概念
分布式同步服务中间件:使用分布式一致性协议,提供分布式环境下的同步服务。内部有多个节点,如果其中一个节点崩溃了,其他节点就自动接管其功能,继续对外提供服务,好像什么都没有发生过一样。
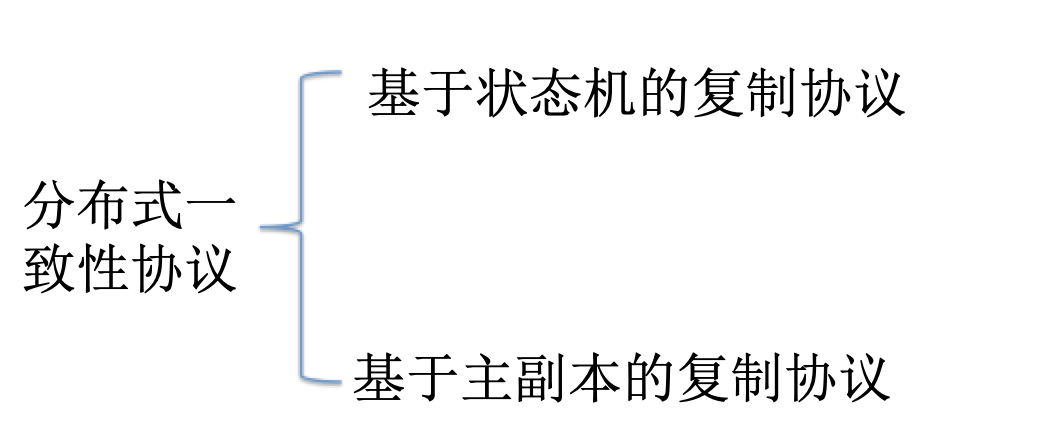
基于状态机的复制协议(Paxos、Raft):
集群中的每个节点都可以响应客户的请求,如果某个节点A响应了客户的请求,就由A将该请求发送给集群中的每个节点;集群中的每个节点都维护一个状态机,为了保证数据的一致性,每个节点都按照同样的顺序执行一系列的用户请求。
基于主副本的复制协议(ZAB,Zookeeper Atomic Broadcast):
只有主副本处理客户需求;每隔一段时间,主副本就给其他节点发送一个变化更新。
分布式同步服务举例
Chubby是谷歌公司实现的以Paxos协议为基础的分布式同步服务。
Zookeeper是谷歌Chubby的开源实现,是基于ZAB协议的。
以下的原理介绍,都会通过这2者来进行说明。
同步服务的实现原理
如何消除单点故障
Chubby和ZooKeeper通过Master选举来帮助分布式系统解决单点故障, 保证该系统中每时每刻只有一个Master为分布式系统提供服务。只是Paxos协议本身具有领导选举协议,ZAB协议中不包括领导选举过程,需要一个额外的领导选举协议。
如何实现高可用
ZooKeeper通过复制来实现高可用性,只要集合体中半数以上的机器处于可用状态,它就能够提供服务。从概念上来说,ZooKeeper它所做的就是确保对Znode树的每一个修改都会被复制到集合体中超过半数的 机器上。
如何保证一致性
ZK集群中每个Server,都保存一份数据副本。Zookeeper使用简单的同步策略,给客户端提供以下两条基本保证来实现数据的一致性:
(1)线性化的写支持,即所有的更新操作以某种次序顺序执行。
(2)先进先出的客户端顺序,即一个客户端发起的所有操作,按照其发起顺序执行。
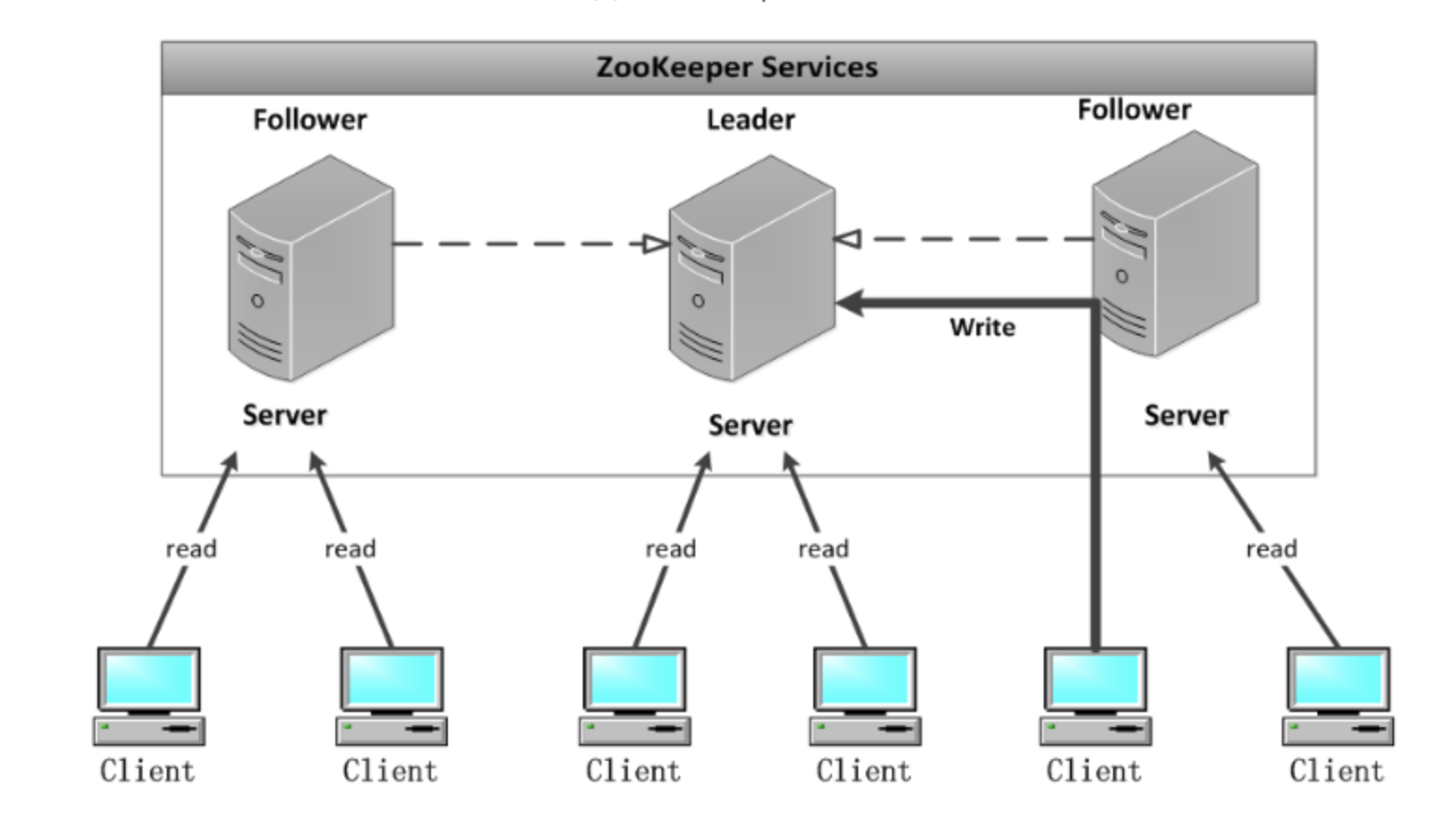
所有的读请求由Zk Server 本地响应,所有的更新请求将转发给Leader,由Leader实施。读请求,由每台Server数据库的本地副本来进行服务。改变服务器的状态的写请求,需要通过一致性协议来处理。
Zookeeper的核心是原子广播机制,这个机制保证了各个server之间的同步。在广播模式ZooKeeper Server会接受Client请求,所有的写请求都被转发给领导者,再由领导者将更新广播给跟随者。当半数以上的跟随者已经将修改持久化之后,领导者才会提交这个更新,然后客户端才会收到一个更新成功的响应。这个用来达成共识的协议被设计成具有原子性,因此每个修改要么成功要么失败。
具体来说,Zookeeper从以下几点保证数据的一致性:
① 顺序一致性
来自任意特定客户端的更新都会按其发送顺序被提交。也就是说,如果一个客户端将Znode z的值更新为a,在之后的操作中,它又将z的值更新为b,则没有客户端能够在看到z的值是b之后再看到值a。
② 原子性
每个更新要么成功,要么失败。这意味着如果一个更新失败,则不会有客户端会看到这个更新的结果。
③ 单一系统映像
一个客户端无论连接到哪一台服务器,它看到的都是同样的系统视图。这意味着,如果一个客户端在同一个会话中连接到一台新的服务器,它所看到的系统状态不会比在之前服务器上所看到的更老。当一台服务器出现故障,导致它的一个客户端需要尝试连接集合体中其他的服务器时,所有滞后于故障服务器的服务器都不会接受该 连接请求,除非这些服务器赶上故障服务器。同样的,Zab要保证同一个leader的发起的事务要按顺序被apply,同时还要保证只有先前的leader的所有事务都被apply之后,新选的leader才能在发起事务。(为了保证每 个Server的数据视图的一致性)
④ 持久性
一个更新一旦成功,其结果就会持久存在并且不会被撤销。这表明更新不会受到服务器故障的影响。
Zookeeper实践
ZooKeeper是一种为分布式应用所设计的高可用、高性能且一致的开源协调服务,它提供了一项基本服务:分布式锁服务。后来,开发者在分布式锁的基础上,摸索了出了其他的使用方法:配置维护、组服务、分布式消息队列、分布式通知/协调等。
ZooKeeper所提供的服务主要是通过:数据结构+原语+watcher机制,三个部分来实现的:
- 数据结构——Znode, 在结构上和标准文件系统的非常相似,都是采用这种树形层次结构,ZooKeeper树中的每个节点被称为—Znode。
- 原语——关于Znode的一些操作;
- 通知机制——Watcher机制,服务通过消息以网络的形式发送给分布式应用程序。
安装、配置、启动
下载:3.14版本,不要下载最新版
配置:cp conf/zoo_sample.cfg conf/zoo.cfg
启动zookeeper:bin/zkServer.sh start
停止zookeeper:bin/zkServer.sh stop
用zookeeper客户端连接下服务端:bin/zkCli.sh
退出客户端连接:quit
客户端命令操作zookeeper
查看当前zookeeper所包含的内容: ls /
创建新的znode: create /username lxy
获取znode下的字符串:get /username
修改znode的字符串:set /username sheron
删除znode:delete /username
基于Zookeeper实现配置管理
假设我们的程序是分布式部署在多台机器上,如果我们要改变程序的配置文件,需要逐台机器去修改,非常麻烦,现在把这些配置全部放到zookeeper上去,保存在 zookeeper 的某个目录节点中,然后所有相关应用程序对这个目录节点进行监听,一旦配置信息发生变化,每个应用程序就会收到 zookeeper 的通知,然后从 zookeeper 获取新的配置信息应用到系统中。
- 启动3个zookeeper实例子
./bin/zkServer.sh start conf/zoo-1.cfg
./bin/zkServer.sh start conf/zoo-2.cfg
./bin/zkServer.sh start conf/zoo-3.cfg
其中,3台服务器的配置分别如下:
三台服务器的ip:127.0.0.1
clientPort:2184、2182、2183
服务器与集群中的 Leader 服务器交换信息的端口:2888、2889、2890
执行选举时服务器相互通信的端口:3888、3889、3890
- 查看3台服务器的角色
./bin/zkServer.sh status conf/zoo-1.cfg
./bin/zkServer.sh status conf/zoo-2.cfg
./bin/zkServer.sh status conf/zoo-3.cfg
可以看到1个leader、2个follower。
- 连接其中一台服务器的客户端,修改配置,看看其他服务器的表现
连接3号服务器:./bin/zkCli.sh -server 127.0.0.1:2183
修改配置:set /username daniu
quit
连接1号服务器:./bin/zkCli.sh -server 127.0.0.1:2184
查看配置:get /username
- 在sofa4程序中监听配置
public class ZooKeeperProSync implements Watcher {
private static CountDownLatch connectedSemaphore = new CountDownLatch(1);
private static ZooKeeper zk = null;
private static Stat stat = new Stat();
public static void main(String[] args) throws Exception {
//zookeeper配置数据存放路径
String path = "/username";
//连接zookeeper并且注册一个默认的监听器
zk = new ZooKeeper("127.0.0.1:2182", 5000, //
new ZooKeeperProSync());
//等待zk连接成功的通知
connectedSemaphore.await();
//获取path目录节点的配置数据,并注册默认的监听器
System.out.println(new String(zk.getData(path, true, stat)));
Thread.sleep(Integer.MAX_VALUE);
}
public void process(WatchedEvent event) {
if (KeeperState.SyncConnected == event.getState()) { //zk连接成功通知事件
if (EventType.None == event.getType() && null == event.getPath()) {
connectedSemaphore.countDown();
} else if (event.getType() == EventType.NodeDataChanged) { //zk目录节点数据变化通知事件
try {
System.out.println("配置已修改,新值为:" + new String(zk.getData(event.getPath(), true, stat)));
} catch (Exception e) {
}
}
}
}
}
上面代码中,我们监听的是第2台服务器,我们去修改3台机器中的任意一台机器的配置,看看是否能监听到:
set /username xiaoniu
set /username sheron
看到控制台打印:
配置已修改,新值为:xiaoniu
配置已修改,新值为:sheron
成功。
基于Zookeeper实现分布式锁
分布式锁主要用于在分布式环境中保护共享资源实现互斥访问,以达到保证数据的一致性。
- 获取分布式锁思路
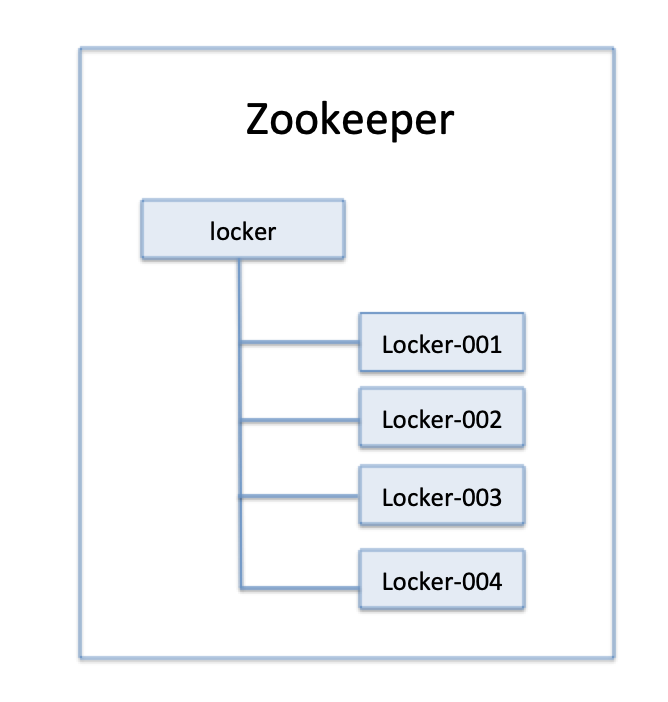
图1 节点存储结构
在获取分布式锁的时候在locker节点下创建临时顺序节点,释放锁的时候删除该临时节点。客户端调用createNode方法在locker下创建临时顺序节点,然后调用getChildren(“locker”)来获取locker下面的所有子节点,注意此时不用设置任何Watcher。客户端获取到所有的子节点path之后,如果发现自己在之前创建的子节点序号最小,那么就认为该客户端获取到了锁。如果发现自己创建的节点并非locker所有子节点中最小的,说明自己还没有获取到锁,此时客户端需要找到比自己小的那个节点,然后对其调用exist()方法,同时对其注册事件监听器。之后,让这个被关注的节点删除,则客户端的Watcher会收到相应通知,此时再次判断自己创建的节点是否是locker子节点中序号最小的,如果是则获取到了锁,如果不是则重复以上步骤继续获取到比自己小的一个节点并注册监听。当前这个过程中还需要许多的逻辑判断。
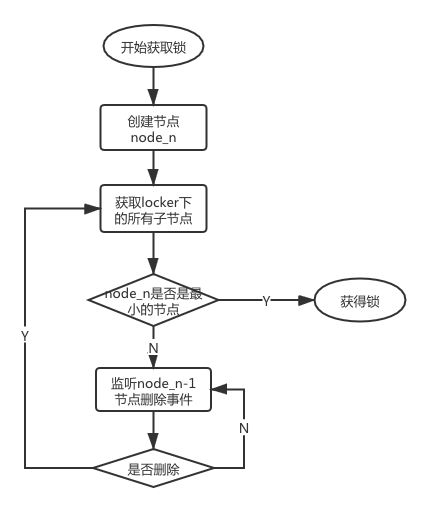
- 实现方法
(1)DistributedLock
锁接口,包括“获取锁”、“释放锁”。
(2)BaseDistributedLock
主要用于与Zookeeper交互,包含“尝试获取锁”、“释放锁”的方法。
(3)SimpleDistributedLockMutex
互斥锁类,实现以上定义的锁接口,同时继承基类BaseDistributedLock。
获取分布式锁的重点逻辑在于BaseDistributedLock,实现了基于Zookeeper实现分布式锁的细节。
- 验证
public class LockTest {
public static void main(String[] args) throws Exception {
ZkClient zkClient1 = new ZkClient(
"127.0.0.1:2182",
2000000
);
String basePath = "/locker";
SimpleDistributedLockMutex locker1 = new SimpleDistributedLockMutex(zkClient1, basePath);
// locker 1 尝试获取锁
locker1.acquire(-1, null);
// 在其他线程 locker 2 尝试获取锁
LockTest test = new LockTest();
MyThread myThread = test.new MyThread();
myThread.start();
// locker 1 等待3秒 释放锁
Thread.currentThread().sleep(3000);
locker1.release();
}
class MyThread extends Thread {
@Override
public void run() {
ZkClient zkClient2 = new ZkClient(
"127.0.0.1:2183",
2000000
);
String basePath = "/locker";
SimpleDistributedLockMutex locker2 = new SimpleDistributedLockMutex(zkClient2, basePath);
try {
//在另一个线程里 locker 2 尝试获取锁
locker2.acquire(-1, null);
} catch (Exception e) {
}
}
}
}
结果:
Sheron观测--- /locker/lock-0000000057: 创建了节点
Sheron观测--- /locker/lock-0000000057: 获取了锁
Sheron观测--- /locker/lock-0000000058: 创建了节点
Sheron观测--- /locker/lock-0000000058: 没有获取锁, 等待 /locker/lock-0000000057释放锁
Sheron观测--- /locker/lock-0000000057: 释放了锁
Sheron观测--- /locker/lock-0000000057: 被观测到释放了锁
Sheron观测--- /locker/lock-0000000058: 获取了锁
分析:57号节点是/locker下的第一个节点,所以它可以直接获取锁,58号节点创建后,要等待57号节点释放锁,当过了3秒钟,57号节点释放掉了锁,这时候58号节点获取到了锁。