1、TCP提供的是可靠传输,它通过接收方发送一个确认报文ACK来提供这种可靠性。但是数据报文和确认报文都可能会丢失,所以TCP会给发出的数据报文设置一个时间,如果超时了则进行重传
2、Karn's Algorithm:当发生了一次超时重传之后,我们不能根据发回的对于重传数据的ACK更新RTT和RTO(retransmission timeout 重传时间)的值。因为我们不知道这个ACK是对于第一次传送的数据的确认(可能是第一次发送的数据在网络中有延时或者是它对应的ACK报文有延时)还是对重传数据的确认。直到我们收到不是对应于重传数据的ACK报文,才能根据它更新RTT和RTO的值
3、Congestion Avoidance Algorithm:拥塞避免算法,首先设置两个变量,拥塞控制窗口cwnd,慢启动阈值ssthresh,然后按如下步骤操作:
1)初始化cwnd为一个报文段大小,ssthresh为65535个字节
2)TCP不能发送超过拥塞控制窗口(congestion window)和流量控制窗口(advertised window)之中较小值的数据
3)当发生拥塞时(超时或者收到三个重复的ACK),ssthresh被设置为当前窗口大小(两个窗口的较小值)的一半,并且如果拥塞是超时导致的,cwnd被设置为一个报文段大小
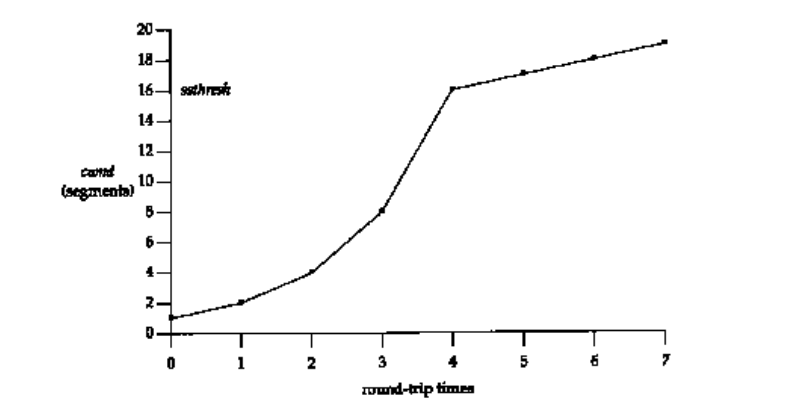
4)当有新的数据被确认时,我们增加cwnd的值,这时要根据cwnd和ssthresh之间的关系分别对待,当cwnd<ssthresh的时候,使用慢启动算法,即指数型增长cwnd,当cwnd>=ssthresh的时候就采用拥塞避免算法,线性增长cwnd,具体的实现如下图所示
4、Fast Retransmit and Fast Recovery Algorithms:快速重传和快速恢复算法,当发送方收到三个重复的ACK报文段时,说明对应的报文段丢失了,于是没有等到超时,发送方就重发了相应的报文段,这就是快速重传。而且重传之后直接进入拥塞避免而不进入慢启动,这就是快速恢复。这里需要注意的是,当接收方收到一个乱序的报文段时,会立即发送ACK报文,告诉发送方自己收到了一个乱序的报文并且说明自己想得到的报文段的序号
5、TCP连接通常会遇到source quench,host unreachable,network unreachable这三类ICMP错误报文。当收到source quench时,通常会导致cwnd变为一个报文段,然后慢启动,但是ssthresh不变。当收到host unreachable 和 network unreachable这类报文时,通常会将它忽略,然后不断重传数据,当然,最后可能因为超时而终止
6、当发生超时重传的时候,TCP不一定要重传和之前一模一样的报文段,而是可以接下来要传输的数据也放到重传的报文段中,称为repacketization,这可以提高传输的效率。之所以能够这样做,是因为TCP是通过传输数据的字节编号来进行确认的,而不是传输的报文段的编号