本文索引目录:
一、PTA实验报告题1 : 二分查找
1.1 实践题目
1.2 问题描述
1.3 算法描述
1.4 算法时间及空间复杂度分析
二、PTA实验报告题2 : 改写二分搜索算法
2.1 实践题目
2.2 问题描述
2.3 算法描述
2.4 算法时间及空间复杂度分析
三、PTA实验报告题3 : 两个有序序列的中位数
3.1 实践题目
3.2 问题描述
3.3 算法描述
3.4 算法时间及空间复杂度分析
四、实验心得体会(实践收获及疑惑)
一、PTA实验报告题1 : 二分查找
1.1 实践题目:

1.2 问题描述:
这道题主要阐述,给你一段有序的数字序列(已经排好序了),并给出需要查找的数Value,利用二分查找发法找出Value所在的下标,以及查找过程中所比较的次数。
1.3 算法描述:
二分查找的定义:
二分查找也称折半查找(Binary Search),它是一种效率较高的查找方法。
折半查找要求线性表必须采用顺序存储结构,而且表中元素按关键字有序排列。
二分查找的操作:
假如以本例的样例来说,具体操作流程如下:
首先得到了一段数字序列,存入空间Temp:

将这段Temp数组送入递归中,赋值左右指针为0和3(下标)
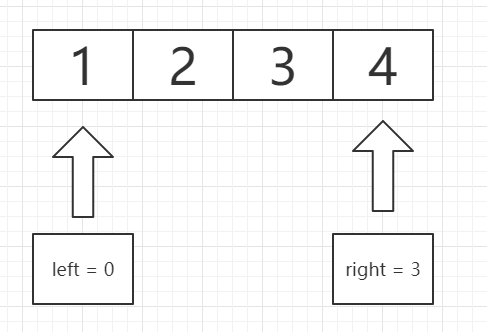
求得left与right的中间下标mid = ( l + r) >> 1,mid结果是向下取整的,得注意一下!
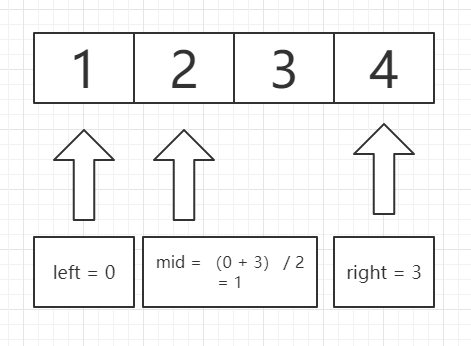
得到中间下表mid之后,对mid所在的数,跟value值,进行比较,如果小了,那么就送入递归(mid +1 ,right)
如果比value值大了,那么就送入递归(left,mid)区间。
在此处,temp【mid】 = 2,大于题目给的value,所以,我们送入递归(0,1)中,剩下的数字就不管了。
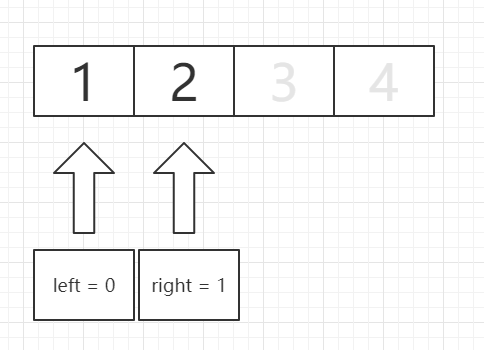
此时发现mid = (0 + 1 )/ 2 = 0, 所在的值与题干的value值 相等,从此return返回,到此总共比较2次。
下面是代码展示:
#include<bits/stdc++.h> using namespace std; int temp,x,ans,cnt,mark[99999999]; int getAns(int l,int r) { cnt++; if(l >= r)
return l; int mid = (l + r) / 2; if(mark[mid] == x)
return mid; if(x<=mark[mid]) return getAns(l,mid-1); else
return getAns(mid+1,r); } int main() { cin>>temp; for(int i = 0;i<temp;i++) cin>>mark[i]; cin>>x; ans = getAns(0,temp-1); if(mark[ans] != x) ans = -1; cout<<ans<<endl; cout<<cnt<<endl; }
1.4 算法时间及空间复杂度分析:
整体算法上看,二分算法是不断折半查找,不断折半,所以时间复杂度是以2为底的系数,也就是O(log2 n)的复杂度。
再加上特判的一些处理,以及输出的处理,都是在O(1)的复杂度,所以综合起来,时间复杂度是O(logn)。
空间复杂度上,使用一个与问题规模一致的Temp数组空间,并且使用了三个临时变量,整体来说没有开辟新的辅助空间。
所以空间复杂度是O(1)。
二、PTA实验报告题2 : 改写二分搜索算法:
2.1 实践题目:

2.2 问题描述:
第二题是二分算法的一个小小改进,不过做了一个变化,就是不存在指定数value时,就输出小于x的最大元素位置i和大于x的最小元素位置j,如果存在这个数,就直接输出i,j,且i == j。
2.3 算法描述:
首先,读题:就是不存在指定数value时,就输出小于x的最大元素位置i和大于x的最小元素位置j,其实在这里可以发现,当二分递归出来的结果l,即使找不到,也是小于x的最大元素位置i,那么求大于x的最小元素位置j只需要加1即可,对于特别的点,只需要进行一些简单的特判,就可以过了。
#include<bits/stdc++.h> using namespace std; int temp,x,ans,cnt,mark[99999999]; int getAns(int l,int r) { cnt++; if(l >= r)
return l; int mid = (l + r) / 2; if(mark[mid] == x)
return mid; if(x<=mark[mid])
return getAns(l,mid-1); else
return getAns(mid+1,r); } int main() { cin>>temp>>x; for(int i = 0;i<temp;i++) cin>>mark[i]; ans = getAns(0,temp-1); if(mark[ans] != x) { if(ans == 0) cout<<"-1 0"; else cout<<ans<<" "<<ans+1; return 0; } cout<<ans<<" "<<ans<<endl; return 0; }
2.4 算法时间及空间复杂度分析:
算法复杂度依旧和第一题一样,本质都是二分搜索,时间复杂度为O(log n)
空间复杂度上,依旧用了四个临时变量并使用一个与问题规模同大的Temp数组,整体来说没用使用额外的辅助空间,空间复杂度为O(1)。
三、PTA实验报告题3 : 两个有序序列的中位数:
3.1 实践题目:
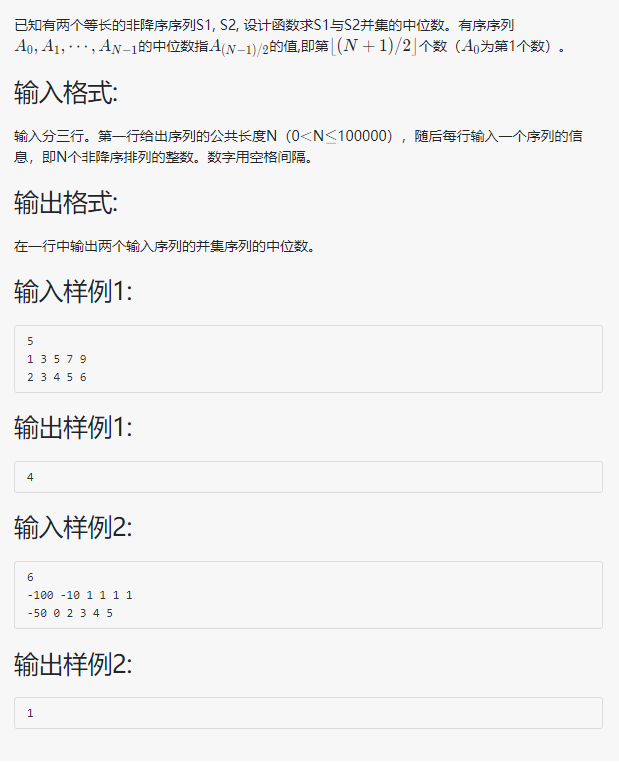
3.2 问题描述:
该题目为:题干给你两段有序的数字序列,想办法使用logn的算法实现找出两段合并后的序列内的中位数。
3.3 算法描述:
这道题我一上来的想法思路就是用排序然后取值,但是这样的时间复杂度就会到O(nlogn),超出了题目所限制的时间复杂度,于是我们需要另外思考一个新的办法,那就是使用二分搜索,对不同的两段数学分别求解中位数:
①如果两段序列的中位数,都是相等的话,那么中位数即为该数。
②如果当第一段的中位数大于第二段的时候,那么两端合中位数一定在第一段中位数前或第二段中位数后,这时只取这两部分,再继续进行二分比较
③如果当第一段的中位数小于第二段的时候,那么两端合中位数一定在第一段中位数后面或第二段中位数前面,这时只取这两部分,再继续进行二分比较
这里我需要用一下我同伴做的一张图,我觉得做的还不错,特地分享一下:
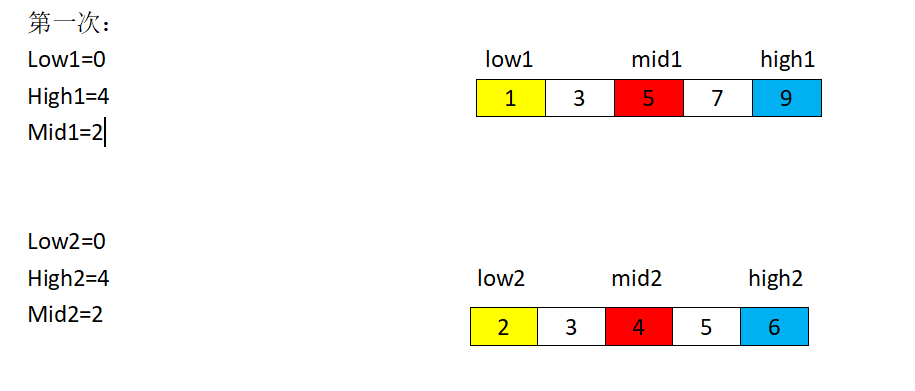
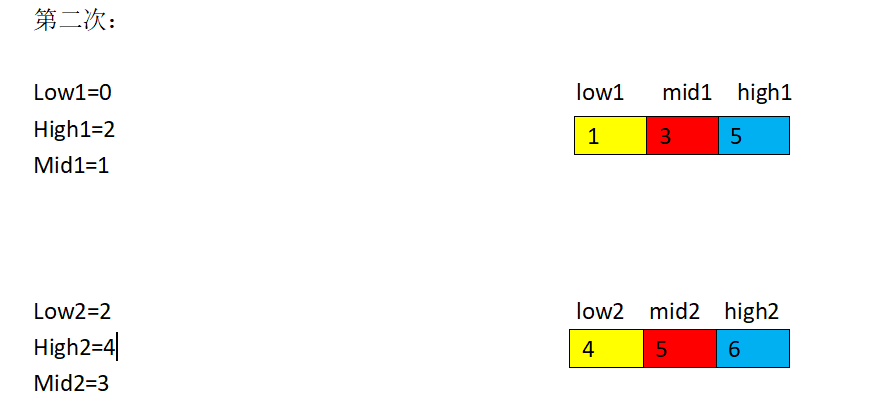
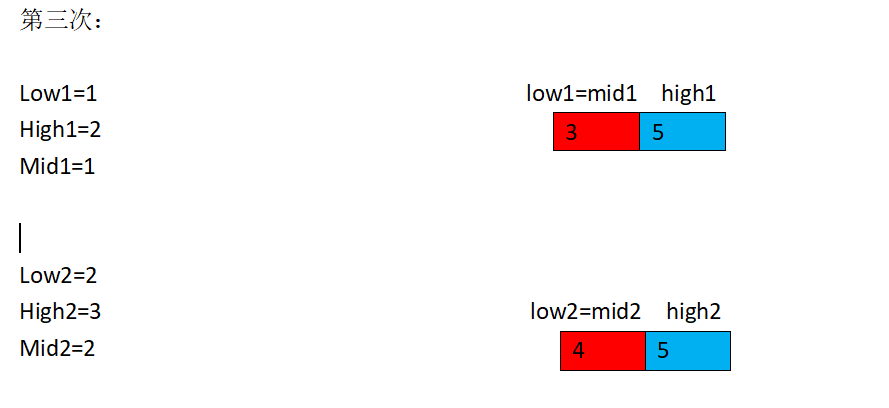
AC代码:
#include<iostream> using namespace std; int n,a[100000],b[100000]; int getAns(int a[],int b[],int n) { int l1 = 0, l2 = 0, r1 = n - 1, r2 = n - 1; while(l1 < r1 && l2 < r2) { int mid1 = (l1 + r1) / 2; int mid2 = (l2 + r2) / 2; if (a[mid1] == b[mid2]) return a[mid1]; if (a[mid1] < b[mid2]) { if ((l1 + r1) % 2 == 0) { l1 = mid1; r2 = mid2; } else { l1 = mid1 + 1; r2 = mid2 ; } } else { if ((l1 + r1) % 2 == 0) { r1 = mid1; l2 = mid2; } else { r1 = mid1; l2 = mid2 +1; } } }; if (a[l1] < b[l2]) cout << a[l1] << endl; else cout << b[l2] << endl; } int main() { cin >> n; for (int i = 0; i < n; i++) cin >> a[i]; for (int i = 0; i < n; i++) cin >> b[i]; getAns(a, b, n); return 0; }
3.4 算法时间及空间复杂度分析:
因为采用二分查找算法来寻找中位数而不是排序,所以时间复杂度为O(logn)。
依旧用了四个临时变量并使用两个与问题规模同大的数组,没用使用其他的辅助空间,所以空间复杂度为O(1)。
四、实验心得体会(实践收获及疑惑):
二分搜索看起来思路挺简单的,但是在执行过程中,总会有一些细节上的小错误,在这次的实验过程种也感受到了:
① 边界点的等号是否取到,中间点的位置是否可取
② 二分的对象该如何妥当处理
等等的细节问题,在我日常ACM打题时也有遇到像double浮点数,处理上可能会更麻烦一点点,除此之外,二分还只是最基础的算法,更多的还有三分,尺取法等。最核心的思想也就是,分而治之:
也在一些书籍找到一些关于分治算法的解释:
分治算法是递归的解决问题的一般步骤为:
(1)找出基线条件,这种条件必须尽可能简单
(2)不断将问题分解(或者说缩小规模),直到符合基线条件。
(3)按原问题的要求,判断子问题的解是否就是原问题的解,或是需要将子问题的解逐层合并构成原问题的解。
分治法的设计思想是,将一个难以直接解决的大问题,分割成一些规模较小的相同问题,以便各个击破,分而治之。
如有错误不当之处,烦请指正。