译自:https://ruslanspivak.com/lsbasi-part4/
(已获得作者授权,个别语句翻译的不到位,我会将原句跟在后边作为参考)
你是在被动地学习这些文章中的材料还是在积极地实践它?希望你一直在积极练习。
孔子曾经说过:
“闻之我也野。”

“视之我也饶。”
“行之我也明。”
在上一篇文章中,我们学习了如何解析(识别)和解释具有任意数量的加或减运算的算术表达式,例如"7 - 3 + 2 - 1",还了解了语法图以及如何用它来表示(specify)编程语言的语法。
今天,你将学习如何解析和解释具有任意数量的乘法和除法运算的算术表达式,例如"7 * 4 / 2 * 3"。本文中的除法将是整数除法,因此,如果表达式为"9 / 4",则答案将是整数:2。
今天,我还将谈论广泛用于表示某一编程语言语法的标记方法,称为上下文无关文法或BNF(简称文法)(Backus-Naur形式)。在本文中,我将不使用纯BNF表示法,而使用修改后的EBNF表示法。
我们为什么要使用文法,这是几个原因:
1、文法以简洁的方式指定编程语言的语法,与语法图不同,文法非常紧凑,在以后的文章中会越来越多地使用文法。
2、文法可以作为出色的文档。
3、即使你是从头开始手动编写解析器,文法也是一个不错的起点。通常,你可以按照一组简单的规则将文法转换为代码。
4、有一套称为解析器生成器的工具,可以接受文法作为输入,并根据该文法自动生成解析器,我将在本系列的后面部分讨论这些工具。
这是一个描述算术表达式的文法,例如"7 * 4 / 2 * 3"(这只是该文法可以生成的众多表达式之一):

文法由一系列规则(rules)组成,也称为productions,我们的文法有两个规则:
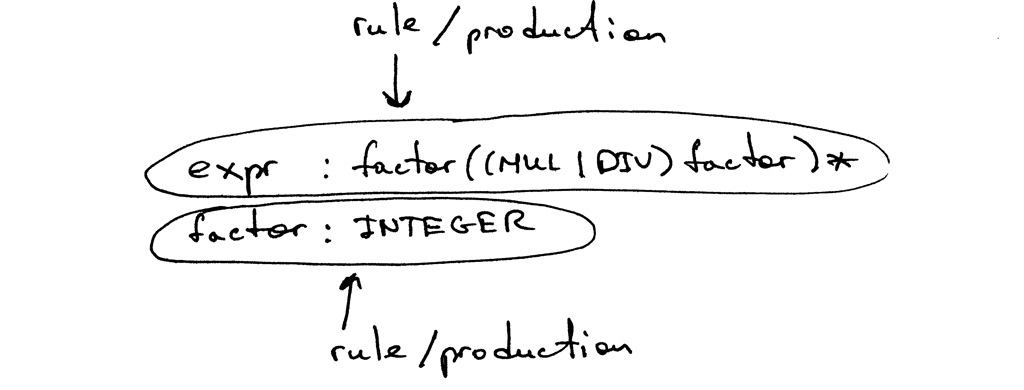
一个规则由称为head或left-hand side的非终结符(non-terminal)开始,然后跟上一个冒号(colon),最后由称为body或right-hand side的终结符(terminal)和/或非终结符(non-terminal)组成:(A rule consists of a non-terminal, called the head or left-hand side of the production, a colon, and a sequence of terminals and/or non-terminals, called the body or right-hand side of the production)
(这里我翻译的很绕,直接看图会更清楚一点)
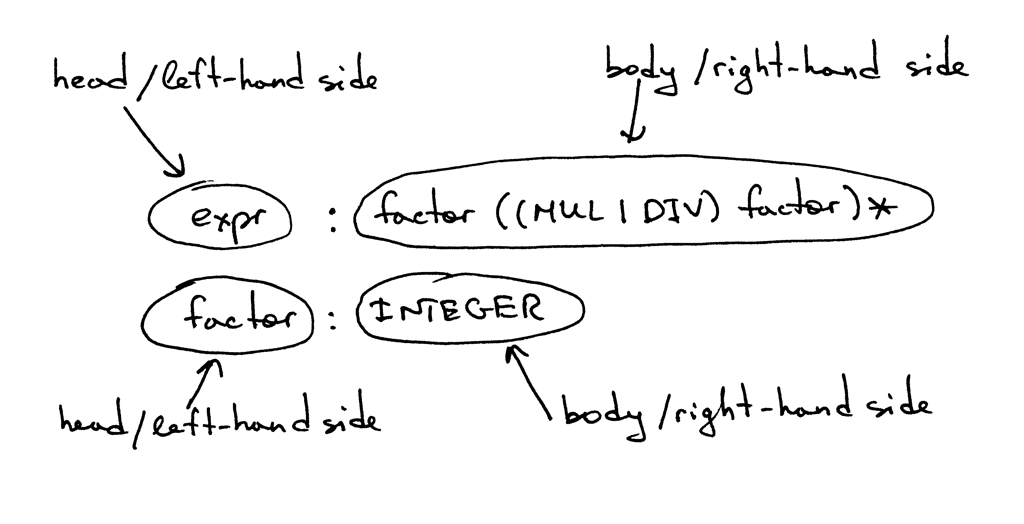
在上面显示的文法中,诸如MUL,DIV和INTEGER之类的标记称为终结符(terminals),而诸如expr和factor之类的变量称为非终结符(non-terminals),非终结符通常由一系列终结符和/或非终结符组成:(In the grammar I showed above, tokens like MUL, DIV, and INTEGER are called terminals and variables like expr and factor are called non-terminals. Non-terminals usually consist of a sequence of terminals and/or non-terminals)
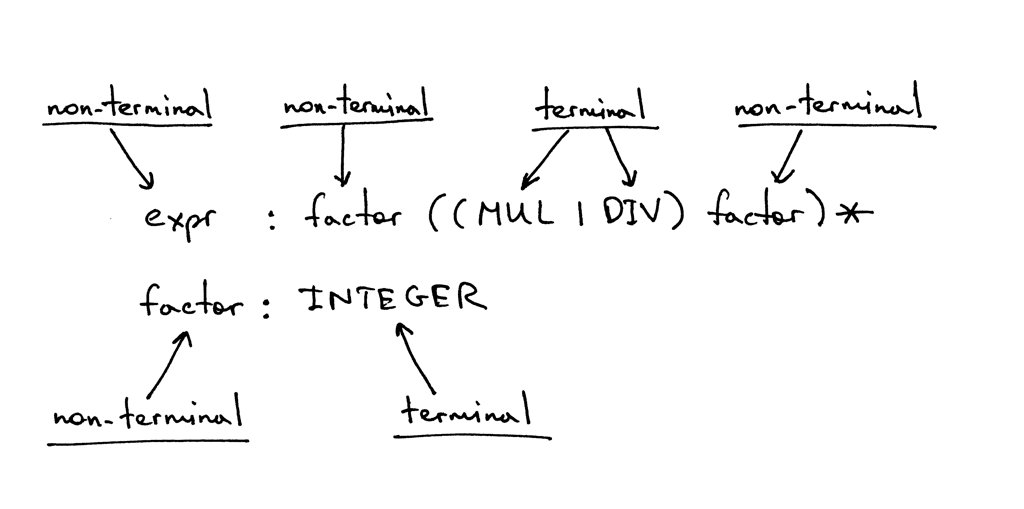
第一条规则左侧的非终结符称为开始符(start symbol),在我们的文法中,开始符是expr:

你可以将规则expr解释为: “expr可以只是一个因数(factor),也可以可选地跟上乘法或除法运算符,然后再乘以另一个因数,之后又可选地跟上乘法或除法运算符,然后再乘以另一个因数,当然之后也可以继续循环下去”(An expr can be a factor optionally followed by a multiplication or division operator followed by another factor, which in turn is optionally followed by a multiplication or division operator followed by another factor and so on and so forth)
是什么因数(factor)?在本文中,它只是一个整数。
让我们快速浏览一下文法中使用的符号及其含义:
1、"|",表示或者,因此(MUL | DIV)表示MUL或DIV。
2、"(…)",表示(MUL | DIV)中的终结符和/或非终结符的一个组(grouping)。
3、"(…)*",表示该组可以出现零次或多次。
如果你过去使用过正则表达式,那么这些符号你应该非常熟悉。
文法通过解释如何形成句子来定义语言(A grammar defines a language by explaining what sentences it can form),那么我们如何使用文法来推导出算术表达式呢?有这几个步骤:首先从起始符expr开始,然后用该非终止符的规则主体重复替换非终止符,直到生成仅包含终止符的句子为止,这样我们就通过文法来形成了语言。(first you begin with the start symbol expr and then repeatedly replace a non-terminal by the body of a rule for that non-terminal until you have generated a sentence consisting solely of terminals. Those sentences form a language defined by the grammar)
如果文法不能导出某个算术表达式,则表示它不支持该表达式,那么解析器在尝试识别该表达式时将生成错误。
这里有几个例子,你可以看看来加深理解:
1、这是推导一个整数"3"的步骤:

2、这是推导"3 * 7"的步骤:

3、这是推导"3 * 7 / 2"的步骤:

确实这部分包含很多理论!
当我第一次阅读文法和相关术语时会感觉像这样:

我可以向你保证,我绝对不是这样的:

我花了一些时间来熟悉符号(notation),理解它如何工作方式以及它与解析器和词法分析器之间的关系,我必须告诉你,由于它在编译器相关文章中得到了广泛的使用,从长远来看,你一定会碰到它,所以我推荐你早点认识它:)
现在,让我们将该文法映射到代码。
这是我们将文法转换为源代码的一些指导方法(guideline),遵循它们可以将文法从字面上转换为有效的解析器:
1、语法中定义的每个规则R可以成为具有相同名称的函数(method),并且对该规则的引用将成为方法调用:R(),函数的主体中的语句流也依照与同样的指导方法。(Each rule, R, defined in the grammar, becomes a method with the same name, and references to that rule become a method call: R(). The body of the method follows the flow of the body of the rule using the very same guidelines.)
2、(a1 | a2 | aN)转换为if-elif-else语句。(Alternatives (a1 | a2 | aN) become an if-elif-else statement.)
3、(…)转换while语句,可以循环零次或多次。(An optional grouping (…) becomes a while statement that can loop over zero or more times.)
4、对Token的引用T转换为对eat函数的调用:eat(T),也就是如果T的类型与当前的Token类型一致的话,eat函数将消耗掉T,然后从词法分析器获取一个新的Token并将其赋值给current_token这个变量。(Each token reference T becomes a call to the method eat: eat(T). The way the eat method works is that it consumes the token T if it matches the current lookahead token, then it gets a new token from the lexer and assigns that token to the current_token internal variable.)
准则总结如下所示:
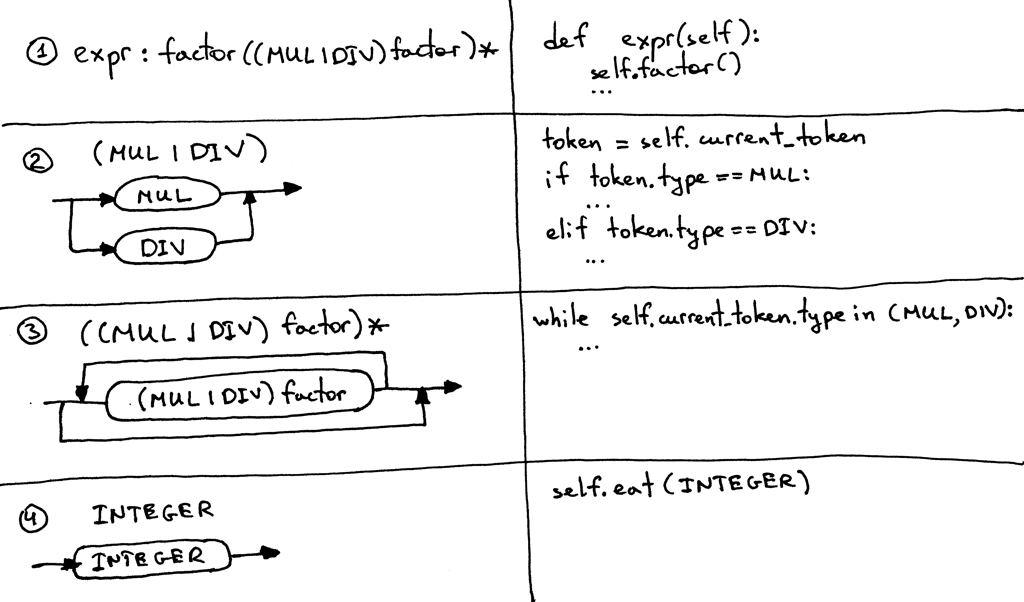
让我们按照上述指导方法将文法转换为代码。
我们的语法有两个规则:一个expr规则和一个因数规则。让我们从因数规则(生产)开始。根据准则,需要创建一个称为factor的函数(准则1),该函数需调用一次eat函数来消耗类型为INTEGER的Token(准则4):
def factor(self):
self.eat(INTEGER)
很容易就可以写出来。
继续!
规则expr转换为expr函数(准则1),规则的主体从对factor的引用开始,我们转换为factor()函数调用,可选的组(…)*转换为while循环,而(MUL | DIV)转换为if-elif-else语句,将这些组合在一起,我们得到以下expr函数:
def expr(self):
self.factor()
while self.current_token.type in (MUL, DIV):
token = self.current_token
if token.type == MUL:
self.eat(MUL)
self.factor()
elif token.type == DIV:
self.eat(DIV)
self.factor()
花一些时间看看我如何将语法映射到源代码,确保你了解。
为了方便起见,我将上面的代码放入了parser.py文件中,该文件包含一个词法分析器和一个不带解释器的分析器,你可以直接从GitHub下载文件并使用,它是交互式的,你可以在其中输入表达式并查看根据文法构建的解析器是否可以识别表达式。
这是我在计算机上的运行效果:
$ python parser.py
calc> 3
calc> 3 * 7
calc> 3 * 7 / 2
calc> 3 *
Traceback (most recent call last):
File "parser.py", line 155, in <module>
main()
File "parser.py", line 151, in main
parser.parse()
File "parser.py", line 136, in parse
self.expr()
File "parser.py", line 130, in expr
self.factor()
File "parser.py", line 114, in factor
self.eat(INTEGER)
File "parser.py", line 107, in eat
self.error()
File "parser.py", line 97, in error
raise Exception('Invalid syntax')
Exception: Invalid syntax
试试看!
我们再来看看相同expr规则的语法图:

是时候开始编写新的算术表达式解释器的源代码了,以下是一个计算器的代码,该计算器可以处理包含任意数量整数乘法和除法运算的算术表达式,还可以看到我们将词法分析器重构为一个单独的Lexer类,并更新了Interpreter类以将Lexer实例作为参数:
# Token types
#
# EOF (end-of-file) token is used to indicate that
# there is no more input left for lexical analysis
INTEGER, MUL, DIV, EOF = 'INTEGER', 'MUL', 'DIV', 'EOF'
class Token(object):
def __init__(self, type, value):
# token type: INTEGER, MUL, DIV, or EOF
self.type = type
# token value: non-negative integer value, '*', '/', or None
self.value = value
def __str__(self):
"""String representation of the class instance.
Examples:
Token(INTEGER, 3)
Token(MUL, '*')
"""
return 'Token({type}, {value})'.format(
type=self.type,
value=repr(self.value)
)
def __repr__(self):
return self.__str__()
class Lexer(object):
def __init__(self, text):
# client string input, e.g. "3 * 5", "12 / 3 * 4", etc
self.text = text
# self.pos is an index into self.text
self.pos = 0
self.current_char = self.text[self.pos]
def error(self):
raise Exception('Invalid character')
def advance(self):
"""Advance the `pos` pointer and set the `current_char` variable."""
self.pos += 1
if self.pos > len(self.text) - 1:
self.current_char = None # Indicates end of input
else:
self.current_char = self.text[self.pos]
def skip_whitespace(self):
while self.current_char is not None and self.current_char.isspace():
self.advance()
def integer(self):
"""Return a (multidigit) integer consumed from the input."""
result = ''
while self.current_char is not None and self.current_char.isdigit():
result += self.current_char
self.advance()
return int(result)
def get_next_token(self):
"""Lexical analyzer (also known as scanner or tokenizer)
This method is responsible for breaking a sentence
apart into tokens. One token at a time.
"""
while self.current_char is not None:
if self.current_char.isspace():
self.skip_whitespace()
continue
if self.current_char.isdigit():
return Token(INTEGER, self.integer())
if self.current_char == '*':
self.advance()
return Token(MUL, '*')
if self.current_char == '/':
self.advance()
return Token(DIV, '/')
self.error()
return Token(EOF, None)
class Interpreter(object):
def __init__(self, lexer):
self.lexer = lexer
# set current token to the first token taken from the input
self.current_token = self.lexer.get_next_token()
def error(self):
raise Exception('Invalid syntax')
def eat(self, token_type):
# compare the current token type with the passed token
# type and if they match then "eat" the current token
# and assign the next token to the self.current_token,
# otherwise raise an exception.
if self.current_token.type == token_type:
self.current_token = self.lexer.get_next_token()
else:
self.error()
def factor(self):
"""Return an INTEGER token value.
factor : INTEGER
"""
token = self.current_token
self.eat(INTEGER)
return token.value
def expr(self):
"""Arithmetic expression parser / interpreter.
expr : factor ((MUL | DIV) factor)*
factor : INTEGER
"""
result = self.factor()
while self.current_token.type in (MUL, DIV):
token = self.current_token
if token.type == MUL:
self.eat(MUL)
result = result * self.factor()
elif token.type == DIV:
self.eat(DIV)
result = result / self.factor()
return result
def main():
while True:
try:
# To run under Python3 replace 'raw_input' call
# with 'input'
text = raw_input('calc> ')
except EOFError:
break
if not text:
continue
lexer = Lexer(text)
interpreter = Interpreter(lexer)
result = interpreter.expr()
print(result)
if __name__ == '__main__':
main()
将以上代码保存到calc4.py文件中,或直接从GitHub下载,尝试一下,看看它是否正确。
这是我在笔记本电脑上运行效果:
$ python calc4.py
calc> 7 * 4 / 2
14
calc> 7 * 4 / 2 * 3
42
calc> 10 * 4 * 2 * 3 / 8
30
这是今天的练习:

1、编写描述包含任意数量的+,-,* 或/运算符的算术表达式的文法。使用此文法,应该能够推导出诸如"2 + 7 * 4","7 - 8 / 4","14 + 2 * 3 - 6 / 2"之类的表达式,依此类推。
2、使用上一问编写的文法,实现一个解释器,该解释器可以计算包含任意数量的+,-,* 或/运算符的算术表达式。 解释器应该能够处理"2 + 7 * 4","7 - 8 / 4","14 + 2 * 3 - 6 / 2"等表达式。
最后再来复习回忆一下,记住今天文章的文法,回答以下问题,并根据需要参考以下图片:
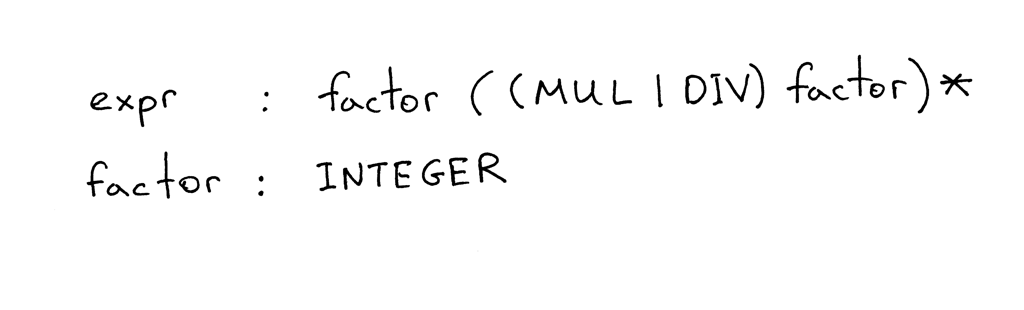
1、什么是无上下文文法?
2、本文中文法有多少条规则(rule)/产生式(production)?
3、什么是终结符(terminal)? (识别图中的所有终结符)
4、什么是非终结符? (标识图片中的所有非终结符)
5、什么是规则的头部(head)? (识别图片中的所有头部/左侧(left-hand sides))
6、什么是规则的主体(body)? (标识图中的所有主体/右侧(right-hand sides))
7、什么是文法的开始符(start symbol)?
嘿,你一直阅读到最后! 这篇文章包含了相当多的理论知识,所以我为你的完成感到自豪。
下次我会再写一篇新文章,敬请期待,不要忘记练习,它们对你有好处。