本文内容:
- 本章内容小结
- 完成作业或实践时解决困难的经验分享
- 参考资料、说明推荐理由及列出相关链接(或书目名称,具体页码)
- 目前学习过程中存在的困难,待解决或待改进的问题
- 接下来的目标
一、本章内容小结:(栈与队列)
(1)基本概念:
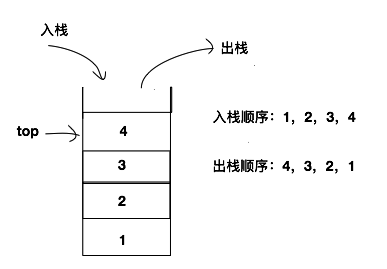
栈(Stack):只允许在一端进行插入或删除操作的线性表。首先栈是一种线性表,但是限定这种线性表只能在某一端进行插入和删除操作
栈顶(top):线性表允许进行插入和删除的那一端。(开口的那一端)
栈底(bottom):固定的,不允许进行插入和删除的另一端。(封死的那一端)
空栈:不含任何元素的空表。
栈的两种表示方式:栈的本质是线性表,那么它就同样有线性表的两种表示形式:顺序栈 和 链式栈(简称“链栈”)
两者的区别:存储的数据元素在物理结构上是否是相互紧挨着的。顺序栈存储元素预先申请连续的存储单元;链栈需要即申请,数据元素不紧挨着。
栈的“上溢”和“下溢”问题:
“上溢”:在栈已经存满数据元素的情况下,如果继续向栈内存入数据,栈存储就会出错。(栈满还存会“上溢”)
“下溢”:在栈内为空的状态下,如果对栈继续进行取数据的操作,就会出错。(栈空再取会“下溢”)
对于栈的两种表示方式来说,顺序栈两种情况都有可能发生;而链栈由于“随时需要,随时申请空间”的存储结构,不会出现“上溢”的情况。
栈的基本操作:
InitStack(&S):初始化一个空栈S。
StackEmpty(S):判断一个栈是否为空,若栈S为空返回true,否则返回false。
Push(&S, x):进栈,若栈S未满,将x加入使之成为新桟顶。
Pop(&S, &x):出栈,若栈S非空,弹出栈顶元素,并用x返回。
GetTop(S, &x):读栈顶元素,若栈S非空,用x返回栈顶元素。
ClearStack(&S):销毁栈,并释放栈S占用的存储空间。
注意:符号'&'是C++特有的,用来表示引用,有的书上釆用C语言中的指针类型‘*’,也可以达到传址的目的。
栈的特点:
先进后出
------------------------------------------------------------------------------------------------
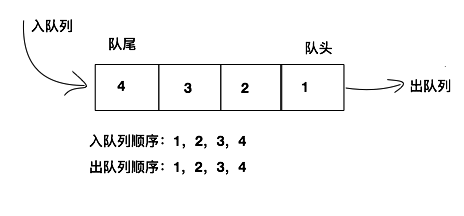
队列(Queue):队列简称队,也是一种操作受限的线性表,只允许在表的一端进行插入,而在表的另一端进行删除。
队头(Front):允许删除的一端,又称为队首。
队尾(Rear):允许插入的一端。
空队列:不含任何元素的空表。
队列常见的基本操作:
InitQueue(&Q):初始化队列,构造一个空队列Q。
QueueEmpty(Q):判队列空,若队列Q为空返回true,否则返回false。
EnQueue(&Q, x):入队,若队列Q未满,将x加入,使之成为新的队尾。
DeQueue(&Q, &x):出队,若队列Q非空,删除队头元素,并用x返回。
GetHead(Q, &x):读队头元素,若队列Q非空,则将队头元素赋值给X。
需要注意的是,队列是操作受限的线性表,所以,不是任何对线性表的操作都可以作为队列的操作。比如,不可以随便读取队列中间的某个数据。
队列的特点:
先进先出
(2)核心内容——顺序栈:
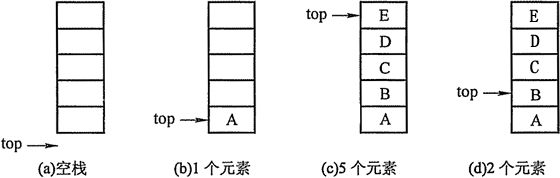
定义:栈的顺序存储称为顺序栈,它是利用一组地址连续的存储单元存放自栈底到栈顶的数据元素,同时附设一个指针(top)指示当前栈顶的位置。
①定义:
#define MaxSize 50 //定义栈中元素的最大个数 typedef struct{ Elemtype data[MaxSize]; //存放栈中元素 int top; //栈顶指针 }SqStack;
②初始化:
void initStack(Sqstack &st) { st.top=-1; //初始化栈顶指针 }
③ 判断是否为空
void isEmpty(Sqstack st) { if(st.top==-1) //栈空 return 1; else //不空 return 0; }
④ 进栈
int push(Sqstack &st,int &x) { if(st.top==maxSize-1) //栈满,报错 return 0; ++(st.top); //指针先加 1(先移动指针),再进栈 st.data[st.top]=x; return 1; }
⑤ 出栈
int pop(Sqstack &st,int &x) { if(st.top==-1) //栈空,报错 return 0; x=st.data[st.top]; //先出栈,指针再减1(先取出元素,在移动指针) --(st.top); return 1; }
⑥ 读栈顶元素
bool GetTop(SqStack S,ElemType &x){ if (S.top==-1) //找空,报错 return false; x=S.data[S.top]; //x记录栈顶元素 return true; }
⑦ 优化纯数组实现
//1.初始化 int stack[maxSize]; int top=-1; //2.进栈 stack[++top]=x; //3.出栈 x=stack[--top];
(3)附加内容:共享栈
PTA作业有这么一道题:

引出:共享栈
利用栈底位置相对不变的特性,可以让两个顺序栈共享一个一维数据空间,将两个栈的 栈底分别设置在共享空间的两端,两个栈顶向共享空间的中间延伸。

两个栈的栈顶指针都指向栈顶元素,top0=-1 时0号桟为空,top1=MaxSize时1号栈为空;仅当两个栈顶指针相邻(top1-top0=1) 时,判断为栈满。当0号栈进栈时top0先加1 再赋值,1号栈进栈时top1先减1再赋值;出栈时则刚好相反。
共享栈是为了更有效地利用存储空间,两个栈的空间相互调节,只有在整个存储空间被 占满时才发生上溢。其存取数据的时间复杂度均为0(1),所以对存取效率没有什么影响。
(4)核心内容——链栈
釆用链式存储的栈称为链栈,链栈的优点是便于多个栈共享存储空间和提高其效率,且 不存在栈满上溢的情况。通常釆用单链表实现,并规定所有操作都是在单链表的表头进行的。 这里规定链栈没有头结点(链栈一般不需要创建头结点,头结点会增加程序的复杂性,只需要创建一个头指针就可以了),Lhead指向栈顶元素。

① 初始化(这里我们以含头结点的链栈为例)
void initStack(LNode*&lst) //lst要改变,用引用型 { lst=(LNode*)malloc(sizeof(LNode)); //创建一个头结点 lst->next=NULL; }
② 判断是否为空
void isEmpty(Sqstack *lst) { if(lst->next==NULL) //栈空 return 1; else //不空 return 0; }
③ 进栈
int push(Sqstack *lst,int x) { LNode *p; p=(LNode*)malloc(sizeof(LNode)); //为进栈元素申请结点空间(默认内存无限大) p->next=NULL; //初始化(没新申请一个结点,将其指针域设置为NULL) //以下是单链表的头插法 p->next =x; p->next =lst->next; lst->next=p; }
④ 出栈
int pop(Sqstack *lst,int &x) { LNode *p; if(lst->next==NULL) //栈空不能出栈 return=0; //以下是单链表的删除操作 p=(LNode*)malloc(sizeof(LNode)); //为进栈元素申请结点空间 p->next=NULL; //初始化(没新申请一个结点,将其指针域设置为NULL) //以下是链表的头插法 p = lst->next; x=p->data; lst->next=p->next; free(p); return 1; }
-----------------------------------------------------------------------------------------------------
(5)核心内容——顺序队列
实现比较简单,就直接贴上了:本质也是直接使用数组。
#define MaxSize 50 //定义队列中元素的最大个数 typedef struct{ ElemType data[MaxSize]; //存放队列元素 int front, rear; //队头指针和队尾指针 }SqQueue;
(6)附加内容——循环队列
在PTA作业中,我们还遇到了这么一个问题:

这道题使用循环链表是存储方式比较理想的一种了。
循环队列是一个附加知识,也是充分利用资源的一种数据结构。
为了解决顺序队列的缺点将顺序队列变为一个环状的空间,即把存储队列元素的表从逻辑上看成一个环,称为循环队列。当队首指针Q.ftont =MaxSiZe-1后,再前进一个位置就自动到0,这可以利用除法取余运算(%)来实现。
初始时:Q.front=Q.rear=0
队首指针进 1:Q.front=(Q.front+1)%MaxSize
队尾指针进 1:Q.rear=(Q.rear+1)%MaxSize
队列长度:(Q.rear+MaxSize-Q.front)%MaxSize
出队入队时:指针都按顺时针方向进1
(7)核心内容:链队
队列的链式表示称为链队列,它实际上是一个同时带有队头指针和队尾指针的单链表。头指针指向队头结点,尾指针指向队尾结点,即单链表的最后一个结点。

不设头结点的链式队列在操作上往往比较麻烦,因此,通常将链式队列设计 成一个带头结点的单链表,这样插入和删除操作就统一了。
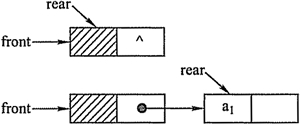
用单链表表示的链式队列特别适合于数据元素变动比较大的情形,而且不存在队列满且产生溢出的问题。另外, 假如程序中要使用多个队列,与多个栈的情形一样,最好使用链式队列,这样就不会出现存储分配不合理和“溢出” 的问题。
①初始化
void InitQueue(LinkQueue &Q) { Q.front = Q.rear=(LinkNode*)malloc(sizeof(LinkNode)); //创建头结点 Q.front->next=NULL; //初始为空 }
② 判队空
bool IsEmpty(LinkQueue Q) { if(Q.front==Q.rear) return true; else return false; }
③入队
③入队 void EnQueue(LinkQueue &Q, ElemType x) { s=(LinkNode *)malloc(sizeof(LinkNode));//创建新结点 s->data=x; s->next=NULL; Q.rear->next=s; //插入到链尾 Q.rear=s; }
④出队
bool DeQueue(LinkQueue &Q, ElemType &x) { if (Q.front == Q.rear) return false; //空队 p=Q.front->next; x=p->data; Q.front->next=p->next; if(Q.rear==p) Q.rear=Q.front; //若原队列中只有一个结点,删除后变空 free(p); return true; }
注解:代码均以C/C++构建,有空再写个JAVA的。
二、章后反思
第三章涉及新的数据结果——栈与队列,是处理问题的非常好用的工具,在这周末的天梯赛也用到了不少。
这周末打了一波天梯赛,第一次的比赛,还是蛮有收获的,暴露出了自己的很多问题:
①比赛的题型攻略方向,根据大家的答题情况实时调整答题情况。
②基础算法的不牢固,深搜dfs、最小生成树等等。
③答题心态和日常学习,刷题量还是不够,还需要继续加强。
ACM组队组了个最强队瞬间压力巨大,要花在算法学习上的时间就要更多了。
昂就酱紫 加油秃头去了~