很多时候在数据分析之前,我们需要对样本进行校验,以确定样本的价值。
先写入数据:
import pandas as pd import numpy as np df = pd.DataFrame({'一班':[90,80,66,75,99,55,76,78,98,None,90], '二班':[75,98,100,None,77,45,None,66,56,80,57], '三班':[45,89,77,67,65,100,None,75,64,88,99]})
1完整性校验
# 判断是否为缺失值(空值) df.isnull()
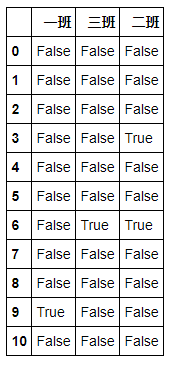
# 统计出每一列的缺失值数目 df.isnull().sum()

# 每一列缺失比例 df.isnull().sum()/df.shape[0]
# 判断非空值的数目 df.notnull().sum()

笔记:这里也可以用到describe方法,如下:
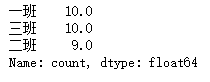
# 使用describe方法查看数据的完整性,统计出了非空值的数目 df.describe().iloc[0,:]
忘了describe方法的话,请查看《Python之Pandas知识点》
2时间跨度检验
很多样本的时间数据并不是以datatime64类型存储的,此时我们得先进行“数据类型修改”
详见:《Python之Pandas知识点》的4.3数据修改
之后进行最大最小相减就OK了。
print(date.max()-date.min())

3重复检验
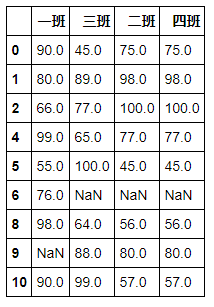
# 二班和四班是相同的 df1 = pd.DataFrame({'一班':[90,80,66,90,99,55,76,90,98,None,90], '二班':[75,98,100,75,77,45,None,75,56,80,57], '三班':[45,89,77,45,65,100,None,45,64,88,99], '四班':[75,98,100,75,77,45,None,75,56,80,57]})
3.1样本重复检验(行)
DataFrame.drop_duplicates(subset=None, keep='first', inplace=False)
- subset:表示以这几个特征为基础,对整体样本进行去重。默认为使用所有特征
- keep:表示保留第几个重复的样本。只允许填入first(保留第一个),last(保留最后一个),False(只要存在重复均不保留)。默认为first
- inplace:表示是否在原DataFrame上进行操作,会改变原数据。默认为False
# 删除重复样本(行) df1.drop_duplicates()
# 计算样本重复率 (df1.shape[0] - df1.drop_duplicates().shape[0])/df1.shape[0]

3.2特征重复检验(列)
特征重复检验相比样本重复检验要麻烦一点,因为没有现成的函数可调用。
需要用到相似度的概念,如下:
- pearson相似度
- spearman相似度
- kendall相似度
# 使用pandas的方法:DataFrame.corr(method='pearson') asso = df1.corr()
# 输出asso,看一下是怎样的先 print(asso)

不难看出,这是一个对称矩阵,所以我们只需要判断右上半角的数据便可。
# 输出应删除的columns,1.0可根据需求改动 delCol = [] for i in range(len(asso)): for j in range(i+1,len(asso)): if asso.iloc[i,j] == 1.0: delCol.append(asso.columns[j]) print(delCol)

最后,附上一段 ♦特征重复检验♦ 的自定义代码:
# 输入DataFrame,输出特征重复的列名,可直接复制调用 def drop_features(data,way = 'pearson',assoRate = 1.0): ''' 此函数用于求取相似度大于assoRate的两列中的一个,主要目的用于去除数值型特征的重复 data:数据框,无默认 assoRate:相似度,默认为1 ''' assoMat = data.corr(method = way) delCol = [] length = len(assoMat) for i in range(length): for j in range(i+1,length): if asso.iloc[i,j] >= assoRate: delCol.append(assoMat.columns[j]) return(delCol)
效果如下:
drop_features(df1)
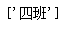
是不是超好用,巨方便~~~不谢