我们在浏览百度贴吧时,会看到许多“神图”,我们想要保存,这个时候我们就会下载到本地,当我们学习了爬虫之后,就没有必要一个一个下载了,可以使用爬虫自动下载全部图片。
下面随便指定一个贴吧页:http://tieba.baidu.com/p/3242594565,爬取页面上的图片。首先对这个帖子进行观察,我们会发现这个帖子有许多页,所以就可以使用pn=%d的方法来爬取后面页数的帖子,然后想到爬取图片需要机芯进行命名,并把它们保存在本地
查看一下要爬取的网址信息:http://tieba.baidu.com/p/3242594565
看下界面,发现有14页
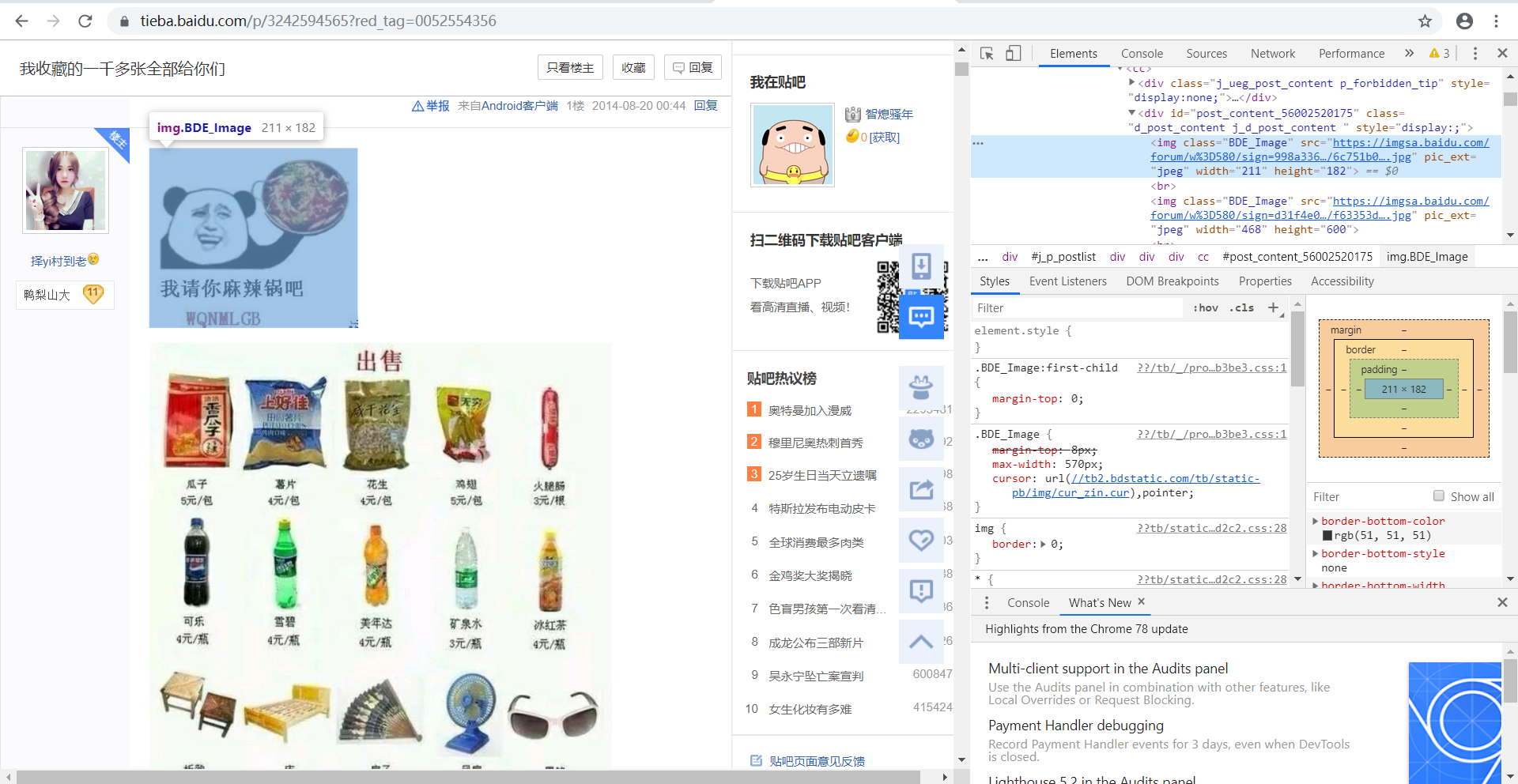
然后找到要爬取的图片,查看图片的地址信息。
这里可以看到图片地址为:https://imgsa.baidu.com/forum/w%3D580/sign=998a3367c98065387beaa41ba7dca115/6c751b0fd9f9d72a6ac0a634d72a2834349bbb28.jpg
可以使用正则表达式进行爬取 ,可以使用https://imgsa.*?.jpg的格式。
然后就是编写代码进行爬取了,这里的思路是:
先获得网页的代码,然后通过网页代码获取图片,再将图片命名保存就可以了。
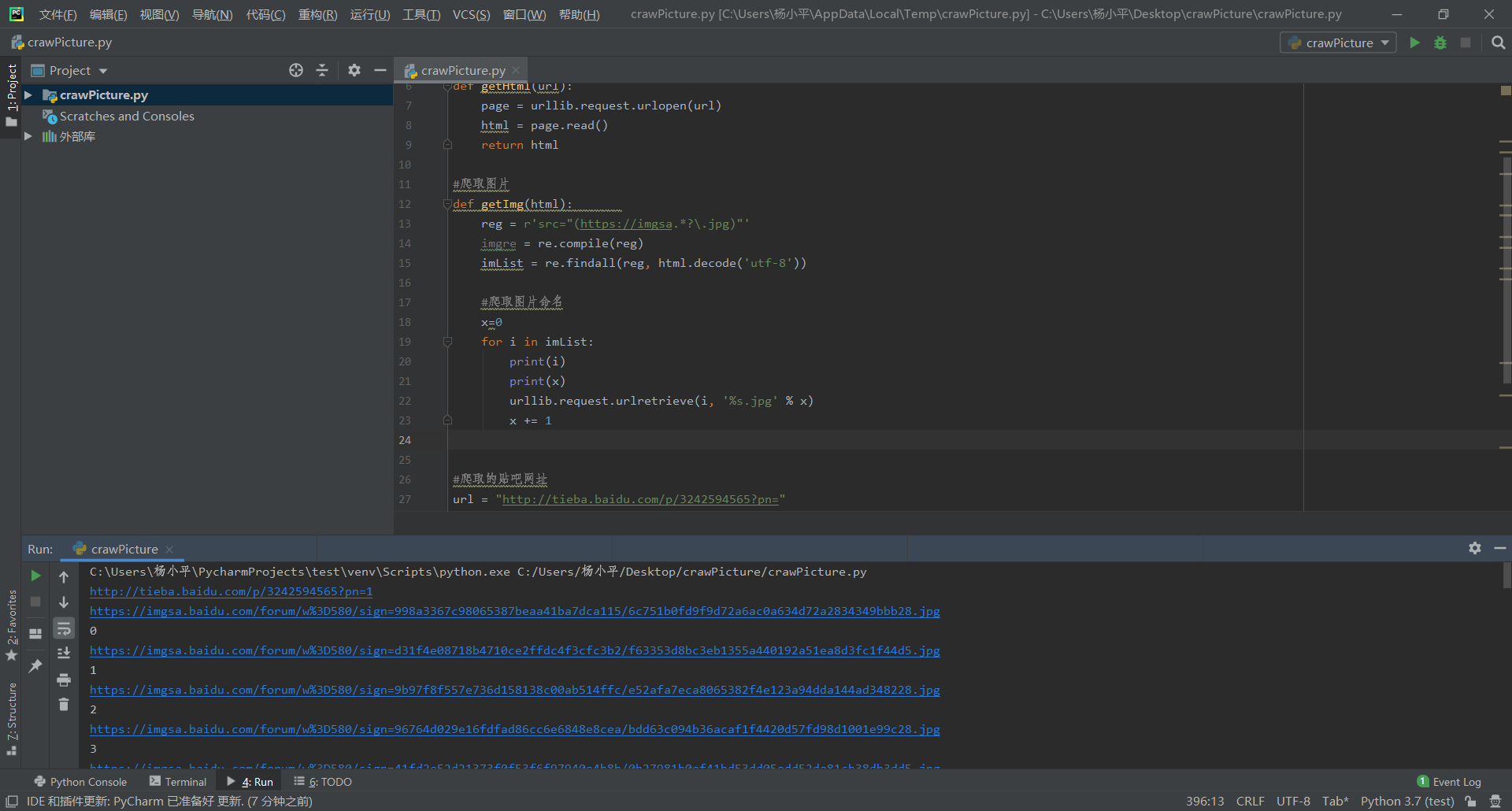
代码如下:
import re import urllib.request #获取网址信息 def getHtml(url): page = urllib.request.urlopen(url) html = page.read() return html #爬取图片 def getImg(html): reg = r'src="(https://imgsa.*?.jpg)"' imgre = re.compile(reg) imList = re.findall(reg, html.decode('utf-8')) #爬取图片命名 x=0 for i in imList: print(i) print(x) urllib.request.urlretrieve(i, '%s.jpg' % x) x += 1 #爬取的贴吧网址 url = "http://tieba.baidu.com/p/3242594565?pn=" #由于贴吧有14页,爬取的图片较多,这里先爬取一个网址的图片,图片保存在当前文件夹里 for k in range(1, 2): ul = url+str(k) print(ul) html = getHtml(ul) getImg(html)
在Pycharm上运行代码:
查看文件夹,发现新增了下载的图片,并且都已经命名:
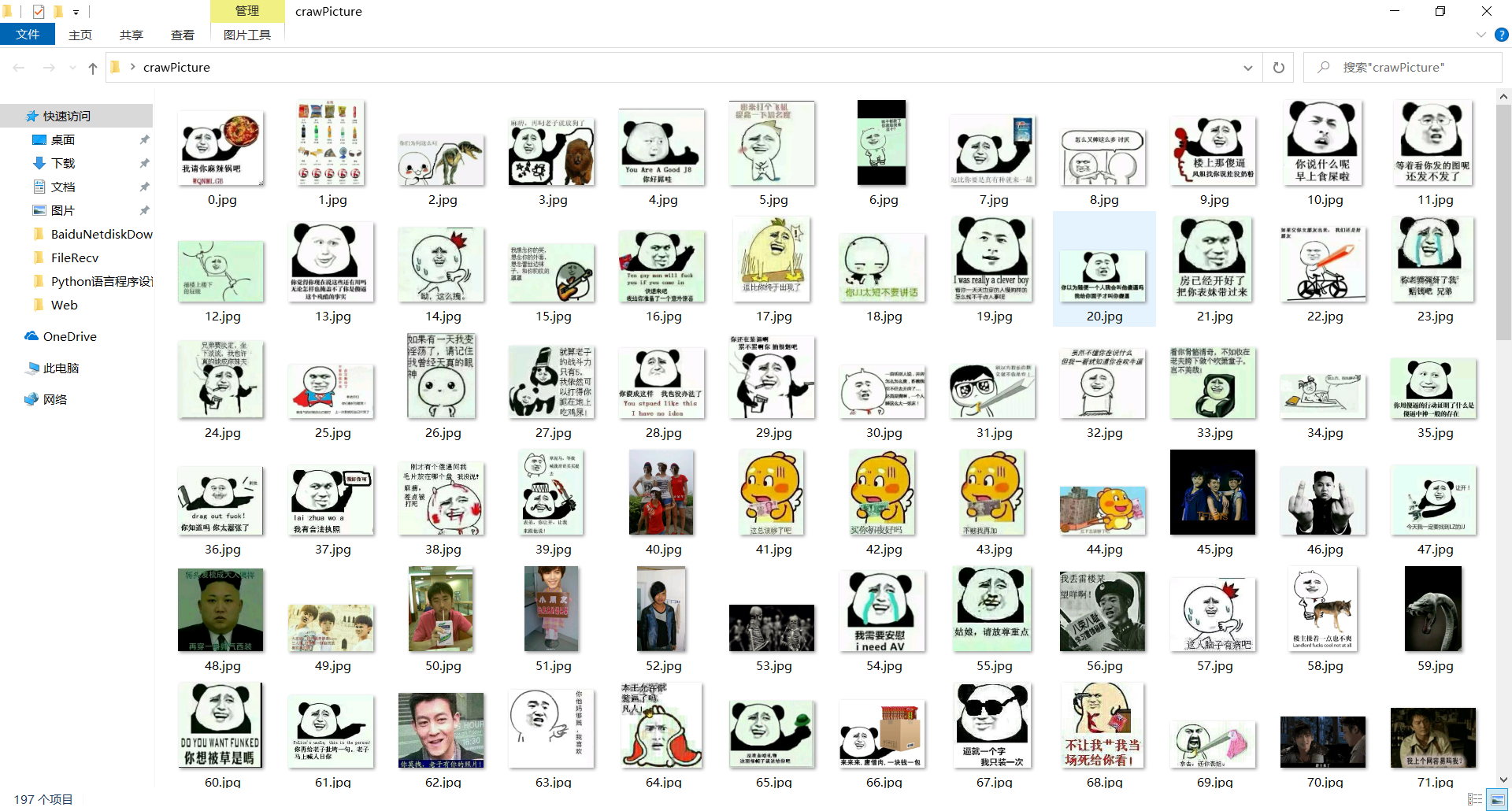
这样就成功爬取了贴吧上的图片。