回调函数
回调函数什么时候用?(回调函数在爬虫中最常用)造数据的非常耗时处理数据的时候不耗时你下载的地址如果完成了,就自动提醒让主进程解析谁要是好了就通知解析函数去
需要回调函数的场景:进程池中任何一个任务一旦处理完了,就立即告知主进程:我好了额,你可以处理我的结果了。主进程则调用一个函数去处理该结果,该函数即回调函数
我们可以把耗时间(阻塞)的任务放到进程池中,然后指定回调函数(主进程负责执行),这样主进程在执行回调函数时就省去了I/O的过程,直接拿到的是任务的结果。


"""回调函数(下载网页的小例子)""" from multiprocessing import Pool import requests import os import time def get_page(url): print('<%s> is getting [%s]' %(os.getpid(),url)) response = requests.get(url) #得到地址 time.sleep(2) print('<%s> is done [%s]'%(os.getpid(),url)) return {'url':url,'text':response.text} def parse_page(res): '''解析函数''' print('<%s> parse [%s]'%(os.getpid(),res['url'])) with open('db.txt','a',encoding='utf8') as f: content = res['text'] f.write(content) f.write(" "+"==============================================="+" ") parse_res = 'url:%s size:%s ' %(res['url'],len(res['text'])) f.write(parse_res) f.write(" ") if __name__ == '__main__': p = Pool(4) urls = [ 'https://www.baidu.com', 'http://www.openstack.org', 'https://www.python.org', 'https://help.github.com/', 'http://www.sina.com.cn/', 'https://www.taobao.com/', 'http://space.bilibili.com/241154045/#!/favlist?fid=87293907', ] for url in urls: obj = p.apply_async(get_page,args=(url,),callback=parse_page) p.close() p.join() print('主进程结束。。。',os.getpid()) #都不用.get()方法了
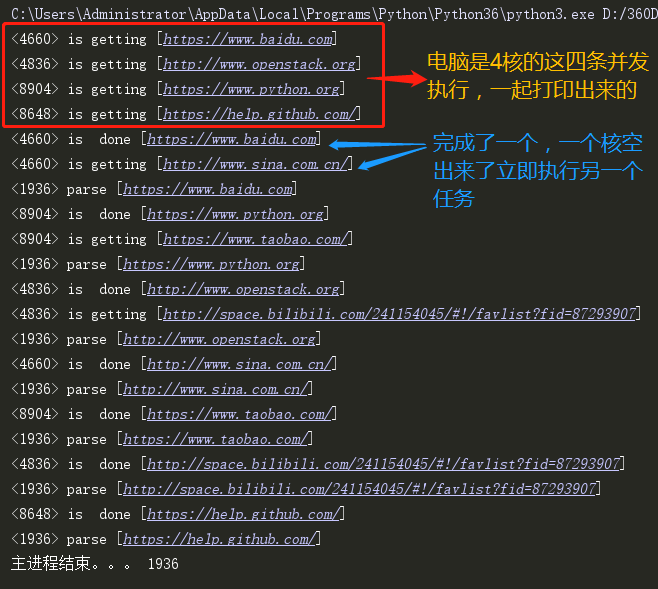
如果在主进程中等待进程池中所有任务都执行完毕后,再统一处理结果,则无需回调函数
"""下载网页小例子(无需回调函数)""" from multiprocessing import Pool import requests import os def get_page(url): print('<%os> get [%s]' %(os.getpid(),url)) response = requests.get(url) #得到地址 response响应 return {'url':url,'text':response.text} if __name__ == '__main__': p = Pool(4) urls = [ 'https://www.baidu.com', 'http://www.openstack.org', 'https://www.python.org', 'https://help.github.com/', 'http://www.sina.com.cn/' ] obj_l= [] for url in urls: obj = p.apply_async(get_page,args=(url,)) obj_l.append(obj) p.close() p.join() print([obj.get() for obj in obj_l]) #obj.get() 得到 get_pages()函数 返回值
