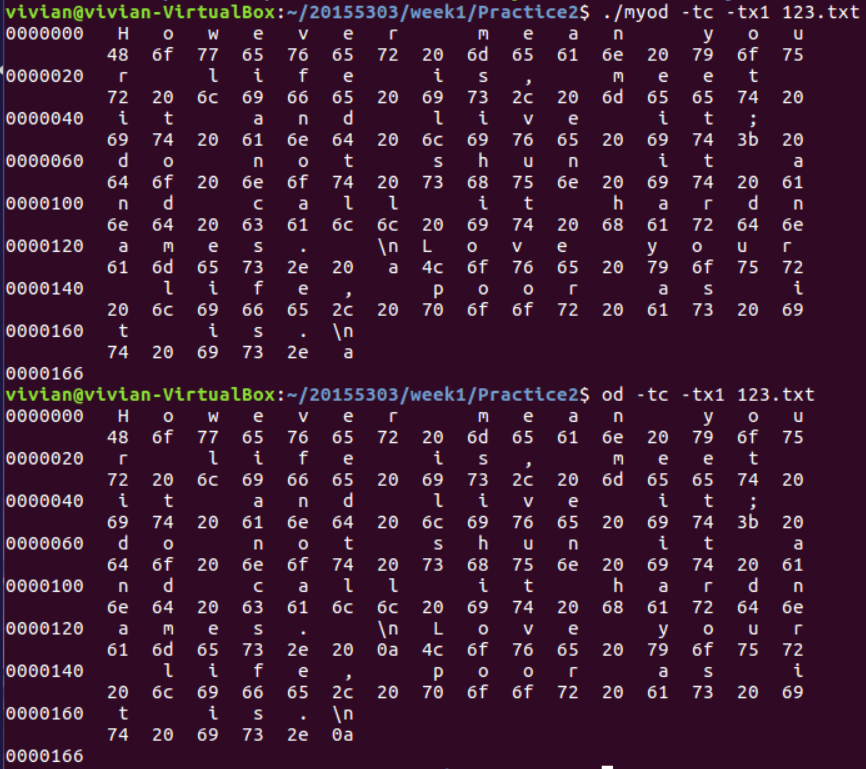
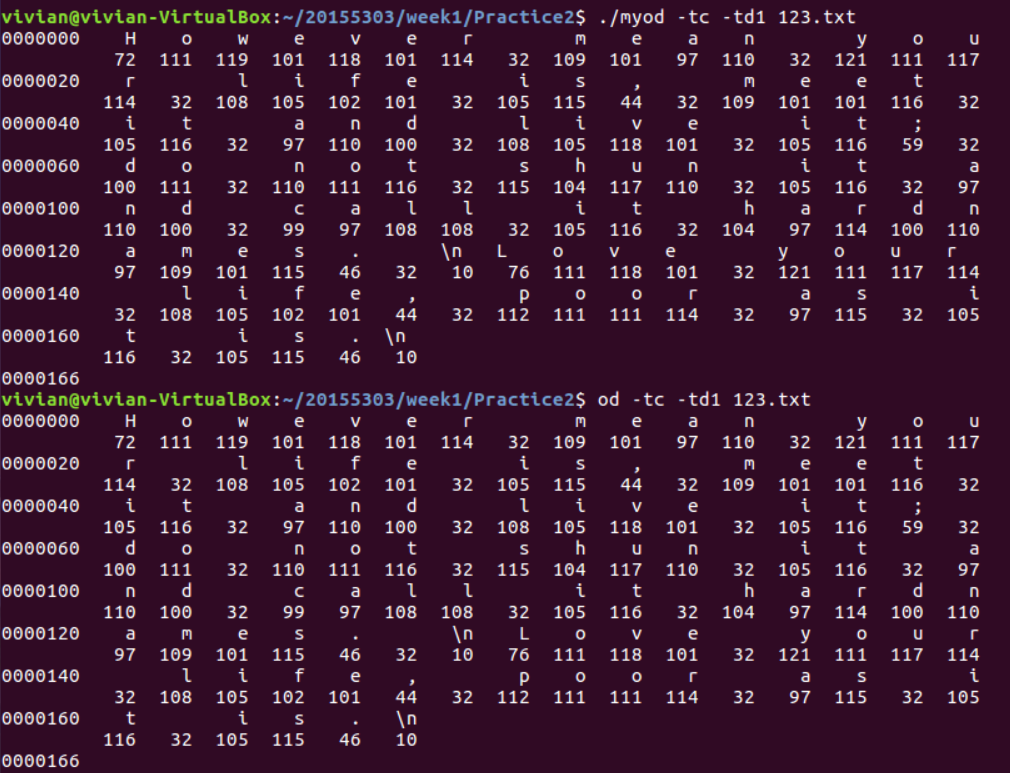
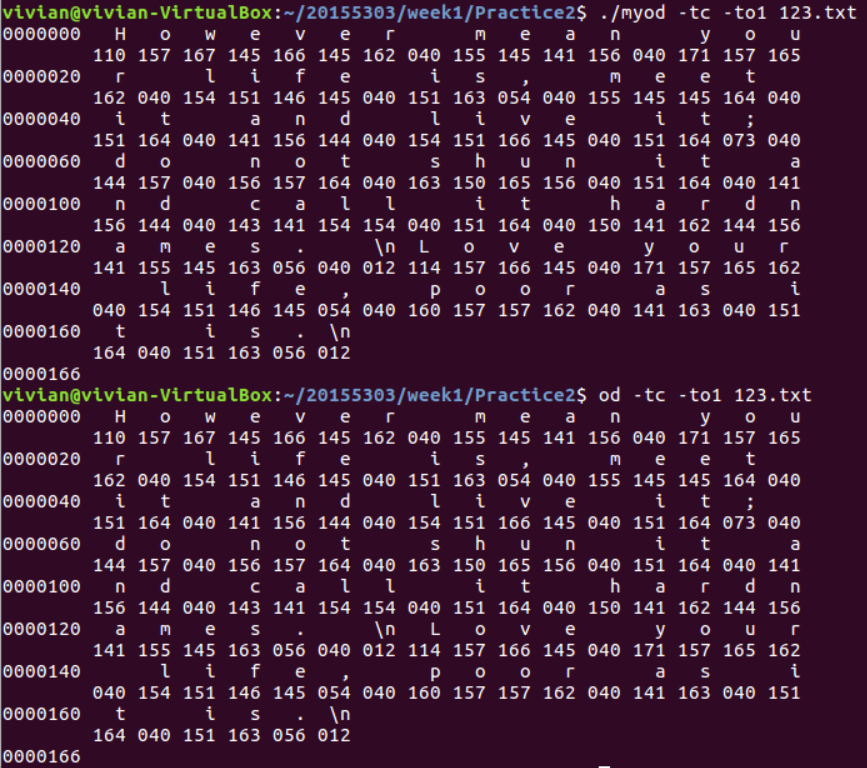
【head、tail命令】
一、伪代码:
程序主要实现head和tail的命令,默认情况下打印前十行(head)和后十行(tail)。myod在主函数将文件内容存为数组,传递给函数进行处理,这里的head和tail函数也可以用同样的思路。
以下是两个函数的伪代码:
void newHead(包含文件内容的数组ch, 数组大小){
for(i = 0; i<数组大小且集齐10个换行符; i++){
if(ch[i]不是换行符){
打印这个字符;
}
else{
换行符计数器+1;
printf("
");
}
}
void newTail(包含文件内容的数组ch, 数组大小){
for(i = 数组大小; i>0且未集齐10个换行符; i--){ //从后向前遍历数组元素
if(ch[i]是换行符){
换行符计数器+1;
}
}
//此时,数组从第i个元素往后,都是需要打印的字符
for(k = i-1; k <= 数组大小; k++){
打印这个字符;
}
}
二、产品代码:
head/tail命令在实现上与上面的myod本质相同,都是通过系统调用来完成。主要用到open()、read()等函数。
产品代码如下:
head.h:
#ifndef HEAD_H
#define HEAD_H
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
void newHead(char text[], int size);
void newTail(char text[], int size);
#endif
demo.c
#include "head.h"
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#define BUFFERSIZE 4096
int main(int argc,char *argv[])
{
int fd=open(argv[2],O_RDONLY,0);
char ch[BUFFERSIZE];
int size = read(fd,&ch,BUFFERSIZE);
//printf("%d
", size);
close(fd);
if(strcmp(argv[1], "head")==0){
newHead(ch,size);
}
else if(strcmp(argv[1], "tail")==0){
newTail(ch,size);
}
return 0;
}
newHead.c:
#include "head.h"
void newHead(char text[], int size)
{
int i , j = 0;
for(i = 0; i < size, j < 10; i++){
if(text[i]!='
'){
printf("%c", text[i]);
}
else{
j++;
printf("
");
}
}
}
newTail.c:
#include "head.h"
void newTail(char text[], int size)
{
int i , j = 0, k = 0;
for(i = size; i > 0, j < 10; i--){
if(text[i]=='
'){
j++;
}
}
for(k = i-1; k <= size; k++){
printf("%c", text[k]);
}
}
三、测试代码:
以上程序只考虑了正常情况,没有设置异常处理,如:命令行传入的参数个数错误、调用open/read/close函数失败,以及未正确输入head/tail命令等等。
基于以上考虑对程序进行了修改,完整代码已上传至码云。
运行结果如下:
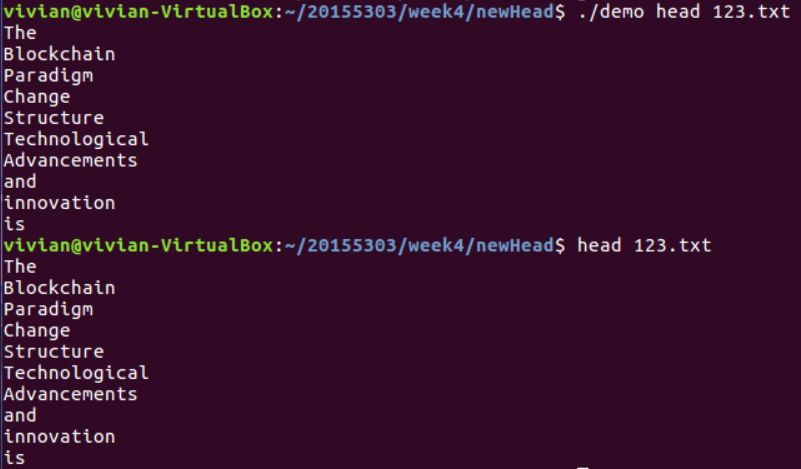
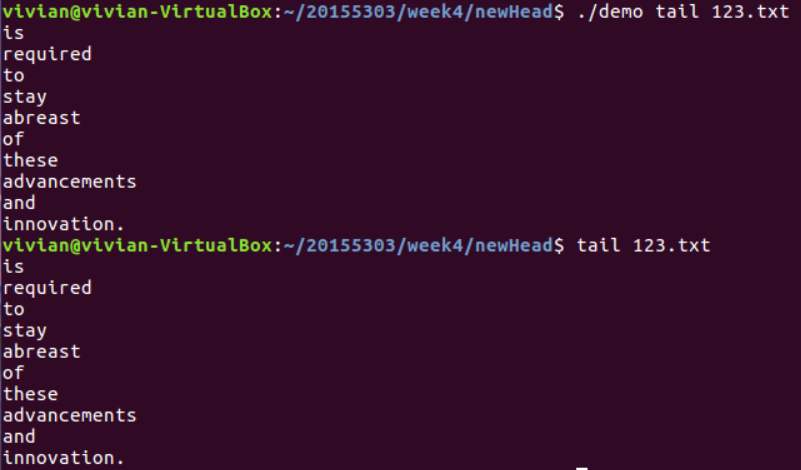
对异常情况的处理如下:

代码托管
-
本周代码量截图:
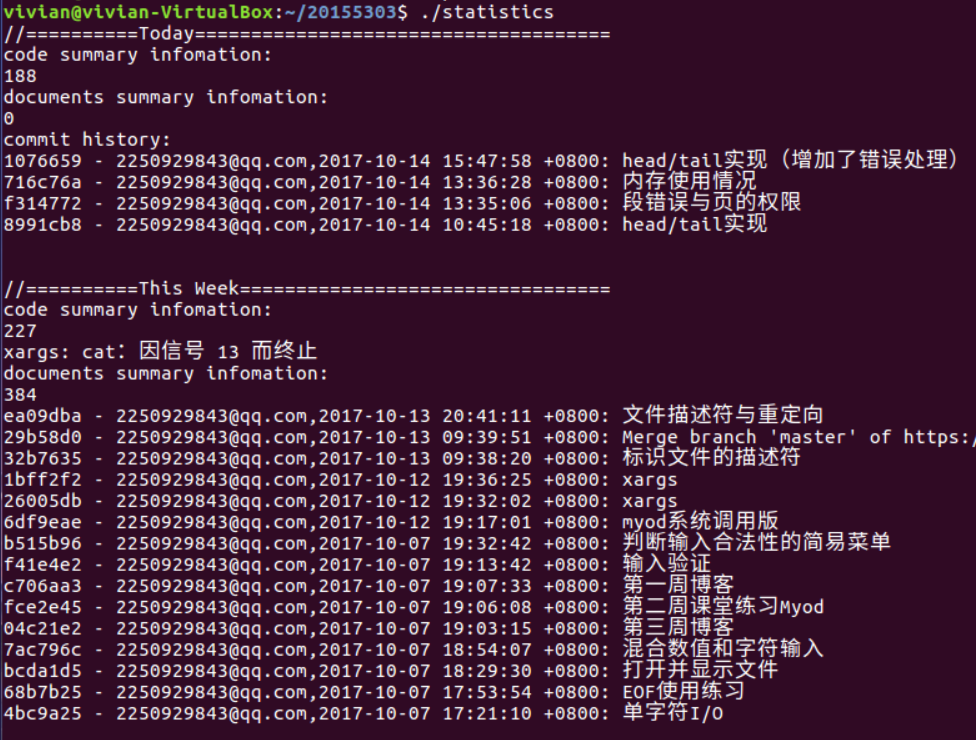
运行脚本时提示“xargs: cat:因信号 13 而终止”,一些文件夹的.c文件不能进行正常统计。这个问题目前还未解决,所以运行结果并不准确,仅供参考。
学习感悟和思考
本周通过实践体会到了MVC模式的优势。之前实现的myod使用文件指针作为参数,局限性非常大,一旦未使用文件相关操作的函数(比如这次使用Unix I/O函数),无论是主函数还是子函数都需要做较大的改动,违背了“低耦合”的思想。在老师的启发下了解了MVC模式,使程序的输入、处理和输出分开,并尽量减少代码的重复,以达到降低耦合性、提高重用性的目的。
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 20篇 | 400小时 | |
| 第一周 | 50/50 | 1/1 | 8/8 | 了解计算机系统、静态链接与动态链接 |
| 第三周 | 451/501 | 2/3 | 27/35 | 深入学习计算机算术运算的特性 |
| 第四周 | ? / ? | 1/4 | 20/55 | 掌握程序崩溃处理、Linux系统编程等知识,利用所学知识优化myod,并实现head和tail命令 |