在平时繁忙的开发工作中,很难有时间深入了解一些Java的基础知识,而这些是我们作为程序员的一些核心竞争力。最近在做面试招聘的相关工作,因此也抽点时间来复习下一些基础知识,不论是平时开发以及用来做面试题都比较用得着,顺便打个广告,阿里国际化部门持续招人,欢迎留言联系,有意向的可以加微信详聊。
1. JNI—— Java native interface
在翻看HashMap的实现时,追代码到Object.java后,看到如下代码:
1 public native int hashCode();
好像都没什么印象了,native这个关键字是什么意思呢?原来有JNI这样一个专门的定义。凡是被关键字native修饰的方法表示,这个方法是Java原生的方法声明,其他语言类型的代码如果要能在JVM中被调用,可以用实现JNI接口的方式。多数场景下是期望使用底层C/C++ 编写的已有代码或Lib/DLL,避免重复开发,这也就是JVM跨平台、可移植特性的体现。
2. HashMap相关
HashMap是Java程序员入门必须要了解的一中数据结构,并且其设计方式在实际工作中有许多地方是可以借鉴的。首先我们可以看一下Java 8里HashMap的数据结构定义,如下代码所示,每个数据存储的单元其实是一个节点Node。这个节点包含了4个成员
- hash值:需要存放的元素的hash值,计算方法由hashCode方法定义
- 键key: 存放需要存储元素的key
- 值value:用于存储键对应的元素
- next:指向下一节点的指针
1 static class Node<K,V> implements Map.Entry<K,V> { 2 final int hash; 3 final K key; 4 V value; 5 Node<K,V> next; 6 7 Node(int hash, K key, V value, Node<K,V> next) { 8 this.hash = hash; 9 this.key = key; 10 this.value = value; 11 this.next = next; 12 } 13 14 public final K getKey() { return key; } 15 public final V getValue() { return value; } 16 public final String toString() { return key + "=" + value; } 17 18 public final int hashCode() { 19 return Objects.hashCode(key) ^ Objects.hashCode(value); 20 } 21 22 public final V setValue(V newValue) { 23 V oldValue = value; 24 value = newValue; 25 return oldValue; 26 } 27 28 public final boolean equals(Object o) { 29 if (o == this) 30 return true; 31 if (o instanceof Map.Entry) { 32 Map.Entry<?,?> e = (Map.Entry<?,?>)o; 33 if (Objects.equals(key, e.getKey()) && 34 Objects.equals(value, e.getValue())) 35 return true; 36 } 37 return false; 38 } 39 }
可以看到在hashMap设计的节点数据结构中包含了next这样一个像指针一样的成员,这个是做什么用的呢?
相信大家在学习Hash函数,HashTable的时候都有知道一个概念叫Hash Collision—— 哈希碰撞,因为容量有限的hash算法并不能保证被存储的所有数据都完全平均的分配在每个bucket种,势必会有一些元素经过的hash值散列后会指向同一个bucket,这时就需要解决哈希冲突,保证存储在同一bucket位置的元素都能被查找到,而很自然想到最简单的存储结构就是数组或者链表,为什么用链表就不用再解释了吧。
HashMap存储结构用这样一张图表示应该就比较清晰了。一个大小为16单元的HashMap,已经存放了一些元素,并且这些元素中有部分存在hash碰撞,因此在同一bucket中,采用链表方式进行存储。当需要查找的元素所在的bucket有多个元素时,遍历链表查找指定元素。
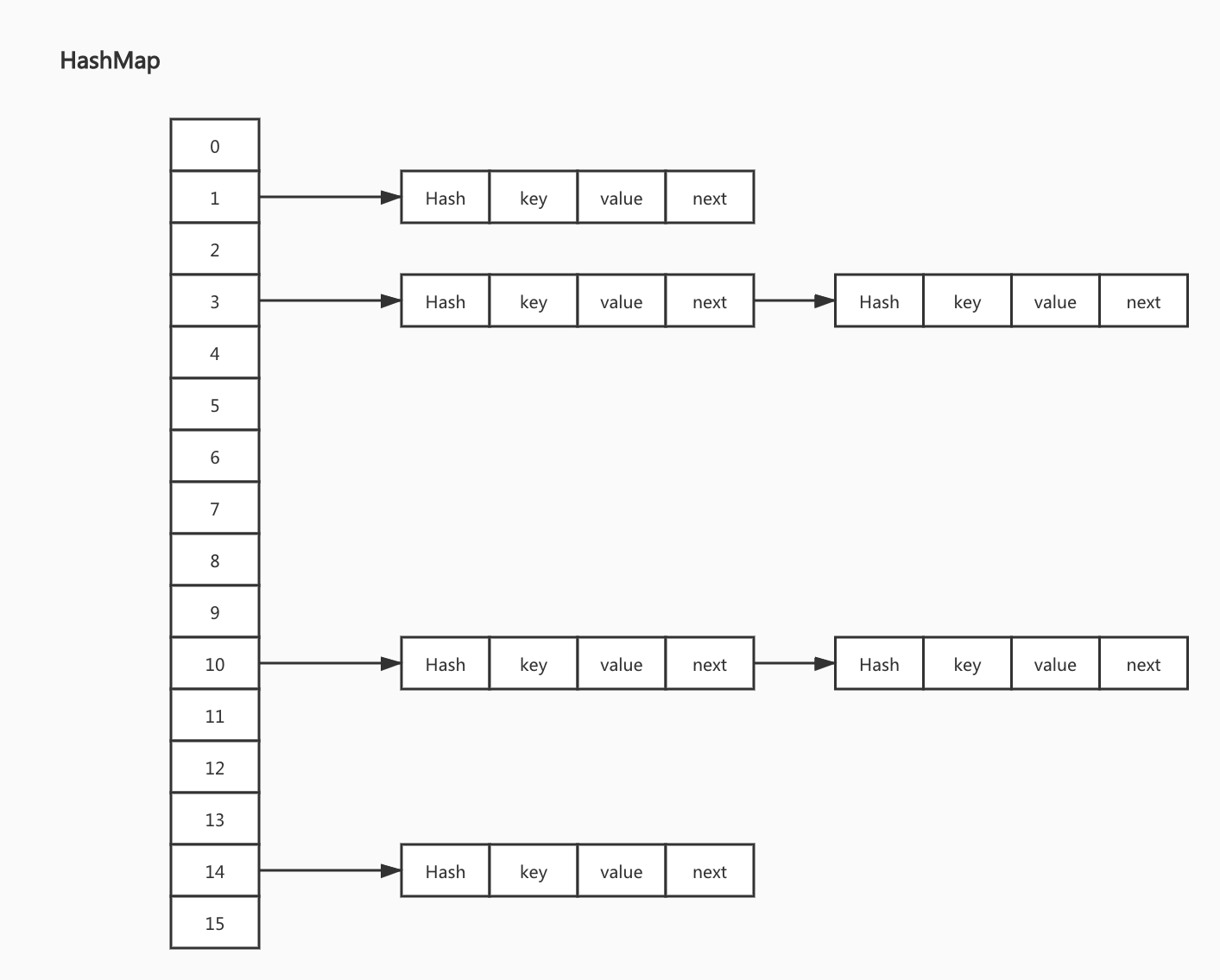
HashMap的resize()方法
当HashMap的容量不足后,JVM会重新为HashMap分配内存。如第19、20行代码所示,将之前表的大小左移一位,即容量扩大一倍,之后再进行元素的新存储,这里总结下几个关键的操作
- 容量不足时,会重新分配内存,大小为扩展为原来的2倍。
- 原先HashMap中的数据重新计算位置并存储。 当一个bucket中的元素数量超过一定限制时,链表会树化(查找效率从O(N)提高到O(logn))
1 * Initializes or doubles table size. If null, allocates in 2 * accord with initial capacity target held in field threshold. 3 * Otherwise, because we are using power-of-two expansion, the 4 * elements from each bin must either stay at same index, or move 5 * with a power of two offset in the new table. 6 * 7 * @return the table 8 */ 9 final Node<K,V>[] resize() { 10 Node<K,V>[] oldTab = table; 11 int oldCap = (oldTab == null) ? 0 : oldTab.length; 12 int oldThr = threshold; 13 int newCap, newThr = 0; 14 if (oldCap > 0) { 15 if (oldCap >= MAXIMUM_CAPACITY) { 16 threshold = Integer.MAX_VALUE; 17 return oldTab; 18 } 19 else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && 20 oldCap >= DEFAULT_INITIAL_CAPACITY) 21 newThr = oldThr << 1; // double threshold 22 } 23 else if (oldThr > 0) // initial capacity was placed in threshold 24 newCap = oldThr; 25 else { // zero initial threshold signifies using defaults 26 newCap = DEFAULT_INITIAL_CAPACITY; 27 newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); 28 } 29 if (newThr == 0) { 30 float ft = (float)newCap * loadFactor; 31 newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? 32 (int)ft : Integer.MAX_VALUE); 33 } 34 threshold = newThr; 35 @SuppressWarnings({"rawtypes","unchecked"}) 36 Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; 37 table = newTab; 38 if (oldTab != null) { 39 for (int j = 0; j < oldCap; ++j) { 40 Node<K,V> e; 41 if ((e = oldTab[j]) != null) { 42 oldTab[j] = null; 43 if (e.next == null) 44 newTab[e.hash & (newCap - 1)] = e; 45 else if (e instanceof TreeNode) 46 ((TreeNode<K,V>)e).split(this, newTab, j, oldCap); 47 else { // preserve order 48 Node<K,V> loHead = null, loTail = null; 49 Node<K,V> hiHead = null, hiTail = null; 50 Node<K,V> next; 51 do { 52 next = e.next; 53 if ((e.hash & oldCap) == 0) { 54 if (loTail == null) 55 loHead = e; 56 else 57 loTail.next = e; 58 loTail = e; 59 } 60 else { 61 if (hiTail == null) 62 hiHead = e; 63 else 64 hiTail.next = e; 65 hiTail = e; 66 } 67 } while ((e = next) != null); 68 if (loTail != null) { 69 loTail.next = null; 70 newTab[j] = loHead; 71 } 72 if (hiTail != null) { 73 hiTail.next = null; 74 newTab[j + oldCap] = hiHead; 75 } 76 } 77 } 78 } 79 } 80 return newTab; 81 }
HashMap的hash函数如下,很有意思,它不仅计算了key对象的hashCode,同时还将其右移16位后按位异或。为什么需要这样做呢?原因在于HashMap中存放元素的bucket下标的确定方式是:tab[i = (n - 1) & hash],即除留余数法。因此只要数据的hash值比较大,则往往会造成最后的下标结果大概率是相同的情况,这样哈希碰撞就比较严重,存储不均匀,因此需要使用变化比较大的部分来进行hash和bucket位置的确定,因此采用高位右移的方式来解决这一问题。
1 static final int hash(Object key) { 2 int h; 3 return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); 4 }
针对HashMap,这篇文章讲的不错:https://juejin.im/post/5d241fe6e51d4556db694a86,尤其里面还讲明了,hash算法里面为什么各种使用 & 操作的原因:因为 & 操作比其他操作快,对计算机来说移位操作比其他操作快的多,算是讲的比较透了。
3. ConcurrentHashMap
看了HashMap,再来看看ConcurrentHashMap。作为Java程序员,在求职时经常被问到的一个面试题就是ConcurrentMap和HashMap有什么区别。当然区别有很多,需要阐述的一个点就是一个是线程安全的,一个不是线程安全的,为什么ConcurrentHashMap就是线程安全的呢?又是如何实现保证线程安全的。
如下代码所示为ConcurrentHashMap中table成员变量的定义,HashMap中同样用table存储数据,不同的是ConcurrentHashMap中使用volatile关键字修饰了table变量,而HashMap中则没有。那么为什么用volatile修饰的成员在访问起来能够保证线程安全,或者说保持数据的一致性呢?
我们知道在现代计算机中数据在使用时,是会从内存读取并存放在CPU的高速缓存中以便提高访问速率,多个CPU核心可能会同时缓存同一对象的副本在自己的cache中,在并发访问的场景下,不同CPU都可能会自身缓存的副本进行读写操作,这时同一对象可能的值就会变得不一致。因此Java中引入了violation关键字来解决此类问题,被violatile修饰的变量,在编译为汇编语言后,是加上了Lock标识的指令,从而在CPU执行这条指令时,失效掉对应缓存,而从内存中重新读写。参考MESI 缓存一致性协议,具体工作原理可以参见《深入理解计算机系统》。
1 /** 2 * The array of bins. Lazily initialized upon first insertion. 3 * Size is always a power of two. Accessed directly by iterators. 4 */ 5 transient volatile Node<K,V>[] table; 6 7 /** 8 * The next table to use; non-null only while resizing. 9 */ 10 private transient volatile Node<K,V>[] nextTable;
先写这么多,最近看到一句话:软件开发是经验驱动,不是知识驱动。工作了几年现在看起来确实如此,学的好的,不如做的多想的总结的多的,共勉。