node_exporter部署
软件包版本
node_exporter-0.18.1.linux-amd64.tar.gz
详细操作
解压链接
[root@server02 ~]# mkdir /opt/src [root@server02 src]# tar -xvf node_exporter-0.18.1.linux-amd64.tar.gz -C /opt/ [root@server02 src]# cd /opt/ [root@server02 opt]# ln -s node_exporter-0.18.1.linux-amd64/ node_exporter
创建用户并授予权限
[root@server02 opt]# groupadd prometheus [root@server02 opt]# useradd -g prometheus -s /sbin/nologin prometheus [root@server02 opt]# chown -R prometheus:prometheus /opt/node_exporter
配置启动文件
[root@server02 opt]# vi /usr/lib/systemd/system/node_exporter.service [Unit] Description=node_exporter Documentation=https://prometheus.io/ After=network.target [Service] Type=simple User=prometheus ExecStart=/opt/node_exporter/node_exporter --collector.systemd --collector.systemd.unit-whitelist=(docker|sshd).service --collector.textfile.directory /var/lib/node_exporter/textfile_collector/ Restart=on-failure [Install] WantedBy=multi-user.target [root@server02 opt]# systemctl enable node_exporter [root@server02 opt]# systemctl start node_exporter
配置textfile收集器(启动文件已添加该配置)
textfile收集器非常有用, 因为它允许我们暴露自定义指标。
[root@server02 opt]# mkdir -p /var/lib/node_exporter/textfile_collector
现在在这个目录中创建一个新的指标。刚创建的目录中,指标在以.prom结尾的文件内定义,并且使用Prometheus特定文本格式
[root@server02 opt]# vi /var/lib/node_exporter/textfile_collector/metadata.prom
metadata{role="docker_server",datacenter="NJ"} 1
node_exporter启动参数添加 --collector.textfile.directory /var/lib/node_exporter/textfile_collector/
表示只收集docker和sshd服务数据
启动参数添加 --collector.systemd.unit-whitelist="(docker|sshd).service"
抓取Node Exporter
[root@server01 prometheus]# vi prometheus.yml
- job_name: 'node'
static_configs:
- targets: ['10.4.7.11:9100']
[root@server01 prometheus]# curl http://10.4.7.11:9100/metrics
过滤收集器
- job_name: 'node'
static_configs:
- targets: ['10.4.7.11:9100']
params:
collect[]:
- cpu
- meminfo
- diskstats
- netdev
- netstat
- filefd
- filesystem
- xfs
- systemd
使用Node Exporter实例上的curl命令来对此进行测试
[root@server01 prometheus]# curl -g -X GET http://10.4.7.11:9100/metrics?collect[]=cpu
热重启prometheus
[root@server01 prometheus]# kill -HUP pid
cAdvisor部署
[root@server02 ~]# docker run --volume=/:/rootfs:ro --volume=/var/run:/var/run:rw --volume=/sys:/sys:ro --volume=/var/lib/docker/:/var/lib/docker:ro --publish=8080:8080 --detach=true --name=cadvisor google/cadvisor:latest
让我们稍微分解查看下这个docker run命令。首先,我们在容器内挂载了几个目录。目录分为两种 类型,第一种是只读的,cAdvisor将从中收集数据,例如/sys目录:
--volume=/sys:/sys:ro
第二种类型是可读写的,是Docker套接字的挂载,通常位于/var/run目录中。我们还将容器内部的8080端口映射到主机上的8080端口,你可以用任何适合的端口来覆盖它。我们使用参数--detach以守护进程方式运行容器,并将容器命名为cadvisor。最后,我们使用带有latest标签的google/cadvisor图像。
使用10.4.7.11:8080访问页面,采集接口10.4.7.11:8080/metrics
prome节点
[root@server01 ~]# vi /opt/prometheus/prometheus.yml
- job_name: 'docker'
static_configs:
- targets: ['10.4.7.11:8080']
[root@server01 ~]# kill -HUP 15916
Node Exporter和cAdvisor指标
CPU使用率
页面查找 node_cpu_seconds_total
node_cpu_seconds_total{cpu="1",instance="10.4.7.11:9100",job="node",mode="user"}
node_cpu_seconds_total指标包含许多标签,包括instance和job标签,分别标识它来自哪个主机以及 被哪个作业抓取。
我们还有两个特定于CPU的标签:从某个CPU(例如cpu0)收集的cpu指标和用于测量的CPU模式(例如user、system、idle等)的mode指标。数据从/proc/stat中抽取,并以计数的形式告诉我们每个 CPU在每种模式下使用了多少秒。
首先计算每种CPU模式的每秒使用率。PromQL有一个名为irate的函数,用于计算范围向量中时间 序列增加的每秒即时速率。
irate(node_cpu_seconds_total{job="node"}[5m])
这将在irate函数中使用node_cpu_seconds_total指标并查询5分钟范围的数据。它将从node作业返回每个CPU在每种模式下的列表,表示为5分钟范围内的每秒速率。
avg(irate(node_cpu_seconds_total{job="node"}[5m])) by (instance)
生成主机CPU使用率,但这个指标还是不太准确,它仍然包括idle的值,并且它没有表示成百分比的形式。我们将查询每个实例的idle使用率,因为它已经是一个比率,将它乘以100可以转换为百分比。
avg(irate(node_cpu_seconds_total{job="node",mode="idle"}[5m])) by (instance) * 100
使用100减去该值就是CPU的使用率
100 - avg(irate(node_cpu_seconds_total{job="node",mode="idle"}[5m])) by (instance) * 100
CPU饱和度
在主机上获得CPU饱和的一种方法是跟踪平均负载,实际上它是将主机上的CPU数量考虑在内的一段时间内的平均运行队列长度。平均负载少于CPU的数量通常是正常的,长时间内超过该数字的平 均值则表示CPU已饱和。
平均1分钟的负载值
node_load1
计算主机上的CPU数量,可以使用count聚合
count by (instance) (node_cpu_seconds_total{mode="idle"})
将此值与node_load1结合起来
node_load1 > on (instance) 2 * count by (instance) (node_cpu_seconds_total{mode="idle"})
内存使用率
为此,我们将 node_memory_MemFree_bytes、node_memory_Cached_bytes和node_memory_Buffers_bytes指标的值相加,这代表我们主机上的可用内存。然后我们将使用这个值和node_memory_MemTotal_bytes指标来计 算可用内存的百分比,使用以下查询:
(node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Cached_bytes + node_memory_Buffers_bytes)) / node_memory_MemTotal_bytes * 100
内存饱和度
我们还可以通过检查内存和磁盘的读写来监控内存饱和度。可以使用从/proc/vmstat收集的两个 Node Exporter指标:
- node_vmstat_pswpin:系统每秒从磁盘读到内存的字节数。
- node_vmstat_pswpout:系统每秒从内存写到磁盘的字节数。
为了获得饱和度指标,我们对每个指标计算一分钟的速率,将两个速率相加,然后乘以1024以获 得字节数。我们会创建一个查询来执行此操作。
1024 * sum by (instance) (rate(node_vmstat_pgpgin[1m]) + rate(node_vmstat_pgpgout[1m]))
磁盘使用率
(node_filesystem_size_bytes{mountpoint="/"} - node_filesystem_free_bytes{mountpoint="/"}) / node_filesystem_size_bytes{mountpoint="/"} * 100
不同目录修改mountpoint="/"就能解决
也可以通过predict_linear来预测未来什么时间资源耗尽
predict_linear(node_filesystem_free_bytes{job="node"}[1h], 4*3600) < 0
我们选择一小时的时间窗口[1h],并将此时间序列快照放在predict_linear函数中。该函数使用简单的线性回归,根据以前的增长情况来确定文件系统何时会耗尽空间。该函数参数包括一个范围向量,即一小时窗口,以及未来需要预测的时间点。这些都是以秒为单位的,因此这里使4*3600秒,即四小 时。最后<0过滤出小于0的值,即文件系统空间不足。
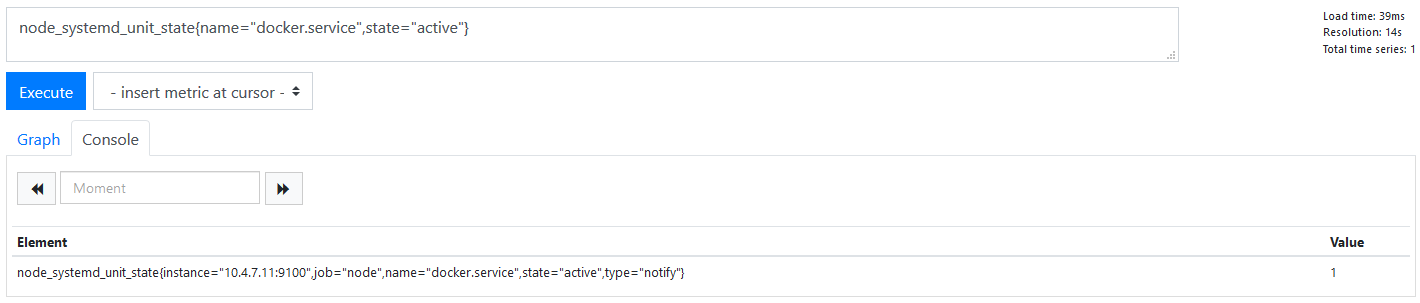
服务状态
过滤docker服务状态为 active
node_systemd_unit_state{name="docker.service",state="active"}
配置记录规则
[root@server01 prometheus]# mkdir -p rules
[root@server01 prometheus]# cd rules/
[root@server01 rules]# touch node_rules.yml
[root@server01 prometheus]# vi prometheus.yml
rule_files:
- "rules/node_rules.yml"
[root@server01 rules]# vi /opt/prometheus/rules/node_rules.yml
groups:
- name: node_rules
rules:
- record: instance:node_cpu:avg_rate5m
expr: 100 - avg (irate(node_cpu_seconds_total{job="node",mode="idle"}[5m])) by (instance) * 100
- record: instance:node_cpus:count
expr: count by (instance)(node_cpu_seconds_total{mode="idle"})
- record: instance:node_cpu_saturation_load1
expr: node_load1 > on (instance) 2 * count by (instance)(node_cpu_seconds_total{mode="idle"})
- record: instance:node_memory_usage:percentage
expr: (node_memory_MemTotal_bytes - (node_memory_MemFree + node_memory_Cached_bytes + node_memory_Buffers_bytes)) / node_memory_MemTotal_bytes * 100
- record: instance:node_memory_swap_io_bytes:sum_rate
expr: 1024 * sum by (instance) (
(rate(node_vmstat_pgpgin[1m])
+ rate(node_vmstat_pgpgout[1m]))
)
- record: instance:root:node_filesystem_usage:percentage
expr: (node_filesystem_size_bytes{mountpoint="/"} - node_filesystem_free_bytes{mountpoint="/"}) / node_filesystem_size_bytes{mountpoint="/"} * 100
覆盖全局更新规则时间
groups: - name: node_rules interval: 10s
页面输入record值

添加完后可通过promtools监测文件
[root@server01 ~]# ./promtool check rules rules/node_rules.yml
检测通过后需要重载prometheus配置文件
[root@server01 ~]# kill -HUP 2018