李宏毅老师的机器学习课程和吴恩达老师的机器学习课程都是都是ML和DL非常好的入门资料,在YouTube、网易云课堂、B站都能观看到相应的课程视频,接下来这一系列的博客我都将记录老师上课的笔记以及自己对这些知识内容的理解与补充。(本笔记配合李宏毅老师的视频一起使用效果更佳!)
Lecture 7: CNN
目录
一、CNN的引入
二、CNN的层次结构
三、CNN的小Demo加深对CNN的理解
四、CNN的特点
在学习本节课知识之前,先让我们来了解一下有关CNN的知识,让我们对CNN有一个大概的认知。卷积神经网络(Convolutional Neural Networks, CNN)是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),是深度学习(deep learning)的代表算法之一,被大量应用于计算机视觉、图片处理等领域。在CNN中,卷积层的神经元只与前一层的部分神经元节点相连,即它的神经元间的连接是非全连接的,且同一层中某些神经元之间的连接的权重 和偏移 是共享的(即相同的),这样大量地减少了需要训练参数的数量。
卷积神经网络CNN的结构一般包含这几个层:
输入层:用于数据的输入
卷积层:使用卷积核进行特征提取和特征映射
激励层:由于卷积也是一种线性运算,因此需要增加非线性映射
池化层:进行下采样,对特征图稀疏处理,减少数据运算量。
全连接层:通常在CNN的尾部进行重新拟合,减少特征信息的损失
输出层:用于输出结果
以上是最主要的层次结构,当然中间还可以使用一些其他的功能层:
归一化层(Batch Normalization):在CNN中对特征的归一化
切分层:对某些(图片)数据的进行分区域的单独学习
融合层:对独立进行特征学习的分支进行融合
接下来就进入我们的正题!
一、看完上面的介绍,肯定有人会有一下的疑问:
为什么CNN对图片处理有那么好的效果呢?
计算机又是如何识别我们人工输入的图片呢?
机器识图的过程:机器识别图像并不是一下子将一个复杂的图片完整识别出来,而是将一个完整的图片分割成许多个小部分,把每个小部分里具有的特征提取出来(也就是识别每个小部分),再将这些小部分具有的特征汇总到一起,就可以完成机器识别图像的过程了。
Why CNN for Image:CNN与全连接神经网络相比,其所用的参数少的多,那为什么CNN能够做到用更少的参数作图像处理反而得到更好的表现结果呢?这是因为图像具有以下三点特征:
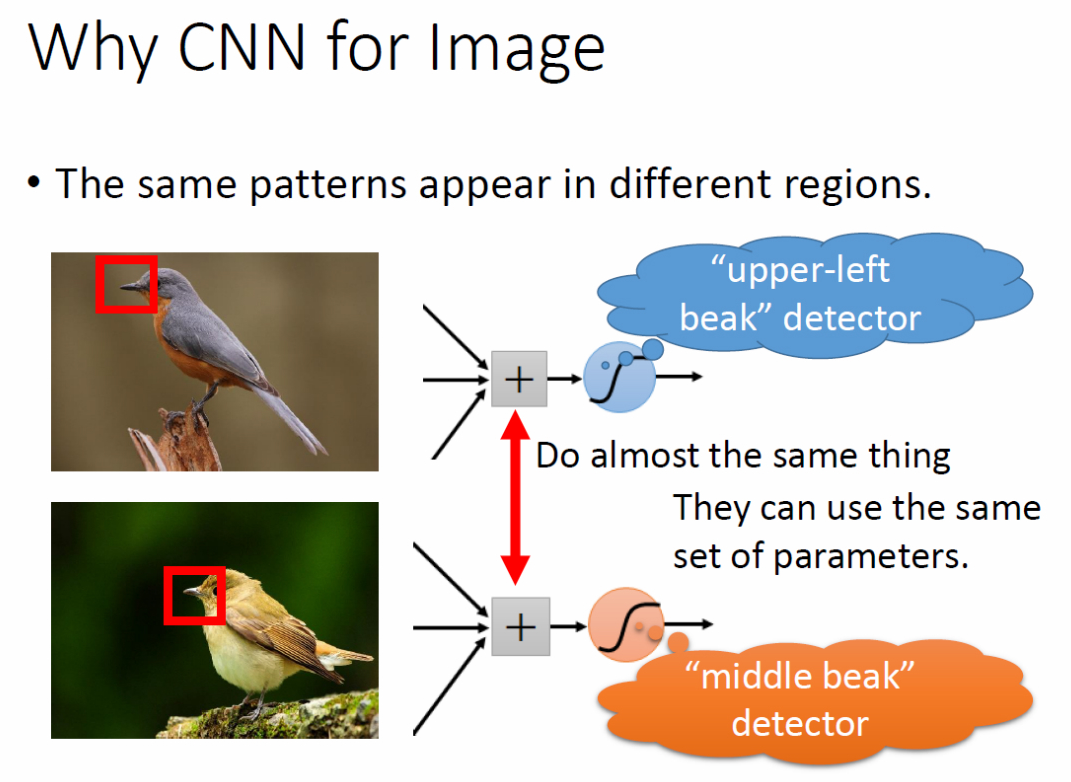
(1)一些模式比整张图片小得多,例如“鸟喙”就比整张图片小得多;

(2)同样的模式可能出现在图像的不同区域,例如“鸟喙”可能出现在图片的左上方也可能出现在图像的中间;
(3)对图像的降采样不会改变图像中的物体。

CNN的卷积层的设计对应着前两点,池化层的设计对应着第三点。

二、CNN的层次结构
1.卷积层
卷积说白了其实就是一种神经网络的连接方式,就是因为这种卷积的方式,才使得CNN的参数要比全连接神经网络的参数少得多。
(1)对于黑白,通道数为1的图片,卷积方式如下:



(2)对于彩色,通道数为3的图片
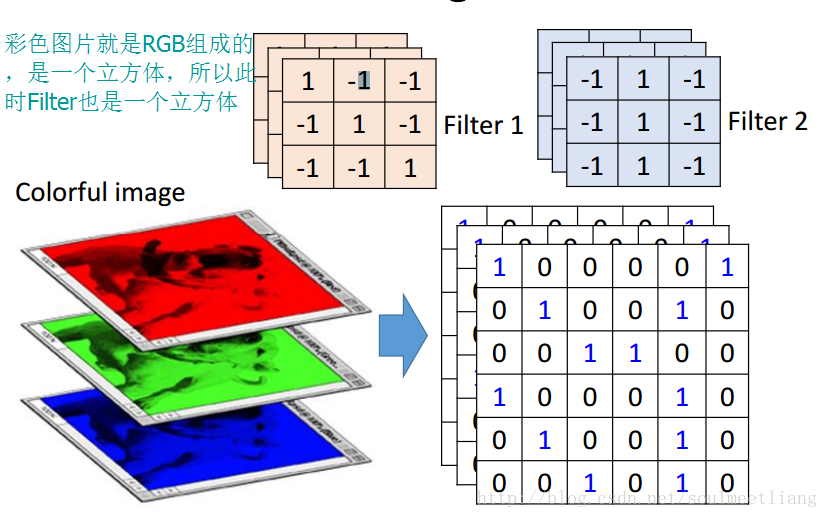
具体卷积过程(能帮助你更好的理解):http://cs231n.github.io/assets/conv-demo/index.html
(3)卷积和全连接方式的对比,体现出利用卷积的连接方式比全连接方式所需的参数更少。
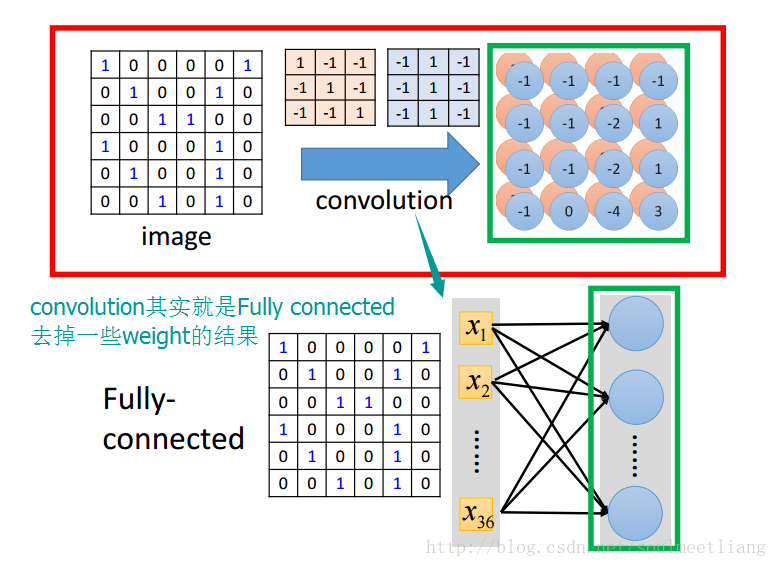
接下来,让我们换个角度去看待卷积的连接方式


(4)卷积层和激励层通常合并在一起称为“卷积层”
激励层主要对卷积层的输出进行一个非线性映射,然后把映射结果输入到池化层,因为卷积层的计算还是一种线性计算。使用的激励函数一般为ReLu函数:卷积层和激励层通常合并在一起称为“卷积层”。
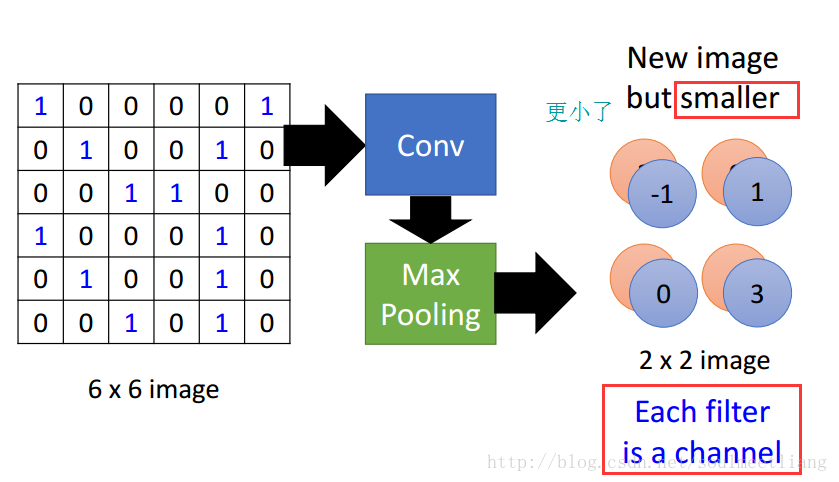
2.池化层
池化层又称下采样,它的作用是减小数据处理量同时保留有用信息
当输入经过卷积层时,若感受视野比较小,布长stride比较小,得到的feature map (特征图)还是比较大,可以通过池化层来对每一个 feature map 进行降维操作,输出的深度还是不变的,依然为 feature map 的个数。
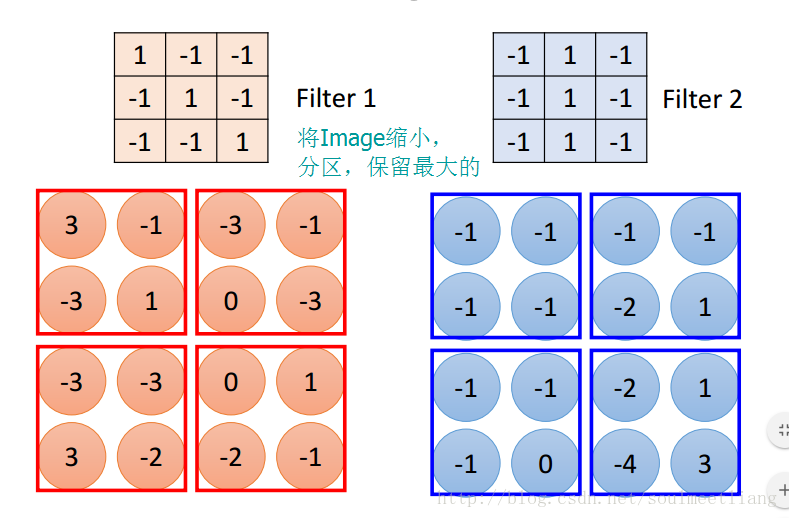
池化层也有一个“池化视野(filter)”来对feature map矩阵进行扫描,对“池化视野”中的矩阵值进行计算,一般有两种计算方式:
- Max pooling:取“池化视野”矩阵中的最大值
- Average pooling:取“池化视野”矩阵中的平均值
以Max pooling为例,见下图:

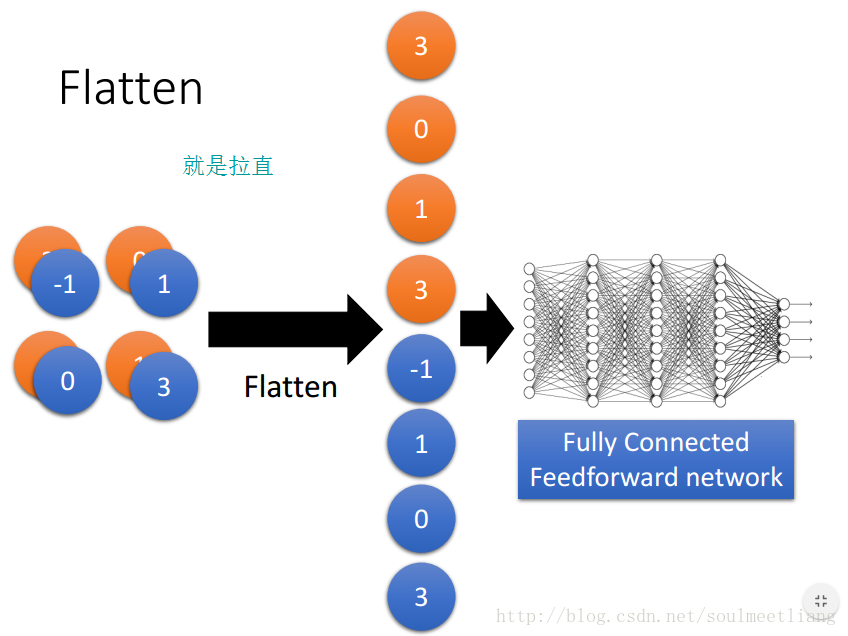
3.全连接层
作用:把所有局部特征结合变成全局特征,用来计算最后每一类的得分
换句话说全连接层就是把卷积层和池化层的输出展开成一维形式,在后面接上与普通网络结构相同的回归网络或者分类网络,一般接在池化层后面,如图所示;
4.输出层
输出层就不用介绍了,就是对结果的预测值,一般会加一个softmax,其损失函数一般为cross entropy。
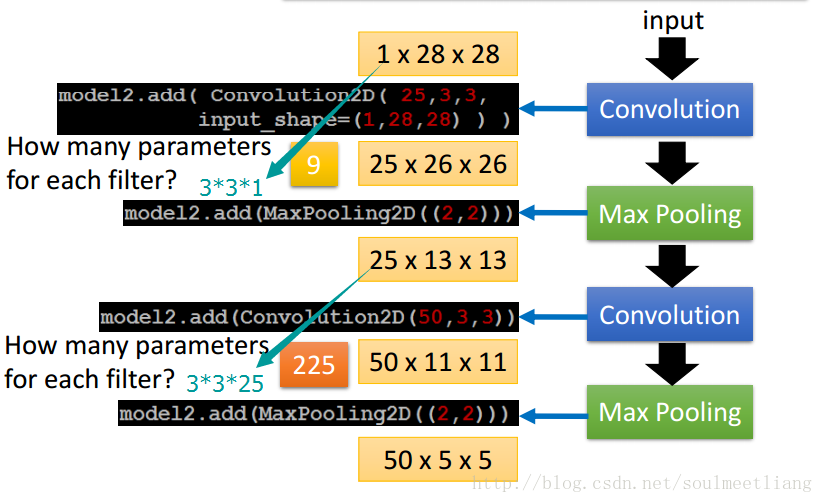
三、了解了CNN的层级结构,现在让我们通过一个Demo加深对CNN的理解
CNN作用于手写数字识别,有关这个Demo我博客有一篇有详细的介绍,欢迎跳转浏览。


四、CNN的主要特点
这里主要讨论CNN相比与传统的神经网络的不同之处,CNN主要有三大特色,分别是局部感知、权重共享和多卷积核
1.局部感知
局部感知就是我们上面说的感受野,实际上就是卷积核和图像卷积的时候,每次卷积核所覆盖的像素只是一小部分,是局部特征,所以说是局部感知。CNN是一个从局部到整体的过程(局部到整体的实现是在全连通层),而传统的神经网络是整体的过程。具体如下图所示

2.权重共享
传统的神经网络的参数量是非常巨大的,比如1000X1000像素的图片,映射到和自己相同的大小,需要(1000X1000)的平方,也就是10的12次方,参数量太大了,而CNN除全连接层外,卷积层的参数完全取决于滤波器的设置大小,比如10x10的滤波器,这样只有100个参数,当然滤波器的个数不止一个,也就是下面要说的多卷积核。但与传统的神经网络相比,参数量小,计算量小。整个图片共享一组滤波器的参数。
3.多卷积核
一种卷积核代表的是一种特征,为获得更多不同的特征集合,卷积层会有多个卷积核,生成不同的特征,这也是为什么卷积后的图片的高,每一个图片代表不同的特征。
参考资料:https://blog.csdn.net/soulmeetliang/article/details/73188417
https://blog.csdn.net/xzy_thu/article/details/69808817
以上就是有关CNN的基础知识介绍,欢迎交流