本人上一篇博客写到 使用scrapy框架 + redis数据库增量式爬虫 :爬取某小说网站里面的所有小说!在查看小说网站的全部小说可以知道,该小说网站起码有100+本小说,每本小说起码有1000+的章节,要是使用单台电脑抓取的话是比较慢的!
这里写下在scrapy框架里面:使用scrapy_redis组件,给原生的scrapy框架,提供可以共享的管道和调度器,让分布式电脑机群执行同一组程序,对同一组资源进行联合且分布的数据爬取,实现scrapy框架+scrapy_redis组件的分布式爬虫。
1、安装scrapy_redis组件:pip install scrapy_redis
这里使用: scrapy startproject ProName > cd ProName > scrapy genspider spiderName www.xxx.com 创建scrapy工程和爬虫文件
创建好scrapy工程后,在配置文件settings.py里面设置USER_AGENT和ROBOTSTXT_OBEY,不要设置LOG_LEVEL = 'ERROR'(分布式爬虫需要看全部的日志):
USER_AGENT = '自己设置User_Agent'
ROBOTSTXT_OBEY = False #不遵从robots协议
** spiderName.py 爬虫文件的代码: **
import scrapy
from xsbookfbsPro.items import XsbookfbsproItem
from scrapy_redis.spiders import RedisCrawlSpider #导包
#from scrapy_redis.spiders import RedisSpider要是上面的用不了,用这个试试(用这个记得下面的class(用这个RedisSpider))
# class XsbookSpider(scrapy.Spider):#之前的类不要
class XsbookSpider(RedisCrawlSpider):#改成这个
name = 'xsbook'
# allowed_domains = ['www.xxx.com']
# start_urls = ['https://www.xsbooktxt.com/xiaoshuodaquan/'] == redis_key
redis_key = 'sunxsbook' #可以被共享的调度器队列的名称(可以自己定义名称)
#最后是需要在redis数据库里面手动添加一个起始url到redis_key表示的队列里面,数据解析的url要补充完整
def parse(self, response):
href_list = response.xpath('//div[@class="novellist"]/ul/li')
for href in href_list:
xs_url = href.xpath('./a/@href').extract_first()
item = XsbookfbsproItem()
item['xs_url'] = xs_url
yield scrapy.Request(url=xs_url, callback=self.parse_detail, meta={'item': item})
def parse_detail(self, response):
item = response.meta['item']
xs_name = response.xpath('//*[@id="info"]/h1/text()').extract_first()
href_list = response.xpath('//*[@id="list"]/dl/dd')[6:]
item['xs_name'] = xs_name
for href in href_list:
href_url = item['xs_url'] + href.xpath('./a/@href').extract_first()
yield scrapy.Request(url=href_url, callback=self.requests_data, meta={'item': item})
def requests_data(self, response):
item = response.meta['item']
href_title = response.xpath('//div[@class="bookname"]/h1/text()').extract_first()
#trans = href_title.maketrans('/:*?"<?|', ' ')
#href_title = href_title.translate(trans)
#href_title = href_title.replace(' ', '') # 处理windows系统特殊符号导致无法保存数据文件(保存数据命名出错的问题)
content = '
'.join(response.xpath('//div[@id="content"]/text()').extract())
content = content.replace('请记住本书首发域名:xsbooktxt.com。顶点小说手机版阅读网址:m.xsbooktxt.com', '')
content = '
'.join(content.split()) # 处理下载小说章节文字排版问题
item['href_title'] = href_title # 在小说章节内容里面找小说章节标题,在小说章节url里面找的话 和小说的章节内容对不上
item['content'] = content
yield item
ok,这样spiderName.py 爬虫文件就写好了,接下来对 settings.py 项目的配置文件设置:
#在settings.py 项目的配置文件加入下面的
# 增加了一个去重容器类的配置, 作用使用Redis的set集合来存储请求的指纹数据, 从而实现请求去重的持久化
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 使用scrapy-redis组件自己的调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 配置调度器是否要持久化, 也就是当爬虫结束了, 要不要清空Redis中请求队列和去重指纹的set。如果是True, 就表示要持久化存储, 就不清空数据, 否则清空数据
SCHEDULER_PERSIST = True
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 400
}#使用scrapy_redis组件的管道,该管道只可以将item写入redis
REDIS_HOST = 'redis服务器ip地址'
REDIS_PORT = 6379
#有redis密码,打开下面的
#REDIS_ENCODING = 'utf-8'
#REDIS_PARAMS = {'pasword':'123456'}
ok,这样 settings.py 项目的配置文件就设置好了,接下来配置redis的配置文件(redis.window.conf):
1、解除默认绑定:把56行的 bind 127.0.0.1 注释掉,变成(#bind 127.0.0.1)
2、关闭 保护模式:把75行的 protected-mode yes 改成 protected-mode no
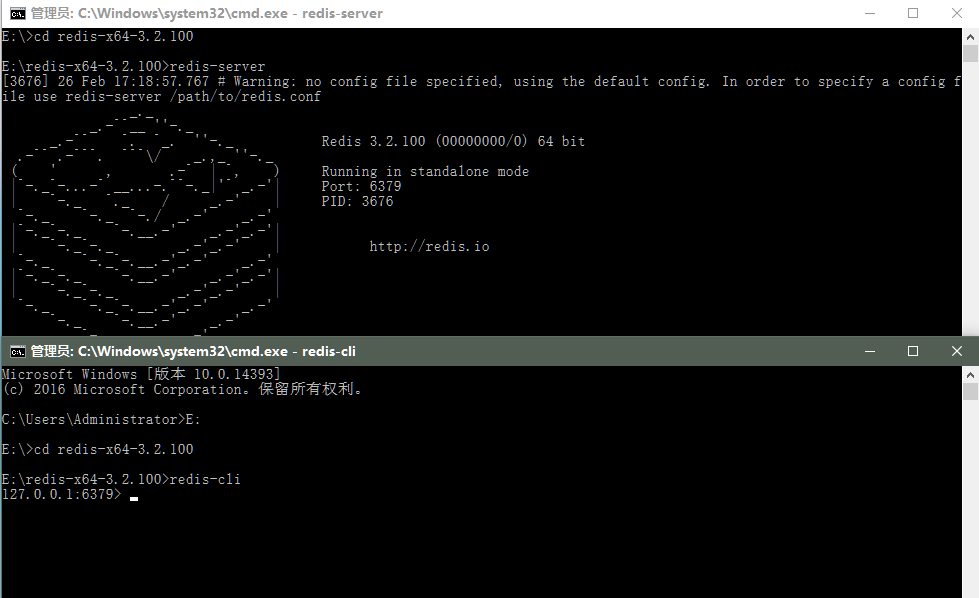
启动redis服务 : redis-server.exe redis.windows.conf
启动redis客户端:redis-cli
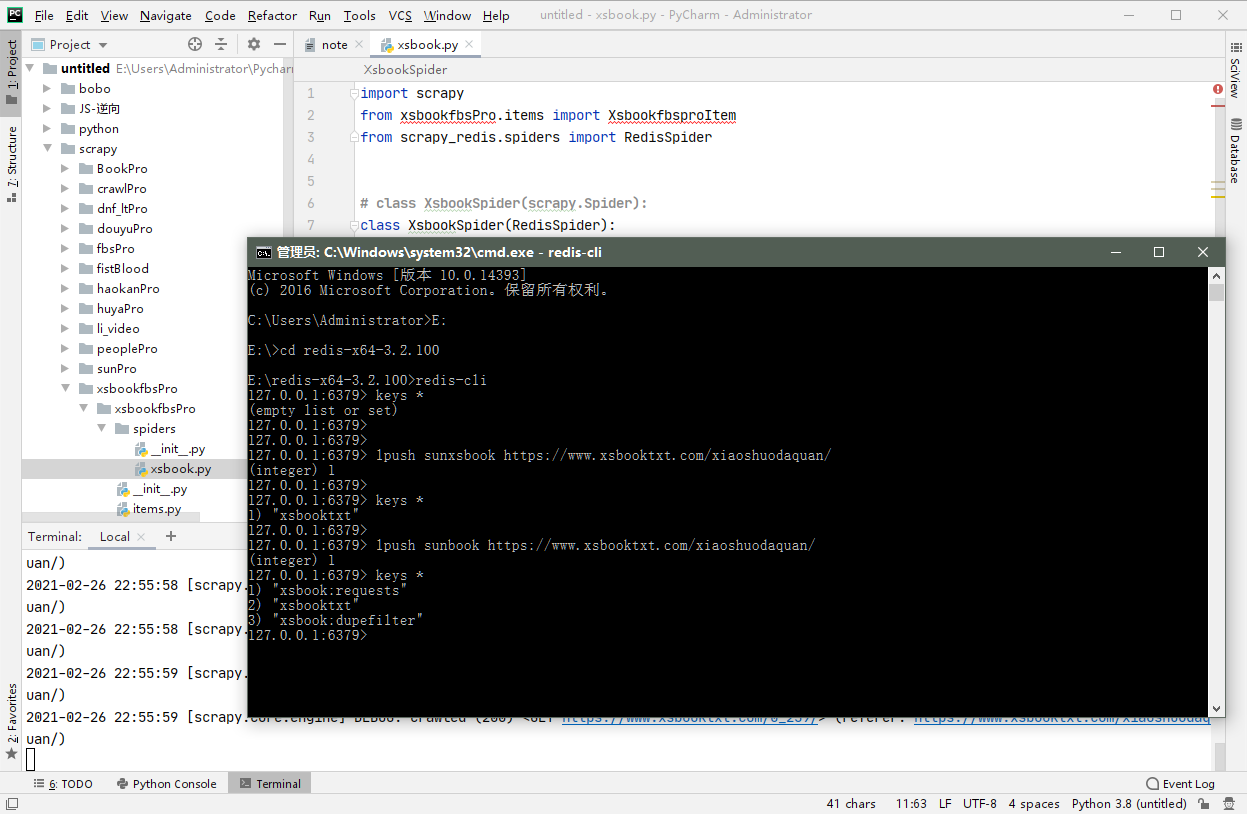
执行scrapy工程:scrapy crawl spiderName 执行后工程程序就会监听本地的redis服务
向调度器的队列中扔入一个起始的url: 在 redis-cli:lpush > redis_key自己定义的 > start_urls
爬取的数据保存在redis proName:items(requests)命名的数据结构中