1.抓取索引页内容
利用requests请求目标站点,得到索引网页HTML代码,返回结果
2.抓取详情页内容
解析返回结果,得到详情的链接,并进一步抓取详情页的信息
3.下载图片与保存数据库
将图片下载到本地,并把页面信息及图片URL保存至MongDB
4.开启循环及多线程
对多页内容遍历,开启多线程提高抓取速度
整理好思绪后就可以进入实操:
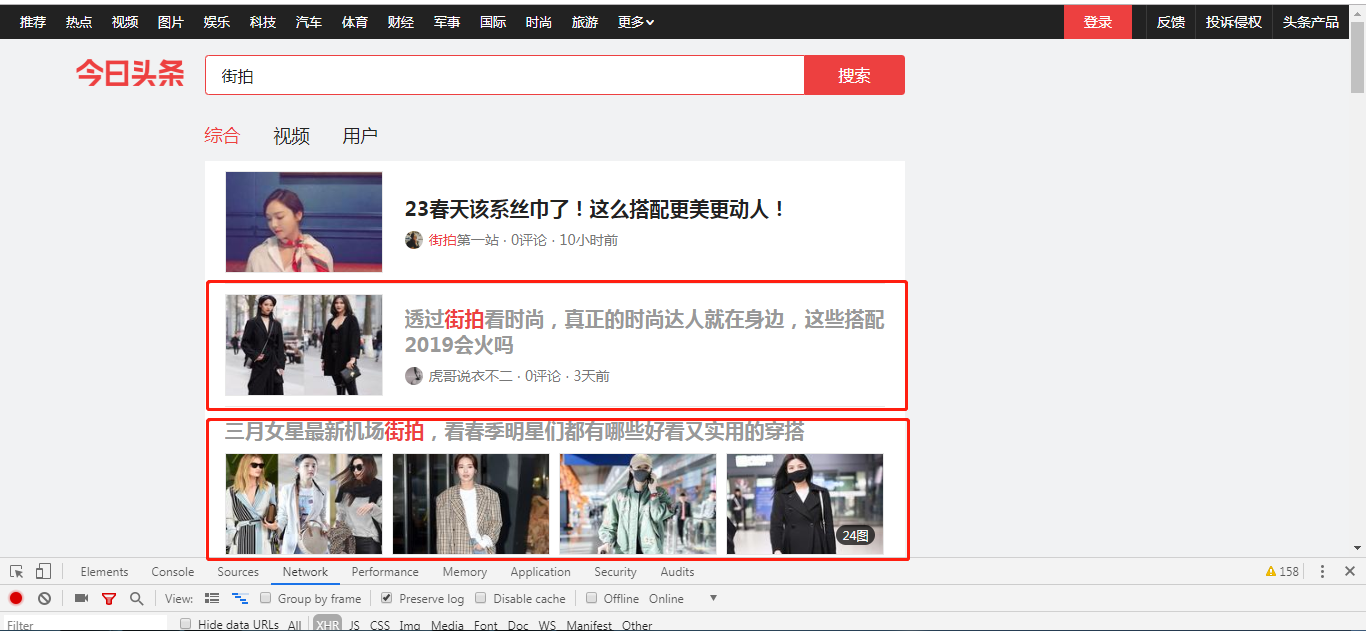
1.打开今日头条,输入街拍,呈现两种图片类型,一种是非图集形式的,就是点进去一直下拉就能看到图片的那种;另一种就是组图形式,点进去有个小箭头的……后者就是我们今天要爬取的内容(图片形式如下图所示,注意:街拍页面已经改了,)
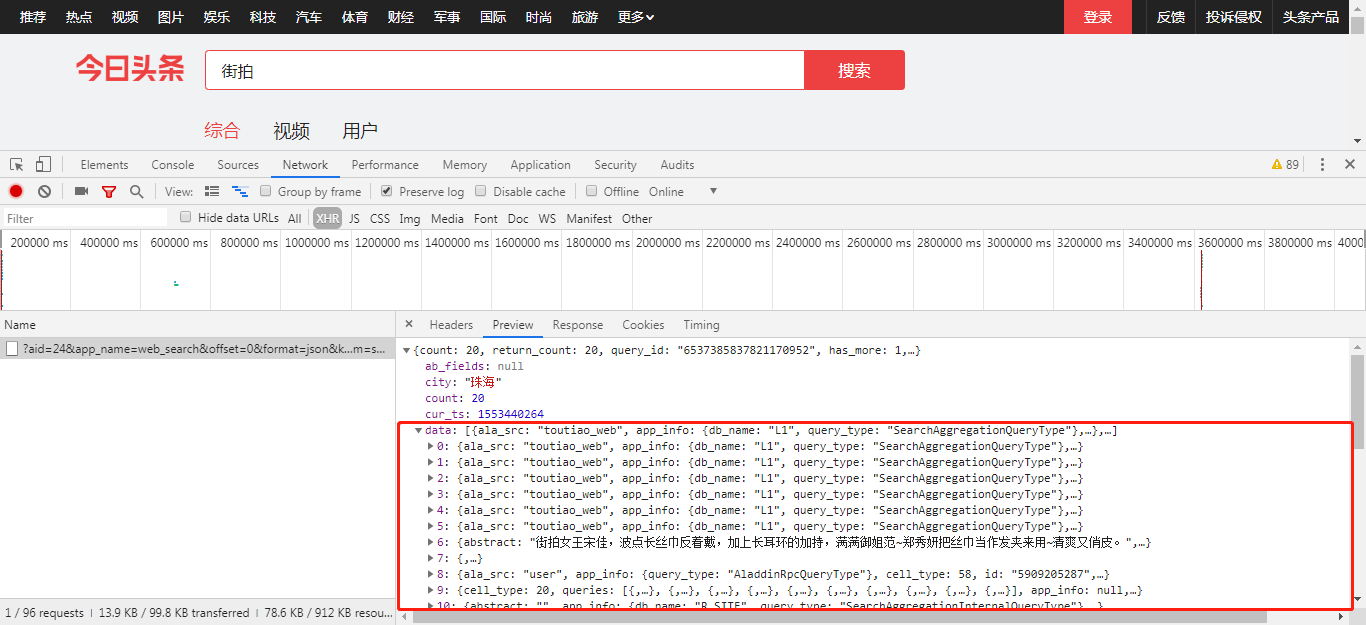
2.踩点,打开审查元素,一顿操作后发现终于找到点蛛丝马迹,没错,下面这个JSON对象的data键正是我们要找的东西
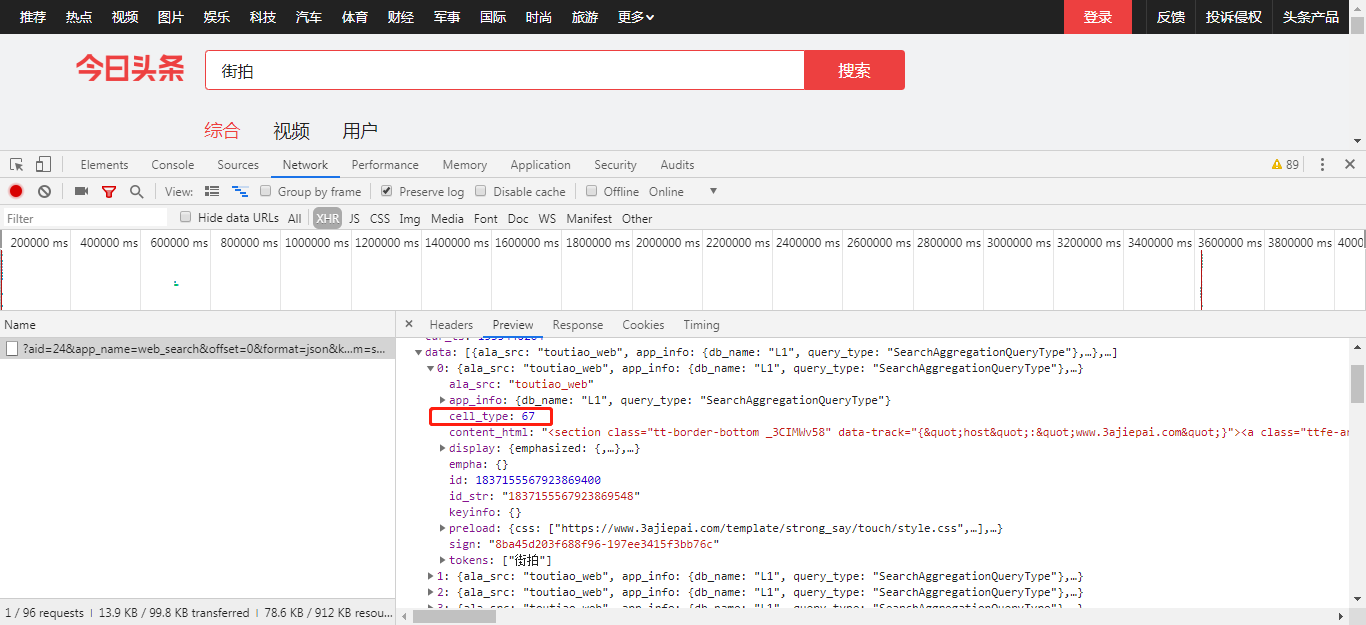
3:分析,data里面有个cell_type:67的都没有图片信息(这个可以作为后面过滤URL的条件),有图片信息的在下拉过程中会出现一个title和article_url的东西,我们最终要的就是article_url这个键值对
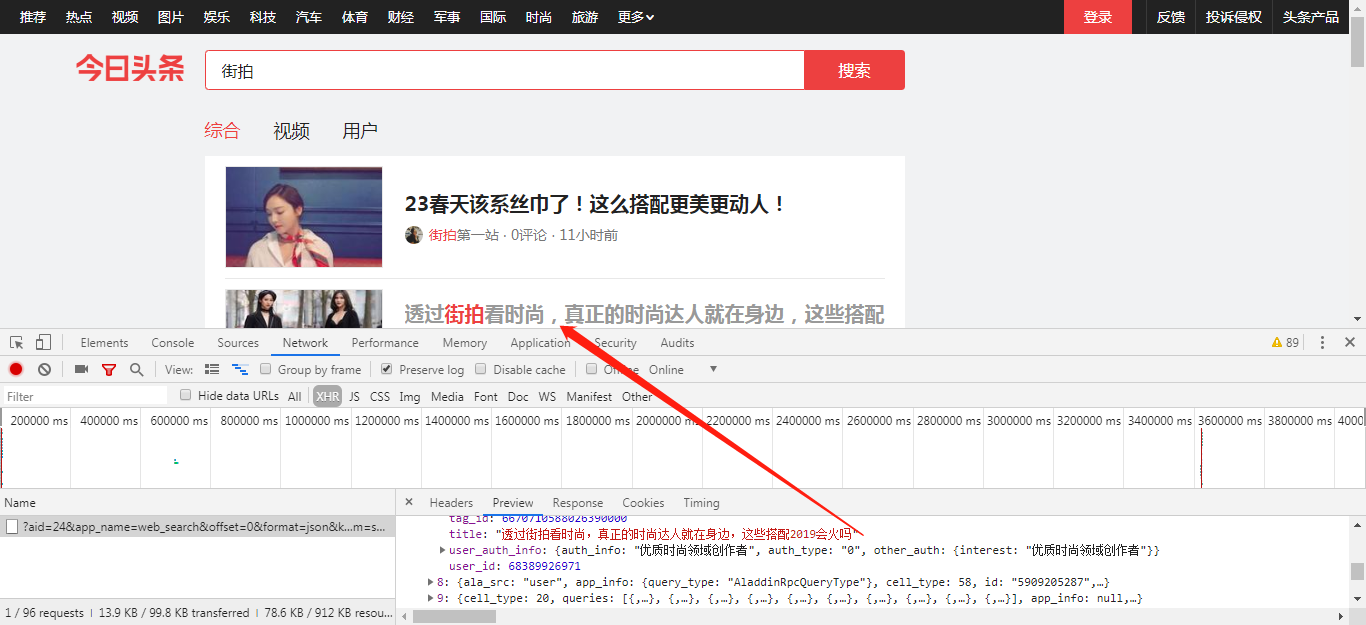
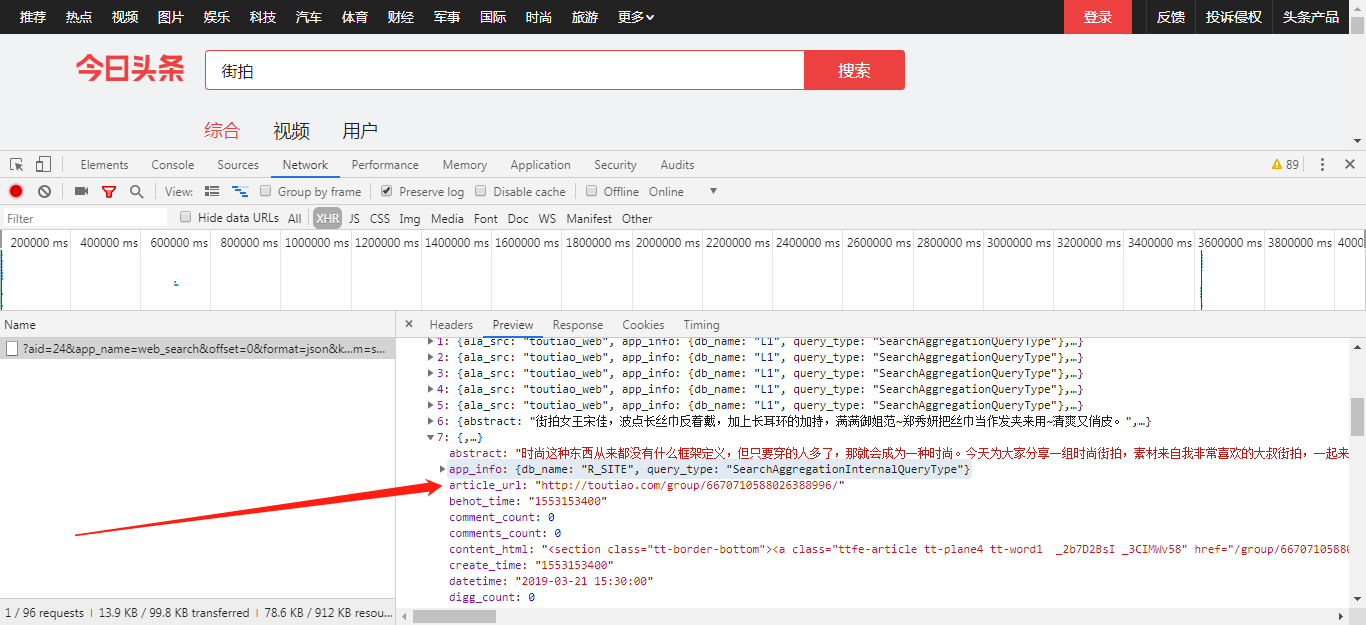
4.那这个article_url就是我们爬取组图最终URL了吗?并不是的,我们前面已经有讲到过,街拍的页面有两种图片类型,我们爬取的组图形式只是其中一种;此外,除了这两种形式还有其他乱七八糟的图片,视频也有,这些我们都要进行过滤……以下就是进行筛选并得到正确URL的方法:
def parse_page_index(html):
try:
data = json.loads(html)
if data and 'data' in data.keys():
for item in data.get('data'):
if item.get('cell_type') or item.get('article_url')[:25] != 'http://toutiao.com/group/':
continue
# print(item.get('article_url'))
item_str_list = item.get('article_url').split('group/')
item_str = 'a'.join(item_str_list)
yield item_str
except JSONDecodeError:
print('解析索引页出错')
return None
5.拿到组图URL后接下来就可以找图片具体URL了,点进去,查看审查元素,一顿操作后发我们要找的图片URL就在箭头所指的地方
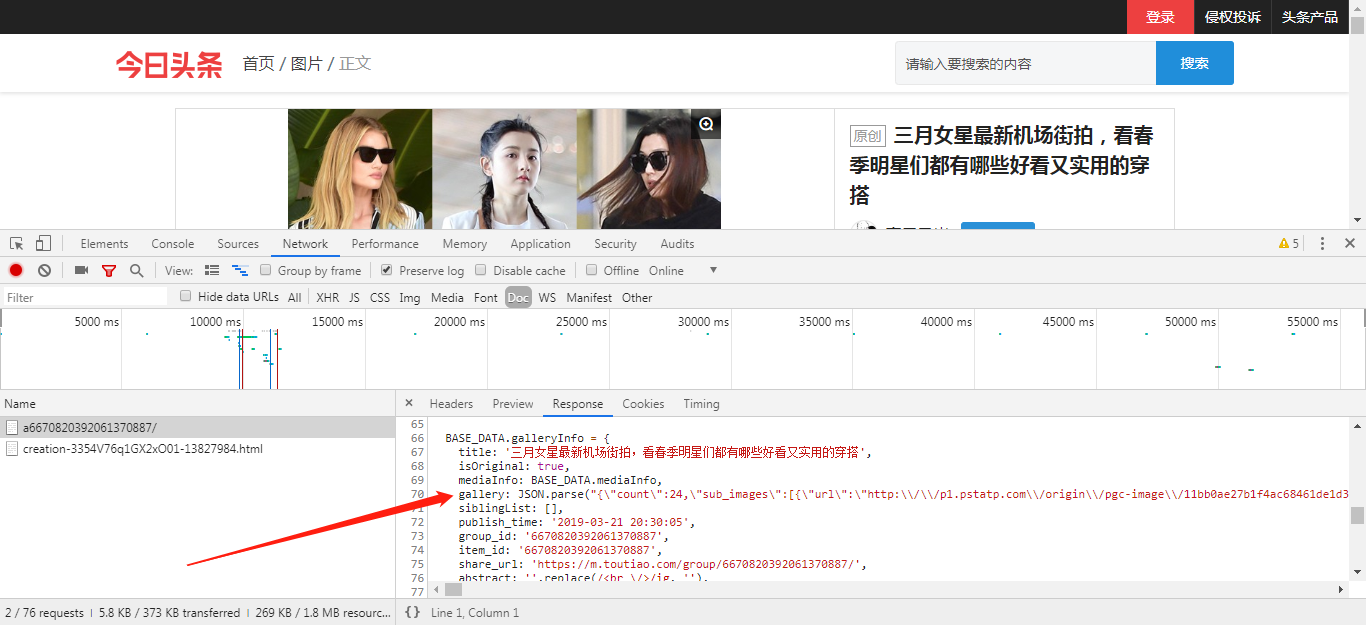
6.对图片URL进行提取,这里采用的是正则表达式:
def parse_page_detail(html,url):
images_pattern = re.compile(r'BASE_DATA.galleryInfo.*?gallery: JSON.parse.*?"(.*?)"),',re.S)
result = re.search(images_pattern,html)
if result != None:
soup = BeautifulSoup(html, 'lxml')
title = soup.select('title')[0].get_text()
data = re.sub('\\"' ,'"' , result.group(1))
data = re.sub(r'\\' ,'' , data)
data = json.loads(data)
if data and 'sub_images' in data.keys():
sub_images = data.get('sub_images')
images = [item.get('url') for item in sub_images]return {
'title':title,
'url':url,
'images':images
}
7.到这组图URL和图片具体URL就都找到了,接下来把完整代码贴上:


#coding=utf-8 import json from hashlib import md5 from json import JSONDecodeError import os import pymongo from bs4 import BeautifulSoup from requests.exceptions import RequestException import requests from urllib.parse import urlencode from config import * from multiprocessing.pool import Pool import re client = pymongo.MongoClient(MONGO_URL, connect=False) db = client[MONGO_DB] def get_page_index(offset,keyword): params = { 'aid': '24', 'offset': offset, 'format': 'json', 'keyword': keyword, 'autoload': 'true', 'count': '20', 'cur_tab': '1', 'from': 'search_tab', 'pd': 'synthesis' } base_url = 'https://www.toutiao.com/api/search/content/?' url = base_url + urlencode(params) try: headers = { 'cookie':'tt_webid=6671185381789402631; WEATHER_CITY=%E5%8C%97%E4%BA%AC; tt_webid=6671185381789402631; UM_distinctid=169a54e7c49461-05ea4429fa9817-5f123917-100200-169a54e7c4a295; csrftoken=055822d98a84680cbe8cfa838a1570f1; s_v_web_id=eef0fe1125759089850096d0ac06a160; CNZZDATA1259612802=400969098-1553254326-https%253A%252F%252Fwww.baidu.com%252F%7C1553410967; __tasessionId=xcskp1k3r1553436842875', 'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36' } resp = requests.get(url,headers = headers) if 200 == resp.status_code: return resp.text return None except RequestException: print('请求索引页出错') return None def parse_page_index(html): try: data = json.loads(html) if data and 'data' in data.keys(): for item in data.get('data'): if item.get('cell_type') or item.get('article_url')[:25] != 'http://toutiao.com/group/': continue # print(item.get('article_url')) item_str_list = item.get('article_url').split('group/') item_str = 'a'.join(item_str_list) yield item_str except JSONDecodeError: print('解析索引页出错') return None def get_page_detail(url): try: headers = { 'cookie':'tt_webid=6671185381789402631; tt_webid=6671185381789402631; WEATHER_CITY=%E5%8C%97%E4%BA%AC; tt_webid=6671185381789402631; UM_distinctid=169a54e7c49461-05ea4429fa9817-5f123917-100200-169a54e7c4a295; csrftoken=055822d98a84680cbe8cfa838a1570f1; CNZZDATA1259612802=400969098-1553254326-https%253A%252F%252Fwww.baidu.com%252F%7C1553389366; __tasessionId=imoxgst5g1553392002390; s_v_web_id=eef0fe1125759089850096d0ac06a160', 'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.75 Safari/537.36' } response = requests.get(url,headers = headers) if response.status_code == 200: return response.text return None except RequestException: print('请求详情页出错') return None def parse_page_detail(html,url): images_pattern = re.compile(r'BASE_DATA.galleryInfo.*?gallery: JSON.parse.*?"(.*?)"),',re.S) result = re.search(images_pattern,html) if result != None: soup = BeautifulSoup(html, 'lxml') title = soup.select('title')[0].get_text() data = re.sub('\\"' ,'"' , result.group(1)) data = re.sub(r'\\' ,'' , data) data = json.loads(data) if data and 'sub_images' in data.keys(): sub_images = data.get('sub_images') images = [item.get('url') for item in sub_images] for image in images: download_image(image) return { 'title':title, 'url':url, 'images':images } def save_to_mongo(result): if db[MONGO_TABLE].insert(result): print('存储到MongoDB成功',result) return True return False def download_image(url): try: response = requests.get(url) if response.status_code == 200: save_image(response.content) return None except RequestException: print('请求图片出错',url) return None def save_image(content): file_path = '{0}/{1}.{2}'.format(os.getcwd(),md5(content).hexdigest(),'jpg') if not os.path.exists(file_path): with open(file_path,'wb') as f: f.write(content) f.close() def main(offset): html = get_page_index(offset, KEYWORD) # print(html) for url in parse_page_index(html): # print(url) html = get_page_detail(url) if html: result = parse_page_detail(html,url) if result: save_to_mongo(result) if __name__ == '__main__': # main() groups = [x * 20 for x in range(GROUP_START, GROUP_END + 1)] pool = Pool() pool.map(main,groups)
1 MONGO_URL = 'localhost' 2 MONGO_DB = 'toutiao' 3 MONGO_TABLE = 'toutiao' 4 5 GROUP_START = 1 6 GROUP_END = 20 7 8 KEYWORD = '街拍'
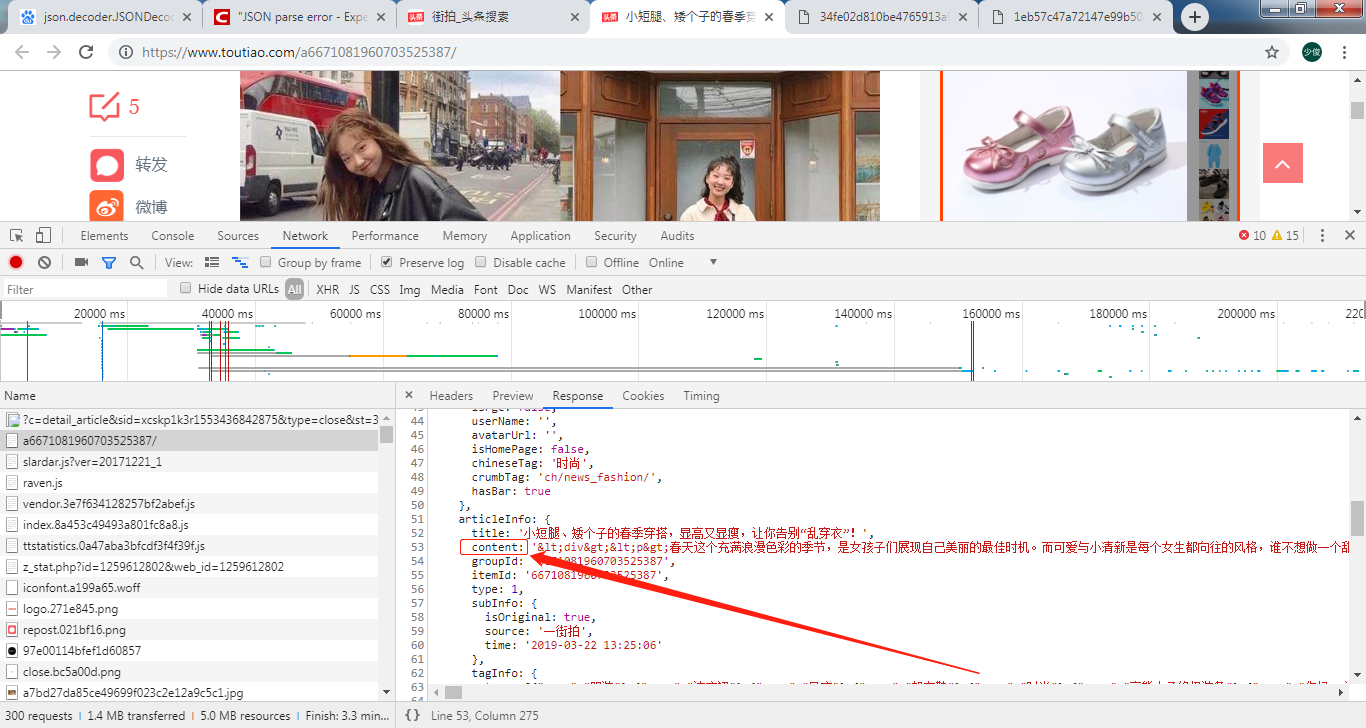
8.还记得开始我们讲的第一种图片形式么,其实主要就是图片具体URL找到然后提取下就行了,有兴趣的同学可以自己尝试去爬取下,就在下面这个位置:
注意:
现在网站普遍都有反爬措施,所以一般你代码爬取个两三次网站应该就会把你的IP给禁了,禁多久我就不清楚了,所以在此还是提醒大家科学上网!