欢迎关注【无量测试之道】公众号,回复【领取资源】,
Python编程学习资源干货、
Python+Appium框架APP的UI自动化、
Python+Selenium框架Web的UI自动化、
Python+Unittest框架API自动化、
资源和代码 免费送啦~
文章下方有公众号二维码,可直接微信扫一扫关注即可。
什么是爬虫?
它是指向网站发起请求,获取资源后分析并提取有用数据的程序;
爬虫的步骤:

1、发起请求
使用http库向目标站点发起请求,即发送一个Request
Request包含:请求头、请求体等
2、获取响应内容
如果服务器能正常响应,则会得到一个Response
Response包含:html,json,图片,视频等
3、解析内容
解析html数据:正则表达式(RE模块),第三方解析库如Beautifulsoup,pyquery等
解析json数据:json模块
解析二进制数据:以wb的方式写入文件
4、保存数据
数据库(MySQL,Mongdb、Redis)文件
废话不多说,直接上代码截图(本文以抓取猫眼网站电影数据为示例):
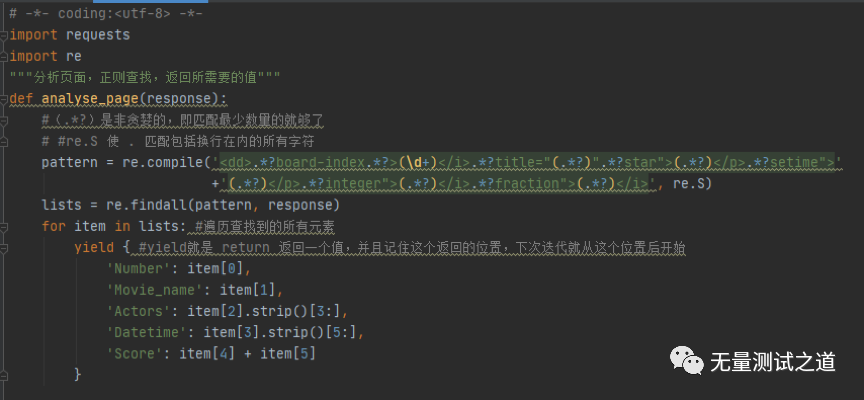
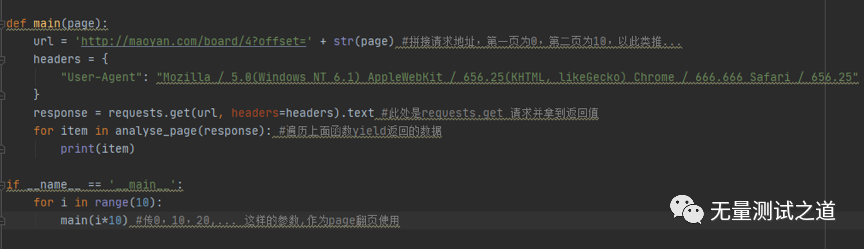
以下是执行后输出的结果:
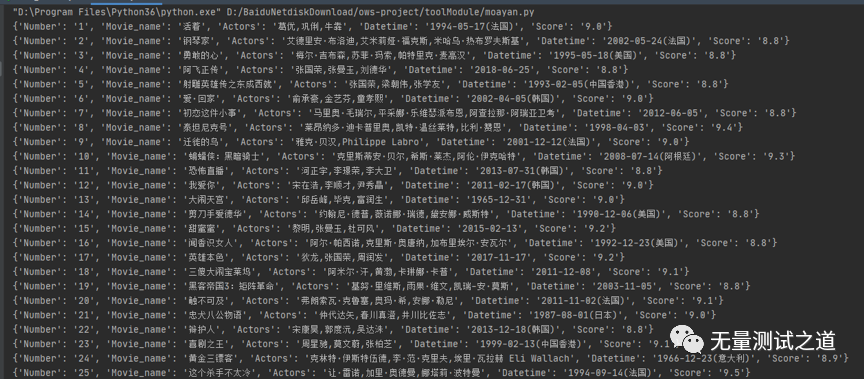
说明:代码截图中有详细的注释信息,所以不在文中再来说明代码中的用法。
备注:我的个人公众号已正式开通,致力于测试技术的分享,包含:大数据测试、功能测试,测试开发,API接口自动化、测试运维、UI自动化测试等,微信搜索公众号:“无量测试之道”,或扫描下方二维码:

添加关注,一起共同成长吧。