1. Flume概念
- Flume是Cloudera提供的一个高可用,高可靠,分布式的海量日志采集、聚合和传输的系统
- Flume支持在日志系统中定制各种数据发送方,用于收集数据
- Flume提供对数据进行处理,并写到各种不同的数据接收方的能力(可定制).
2. Flume架构
- Flume的核心是把数据从数据源收集过来再送到目的地,为了保证输送的成功,在送到目的地前flume会缓存数据,等到数据传输完成后,再删掉自己缓存的数据
- Flume的核心角色是agent,flume采集系统就是由一个个agent所链接起来的
- flume的agent有三个组件组成
- source
- 采集组件,数据的收集端,负责跟数据源对接,以获取数据,source会在将数据捕获后,对数据进行格式化,将数据封装到事件(Event)中,然后将事件推入到channel中
- source 主要分以下几种
- Avro Source
- Listens on Avro port and receives events from external Avro client streams.
- Thrift Source
- Listens on Thrift port and receives events from external Thrift client streams.
- Exec Source
- Exec source runs a given Unix command on start-up and expects that process to continuously produce data on standard out (stderr is simply discarded, unless property logStdErr is set to true)
- Spooling Directory Source
- This source lets you ingest data by placing files to be ingested into a “spooling” directory on disk - 除了以上几种外还有JMS Source 、NetCat Source、Syslog Source、Syslog TCP Source、Syslog UDP Source、HTTP Source、HDFS Source,etc。而且Flume还允许自定义source
- Avro Source
- channel
- 传输通道,可以缓存数据,用于从source将数据传输给sink
- Flume对于Channel,则提供了Memory Channel、JDBC Chanel、File Channel,etc。
- sink
- 下沉组件,取出channel的数据,进行相应的存储文件系统、数据库、提交到远程的服务器或者是下一级的agent中
- Flume也提供了很多sink的实现,包括HDFS sink、Logger sink、Avro sink、File Roll sink、Null sink、HBase sink,etc。
- source
3. Flume 采集系统
- 简单结构
- 单个agent采集数据
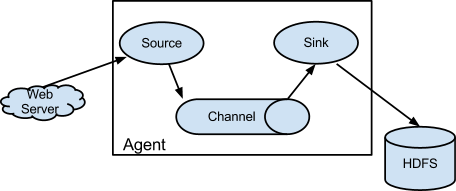
- 单个agent采集数据
- 复杂结构
- 两个agent互联

- 多个agent互联
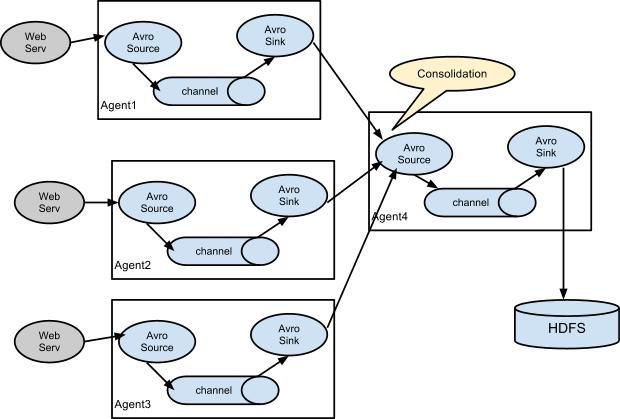
- 多个channel

- 两个agent互联
4. Flume的安装
Flume的安装比较简单
- 下载安装包
官网地址http://archive.cloudera.com/cdh5/cdh/5/flume-ng-1.6.0-cdh5.14.2.tar.gz - 规划安装目录
/bigdata/install - 解压安装包到指定的规划目录,并重命名文件夹
tar -zxvf flume-ng-1.6.0-cdh5.14.2.tar.gz -C /bigdata/install
mv apache-flume-1.6.0-cdh5.14.2-bin flume-1.6.0-cdh5.14.2
- 修改配置文件
- 将 /bigdata/install/flume-1.6.0-cdh5.14.2/conf/里面的 flume-env.sh.template 重命名为 flume-env.sh
- 修改flume-env.sh
export JAVA_HOME=${your java home}
5. 实例
5.1 采集文件到控制台
-
需求
监控某个文件如果又新增内容就把数据采集到控制台显示 -
修改配置文件
在flume的安装目录新建一个myconf文件夹用于存放flume的开发配置文件
vim tail-log.conf#定义一个agent,分别指定source、channel、sink别名 a1.sources = r1 a1.channels = c1 a1.sinks = k1 #定义source #指定source的类型为exec,即通过Linux命令来传输数据 a1.sources.r1.type = exec #监控一个文件,如果有新的数据产生就采集走 a1.sources.r1.command = tail -F /bigdata/data/flume/tail.log #指定source的数据流入的channel中 a1.sources.r1.channels = c1 #配置channel #指定channel的类型为memory a1.channels.c1.type = memory #指定channel 最多可以存放的容量 a1.channels.c1.capacity = 1000 #指定事务中source写数据到channel或者sink从channel中取数据的最大的条数 a1.channels.c1.transactionCapacity = 100 #配置sink #指定sink从哪个channel中获取数据 a1.sinks.k1.channel = c1 #指定sink的类型为日志格式。结果会打印在控制台中 a1.sinks.k1.type = logger -
启动agent
进入到node01的/bigdata/install/flume-1.6.0-cdh5.14.2目录执行bin/flume-ng agent -n a1 -c myconf -f myconf/tail-log.conf -Dflume.root.logger=info.console -n指定该agent的名称 -c表示配置文件所在的目录 -f指定配置文件 -D表示指定key=value键值对---这里指定的是启动的日志输出级别
5.2 采集文件到HDFS
-
需求描述
监控一个文件如果有新增的内容就把数据采集到HDFS上
-
Flume配置文件
vim file2Hdfs.conf
#定义一个agent,分别指定source、channel、sink别名 a1.sources = r1 a1.channels = c1 a1.sinks = k1 #定义source #指定source的类型为exec,即通过Linux命令来传输数据 a1.sources.r1.type = exec #监控一个文件,如果有新的数据产生就采集走 a1.sources.r1.command = tail -F /bigdata/data/flume/tail.log #指定source的数据流入的channel中 a1.sources.r1.channels = c1 #配置channel #指定channel的类型为file a1.channels.c1.type = file a1.channels.c1.checkpointDir = /bigdata/data/flume/flume_checkpoint #数据存储所在的目录 a1.channels.c1.dataDirs = /bigdata/data/flume/flume_data #配置sink a1.sinks.k1.channel = c1 #指定sink类型为hdfs a1.sinks.k1.type = hdfs #指定数据收集到hdfs的目录 a1.sinks.k1.hdfs.path = hdfs://node01:8020/tailFile/%Y-%m-%d/%H%M #指定生成文件名的前缀 a1.sinks.k1.hdfs.filePrefix = events- #开启时间舍弃 a1.sinks.k1.hdfs.round = true #设置时间舍弃的间隔,即文件的间隔时间为10 a1.sinks.k1.hdfs.roundValue = 10 #设置时间舍弃的单位 a1.sinks.k1.hdfs.roundUnit = minute # 控制文件个数,滚动生成文件 #60s或者50字节或者10条数据,谁先满足,就开始滚动生成新文件 #这个单位太小,仅能在测试的时候使用,并且不要开启太长时间 a1.sinks.k1.hdfs.rollInterval = 60 a1.sinks.k1.hdfs.rollSize = 50 a1.sinks.k1.hdfs.rollCount = 10 #定义每次写入的数据量 a1.sinks.k1.hdfs.batchSize = 100 #开始本地时间戳--开启后就可以使用%Y-%m-%d去解析时间 a1.sinks.k1.hdfs.useLocalTimeStamp = true #生成的文件类型,默认是Sequencefile,可用DataStream,则为普通文本 a1.sinks.k1.hdfs.fileType = DataStream -
启动agent
bin/flume-ng agent -n a1 -c myconf -f myconf/file2Hdfs.conf -Dflume.root.logger=info.console可以在集群的hdfs的文件系统中 hdfs://node01:8020/tailFile/%Y-%m-%d/%H%M 看到数据的流入
5.2 采集目录到HDFS
-
需求描述
一个目录中不断有新的文件产生,需要把目录中的文件不断地进行数据收集保存到HDFS上
-
Flume配置文件
vim dir2Hdfs.conf
# Name the components on this agent a1.sources = r1 a1.sinks = k1 a1.channels = c1 # 配置source ##注意:不能往监控目中重复丢同名文件 #flume会把传输完的文件重名成*.COMPLETED a1.sources.r1.type = spooldir a1.sources.r1.spoolDir = /bigdata/data/flume/files # 是否将文件的绝对路径添加到header a1.sources.r1.fileHeader = true a1.sources.r1.channels = c1 #配置channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 #配置sink a1.sinks.k1.type = hdfs a1.sinks.k1.channel = c1 a1.sinks.k1.hdfs.path = hdfs://node01:8020/spooldir/%Y-%m-%d/%H%M a1.sinks.k1.hdfs.filePrefix = events- a1.sinks.k1.hdfs.round = true a1.sinks.k1.hdfs.roundValue = 10 a1.sinks.k1.hdfs.roundUnit = minute a1.sinks.k1.hdfs.rollInterval = 60 a1.sinks.k1.hdfs.rollSize = 50 a1.sinks.k1.hdfs.rollCount = 10 a1.sinks.k1.hdfs.batchSize = 100 a1.sinks.k1.hdfs.useLocalTimeStamp = true #生成的文件类型,默认是Sequencefile,可用DataStream,则为普通文本 a1.sinks.k1.hdfs.fileType = DataStream -
启动agent
bin/flume-ng agent -n a1 -c myconf -f myconf/dir2Hdfs.conf -Dflume.root.logger=info.console可以在集群的hdfs的文件系统中 hdfs://node01:8020/tailFile/%Y-%m-%d/%H%M 看到数据的流入
如果源目录放入了同名的文件回报如下错误
java.lang.IllegalStateException: File name has been re-used with different files. Spooling assumptions violated for /bigdata/data/flume/files/a.txt.COMPLETED at org.apache.flume.client.avro.ReliableSpoolingFileEventReader.rollCurrentFile(ReliableSpoolingFileEventReader.java:463) at org.apache.flume.client.avro.ReliableSpoolingFileEventReader.retireCurrentFile(ReliableSpoolingFileEventReader.java:414) at org.apache.flume.client.avro.ReliableSpoolingFileEventReader.readEvents(ReliableSpoolingFileEventReader.java:326) at org.apache.flume.source.SpoolDirectorySource$SpoolDirectoryRunnable.run(SpoolDirectorySource.java:250) at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511) at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:308) at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$301(ScheduledThreadPoolExecutor.java:180) at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:294) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748)