1.大体框架列出+爬取网页:
#数据可视化
from pyecharts import Bar
#用来url连接登陆等功能
import requests
#解析数据
from bs4 import BeautifulSoup
#用来存取爬取到的数据
data = []
def parse_data(url):
headers = {
'User-Agent':"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400"
}
rest = requests.get(url=url, headers=headers)#使用requests.get方法爬取网页
# 一般人可能会用rest.text,但是会显示乱码
text = rest.content.decode('utf-8')#使用utf-8解码,防止显示乱码,接下来无法解析
soup = BeautifulSoup(text, 'html5lib')#BeautifulSoup方法需要指定解析文本和解析方式
def main():
url = "http://www.weather.com.cn/textFC/hb.shtml"
parse_data(url)
if __name__ == '__main__':
main()
parse_data函数主要用于爬取以及解析数据
headers可以在网页之中查找
易错点:当使用requests.get获取到网页之后,一般可能使用text方法进行数据获取,但是尝试之后数据产生了乱码,因为requests.get方法获取再用text解码时候默认ISO-8859-1解码,
因此使用content方法并指定decode('utf-8')进行解码
数据解析我使用的是bs4库,也可以用lxml库,但是感觉没有bs4方便,解析方式使用html5lib,对于html数据解析更具有容错性和开放性
2.爬取网页解析:
# 爬取数据
cons = soup.find('div', attrs={'class':'conMidtab'})
tables = cons.find_all('table')
for table in tables:
trs = table.find_all('tr')[2:]
for index,tr in enumerate(trs):
if index == 0:
tds = tr.find_all('td')[1]
qiwen = tr.find_all('td')[4]
else:
tds = tr.find_all('td')[0]
qiwen = tr.find_all('td')[3]
city = list(tds.stripped_strings)[0]
wendu = list(qiwen.stripped_strings)[0]
data.append({'城市':city, '最高气温':wendu})
bs4库一般使用方法是find或者find_all方法(详细内容见上一篇博客)
find方法比较使用的是可以查找指定内容的数据,使用attrs={}来定制条件,代码中我用了attrs={'class':'conMidtab'}或者使用class_='conMidtab'
查看网页源代码可知

通过'class':'conMidtab'来定位到所需信息的表
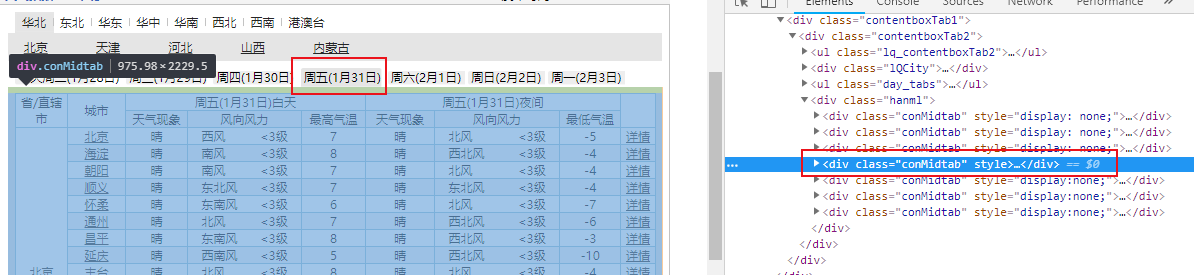
再分析:因为有多个conMidtab,所以测试分析得知多个conMidtab对应的是今天,明天,后天......的天气情况
我们分析的是今天的情况,所以取第一个conMidtab,使用soup.find("div",class_="conMidtab")获取第一个conMidtab的内容
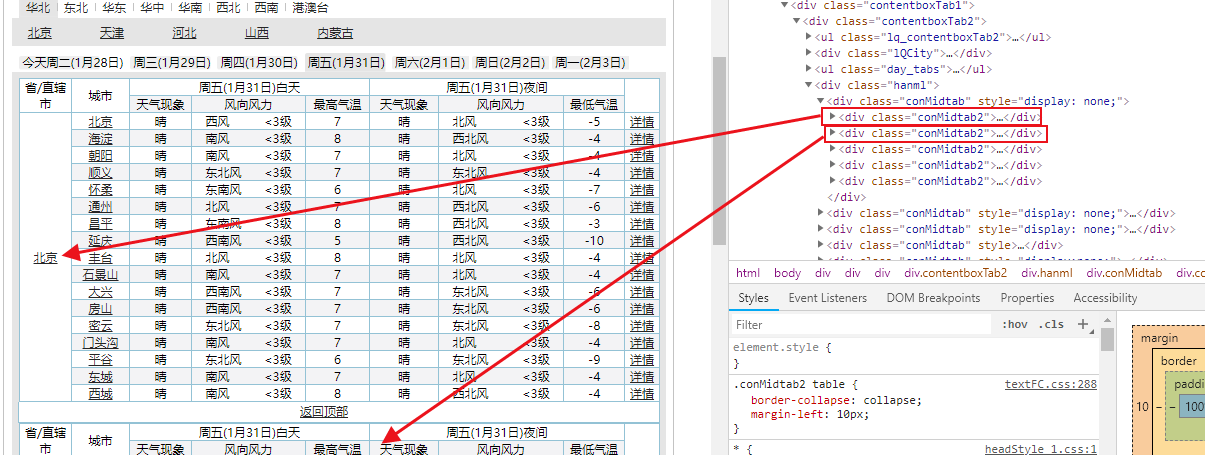
由上知:conMidtab下的多个class="conMidtab2"代表不同的省的天气信息
但是在研究可以发现,所有天气信息都是存储在table里的,因此获取所有tables即可——cons.find_all('table')
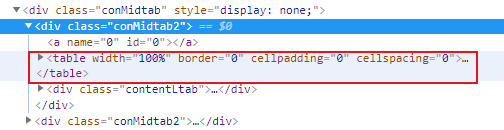
同时对于每一个table而言:第三个tr开始才是对应的城市信息,故对于每一个table获取trs = table.find_all("tr")[2:]

易错点:同时发现对于每个省第一个城市,它隐藏在tr的第二个td里,而除此之外的该省其他城市则在tr的第一个td里,因此使用一个if和else判断
enumerate方法可以产生一个index下标,因此在遍历trs的时候可以知道当index==0的时候是第一行


之后分析:城市名字:对于每个省第一个城市,它隐藏在tr的第二个td里,而除此之外的该省其他城市则在tr的第一个td里
最高气温:对于每个省第一个城市,它隐藏在tr的第五个td里,而除此之外的该省其他城市则在tr的第四个td里
因此使用
if index == 0:
tds = tr.find_all('td')[1]
qiwen = tr.find_all('td')[4]
else:
tds = tr.find_all('td')[0]
qiwen = tr.find_all('td')[3]
最后使用stripped_strings获取字符串并且添加到data列表里
3.进行所有城市的数据获取:
def main():
urls = [
"http://www.weather.com.cn/textFC/hb.shtml",
"http://www.weather.com.cn/textFC/db.shtml",
"http://www.weather.com.cn/textFC/hd.shtml",
"http://www.weather.com.cn/textFC/hz.shtml",
"http://www.weather.com.cn/textFC/hn.shtml",
"http://www.weather.com.cn/textFC/xb.shtml",
"http://www.weather.com.cn/textFC/xn.shtml",
"http://www.weather.com.cn/textFC/gat.shtml"
]
for url in urls:
parse_data(url)
修改了一下main方法:获取全国数据
4.数据排序找出全国气温最高十大城市:
# 排序找出十大温度最高的城市 # 按照温度排序 data.sort(key=lambda x:int(x['最高气温'])) #十大温度最高的城市 data_2 = data[-10:]
其中在排序的时候注意:要转化为int型才可以进行排序,否则是按照string进行排序的。
5.数据可视化:
citys = list(map(lambda x:x['城市'], data_2))#横坐标
wendu = list(map(lambda x:x['最高气温'], data_2))#纵坐标
charts = Bar('中国十大最高温度城市')
charts.add('', citys, wendu)
charts.render('天气网.html')
使用Bar模块:
Bar方法主要可以给该图标命名
add方法主要是添加(图颜色的名称,横坐标名, 纵坐标名)
render主要是存储在本地之中
结果展示:

完整代码:
#数据可视化
from pyecharts import Bar
#用来url连接登陆等功能
import requests
#解析数据
from bs4 import BeautifulSoup
#用来存取爬取到的数据
data = []
def parse_data(url):
headers = {
'User-Agent':"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400"
}
rest = requests.get(url=url, headers=headers)#使用requests.get方法爬取网页
# 一般人可能会用rest.text,但是会显示乱码
text = rest.content.decode('utf-8')#使用utf-8解码,防止显示乱码,接下来无法解析
soup = BeautifulSoup(text, 'html5lib')#BeautifulSoup方法需要指定解析文本和解析方式
# 爬取数据
cons = soup.find('div', attrs={'class':'conMidtab'})
tables = cons.find_all('table')
for table in tables:
trs = table.find_all('tr')[2:]
for index,tr in enumerate(trs):
if index == 0:
tds = tr.find_all('td')[1]
qiwen = tr.find_all('td')[4]
else:
tds = tr.find_all('td')[0]
qiwen = tr.find_all('td')[3]
city = list(tds.stripped_strings)[0]
wendu = list(qiwen.stripped_strings)[0]
data.append({'城市':city, '最高气温':wendu})
def main():
urls = [
"http://www.weather.com.cn/textFC/hb.shtml",
"http://www.weather.com.cn/textFC/db.shtml",
"http://www.weather.com.cn/textFC/hd.shtml",
"http://www.weather.com.cn/textFC/hz.shtml",
"http://www.weather.com.cn/textFC/hn.shtml",
"http://www.weather.com.cn/textFC/xb.shtml",
"http://www.weather.com.cn/textFC/xn.shtml",
"http://www.weather.com.cn/textFC/gat.shtml"
]
for url in urls:
parse_data(url)
# 排序找出十大温度最高的城市
# 按照温度排序
data.sort(key=lambda x:int(x['最高气温']))
#十大温度最高的城市
data_2 = data[-10:]
# 数据可视化
citys = list(map(lambda x:x['城市'], data_2))#横坐标
wendu = list(map(lambda x:x['最高气温'], data_2))#纵坐标
charts = Bar('中国十大最高温度城市')
charts.add('', citys, wendu)
charts.render('天气网.html')
if __name__ == '__main__':
main()