最开始只是想让页面能够映射出我的字典值,然而却发现了更大的问题。
假如你自己做一个 demo ,需要前台页面映射出字典数据你会怎么做呢?大致的思路应该是有的,准备字典,准备数据,然后将两部分进行映射。
在做的过程中,我也在思考,该如何保存字典数据呢?有一种比较简单的方法,这种方法也很是巧妙,使用一个工具类,使用枚举法来保存字典值。在该类中还可以加载配置文件。
import java.io.IOException;
import java.util.Properties;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class Keys {
private final static Logger logger = LoggerFactory.getLogger(BaseDictUtil.class);
public static String project_name;
// 加载配置文件
static {
logger.info("======= Start load Properties =====");
Properties webapp_prop = new Properties();
try {
webapp_prop.load(BaseDictUtil.class.getResource("/webapp.properties").openStream());
project_name = webapp_prop.getProperty("webapp_project_name");
logger.info("======= End load Properties =====");
} catch (IOException e) {
logger.error(e.getMessage(), e);
}
}
// 配置性别字典
public enum Gender {
Gender_1("男生", 1), Gender_2("女生", 2);
public static String getName(int index) {
for (Gender c : Gender.values()) {
if (c.getIndex() == index) {
return c.name;
}
}
return null;
}
private Gender(String name, int index) {
this.name = name;
this.index = index;
}
private String name;
private int index;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getIndex() {
return index;
}
public void setIndex(int index) {
this.index = index;
}
}
}
上面这种方式,在字典很少的情况下,用起来方便快捷,但是有个问题很明显,若是需要新添加一个字典还要改动代码,很是麻烦。
下面看一下另外一种方式,也是用的比较多的一种,这种方法就需要使用数据库了,把字典统一保存保存在一张表中,当项目启动的时候加载到一个 Map 中。
Map 中的值有一定的规律,map 的就 key 怎么定义看你自己,一般是将字典先分组再取对应关系。比方说城市组的代号是 city,在 city 下的 001 代表的是北京。那 Map 的结构可以是 city 为主键 value 是一个子 Map。子 Map 中存放的就是城市编号和具体城市的映射。
我在网上看到另一种分组的,拿过来和大家分享一下。一条 dict 记录可以分为哪个表下的哪个字段什么值,表示的什么值,对应到数据库和 Map 中我们可以这样设计。
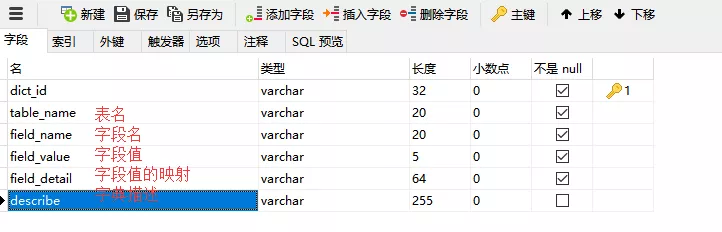
而 Map 中的 key 为 tableName_fieldName_fieldValue 值为 field_detail 。同样的在这里我们可以加载配置文件到 Map 中,这里可以选择加载一些系统级的配置。
public class BaseDictUtil {
@Autowired
private static BaseDictDao dicDao;
private static HashMap<String, String> hashMap = new HashMap<>();
private final static Logger logger = LoggerFactory.getLogger(BaseDictUtil.class);
// 静态方法在程序启动的时候只加载一次,这样为了让查询方法只去数据库查询一次
static {
// 获取应用上下文对象
@SuppressWarnings("resource")
ApplicationContext ctx = new ClassPathXmlApplicationContext("classpath:applicationContext-dao.xml");
// 获取dicDao实例
dicDao = ctx.getBean(BaseDictDao.class);
queryDic();
}
// 加载配置文件
static {
logger.info("======= Start load Properties =====");
Properties webapp_prop = new Properties();
Properties base_prop = new Properties();
try {
webapp_prop.load(BaseDictUtil.class.getResource("/webapp.properties").openStream());
hashMap.put("webapp_project_name", webapp_prop.getProperty("webapp_project_name"));
base_prop.load(BaseDictUtil.class.getResource("/base_dict.properties").openStream());
hashMap.put("base_dict.dict_type_code.001", base_prop.getProperty("base_dict.dict_type_code.001"));
logger.info("======= End load Properties =====");
} catch (IOException e) {
logger.error(e.getMessage(), e);
}
}
// 从数据库中取值放入到HashMap中
public static void queryDic() {
List<BaseDict> dics = dicDao.selectAll();
for (int i = 0; i < dics.size(); i++) {
BaseDict dic = dics.get(i);
String tableName = dic.getTable_name();
String fieldName = dic.getField_name();
String fieldValue = dic.getField_value();
String key = tableName + "_" + fieldName + "_" + fieldValue;
String value = dic.getField_detail();
logger.info(key + " ---> " + value);
hashMap.put(key, value);
}
}
public static String getFieldDetail(String tableName, String fieldName, String fieldValue) {
StringBuilder sb = new StringBuilder();
StringBuilder keySb = sb.append(tableName).append("_").append(fieldName).append("_").append(fieldValue);
String key = keySb.toString();
String value = hashMap.get(key);
return value;
}
public static String getProperties(String key) {
return hashMap.get(key);
}
public static void main(String[] args) {
String detail = BaseDictUtil.getFieldDetail("customer", "cust_level", "2");
System.out.println(detail);
System.out.println(getProperties("webapp_project_name"));
}
}
到上面为止,我们已经把字典处理好了,获取实体中的数据很简单,但是现在来了一个问题,我们该如何将两者结合起来,是先在后台处理好数据传到前台还是分别传到前台再由前台处理映射关系呢?
这个问题可真的难为我了,有一个很蠢的办法,获取实体数据的时候我们一条一条的映射,最终返回给前台处理好的结果。可作为一个后台工程师,这不是我想的,然而,处理前台我功力又不行。唉
功能的事到此就结束了,后面主要想谈谈关于前后端分离的事,之前前后台不分家,后端工程师是又当爹又当妈。既要处理数据又要处理页面,很恶心。
但是曙光来了,现在提倡前后台分离,作为后端工程师的我来说,那真的是高兴呀。随之而来的就是 JSP 页面被抛弃了,改用 HTML + JS 或是前段框架 + JS 。
为什么要抛弃 JSP 呢 ?
1、数据和静态资源都放在一起,各种请求 CSS、JS、图片的请求会增加服务器的压力。
2、JSP 必须要在支持Java 的 web 容器中运行(类如 tomcat),无法使用 nginx。
3、第一次请求 JSP 必须在 web 容器中将 JSP 转化为 Servlet,所以首次访问比较慢。
4、JSP 页面中内容比较杂,有 html、各种标签、JS ,给前端看前端头疼,给后端看后端头疼,不易分工。
5、如果 JSP 中的内容很多,页面响应会很慢,因为是同步加载。
以前开发步骤是这样
1、客户端发出请求。
2、服务端的 Servlet 或 Controller 接收请求(路由规则由后端制定,整个项目开发的权重大部分在后端)。
3、调用 service、dao 代码完成业务逻辑。
4、返回 JSP。
5、JSP 展现一些动态的代码。
前后端分离之后是这样
1、浏览器发送请求。
2、直接到达 html 页面(路由规则由前端制定,整个项目开发的权重前移)。
3、html 页面负责调用服务端接口产生数据(通过 ajax 等等)。
4、填充 html,展现动态效果。
而前后端更多的是采用 JSON 来进行数据交互,通过 ajax 来异步加载数据,所以一个项目不管数据量多么复杂,都可以轻松的访问,不像以前那样通过一个请求一股脑的把所有的数据都返回。
说了这么多前后端分离的好,然,我自己写的 demo 并没有前台来照顾,不说了,默默的搬砖去了……