Linux三剑客之awk
一、grep
1、描述
grep searches the named input FILEs (or standard input if no files are named, or if a single hyphen-minus (-) is given as file name) for lines containing a match to the given PATTERN. By default, grep prints the matching lines.(个人理解:使用指定模式从文件中筛选中匹配的信息)
2、grep增强命令
egrep:等同于grep -E
3、使用规则
# grep 参数 匹配模式 文件 grep [OPTIONS] PATTERN [FILE...]
4、常用参数详解
-
-V, --version Print the version number of grep to the standard output stream. This version number should be included in all bug reports (see below).代码示例:
[root@doctor-10 ~]# grep -V grep (GNU grep) 2.20 Copyright (C) 2014 Free Software Foundation, Inc. License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>. This is free software: you are free to change and redistribute it. There is NO WARRANTY, to the extent permitted by law. Written by Mike Haertel and others, see <http://git.sv.gnu.org/cgit/grep.git/tree/AUTHORS>
-
-E 使用扩展正则表达式;
常见的扩展规则符号:+ | () { }
-E, --extended-regexp Interpret PATTERN as an extended regular expression (ERE, see below). (-E is specified by POSIX.)代码案例:
#筛选出/etc/passwd中的普通用户 [root@doctor-10 /etc]# grep 'bash' /etc/passwd root:x:0:0:root:/root:/bin/bash hadoop:x:1000:1000::/home/hadoop:/bin/bash [root@doctor-10 /etc]# grep 'bash+' /etc/passwd #无法识别扩展正则符号(错误写法) [root@doctor-10 /etc]# grep -E 'bash+' /etc/passwd #(正确) root:x:0:0:root:/root:/bin/bash hadoop:x:1000:1000::/home/hadoop:/bin/bash
-
-e 可以指定多个匹配模式
-e PATTERN, --regexp=PATTERN Use PATTERN as the pattern. This can be used to specify multiple search patterns, or to protect a pattern beginning with a hyphen (-). (-e is specified by POSIX.)代码案例:
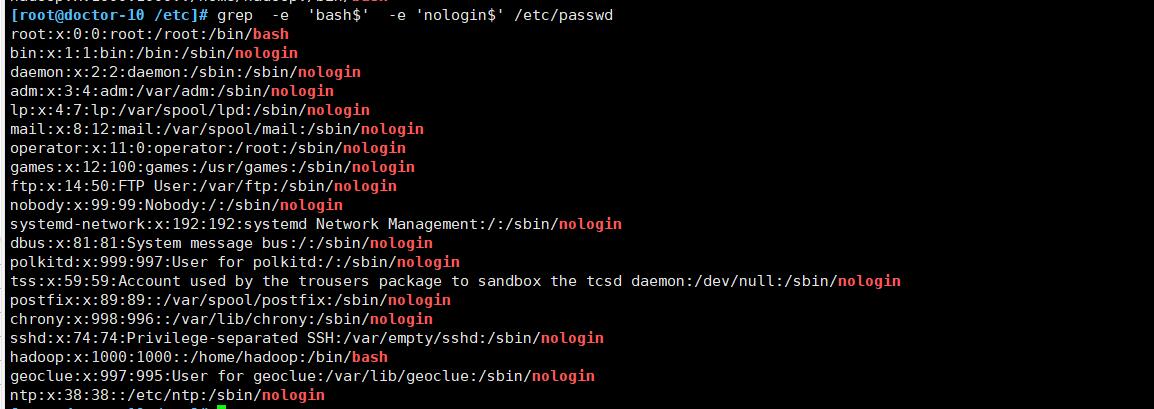
-
-v 打印出不满足匹配模式的行
-v, --invert-match Invert the sense of matching, to select non-matching lines. (-v is specified by POSIX.)代码案例:
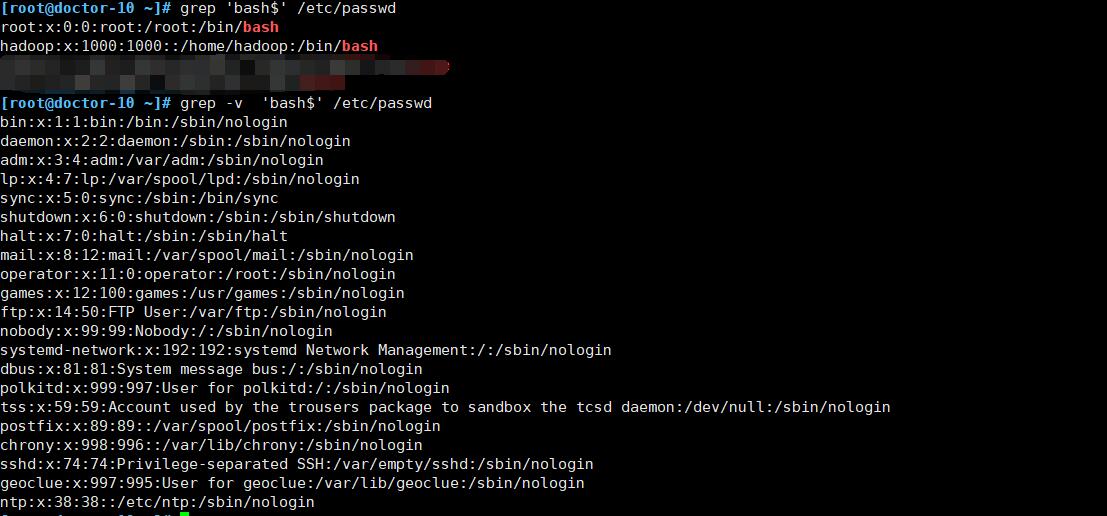
-
-c 统计出满足匹配模式的个数;
-c, --count Suppress normal output; instead print a count of matching lines for each input file. With the -v, --invert-match option (see below), count non-matching lines. (-c is specified by POSIX.)代码案例:

-
-n 显示满足匹配模式的行号
-n, --line-number Prefix each line of output with the 1-based line number within its input file. (-n is specified by POSIX.)代码案例:
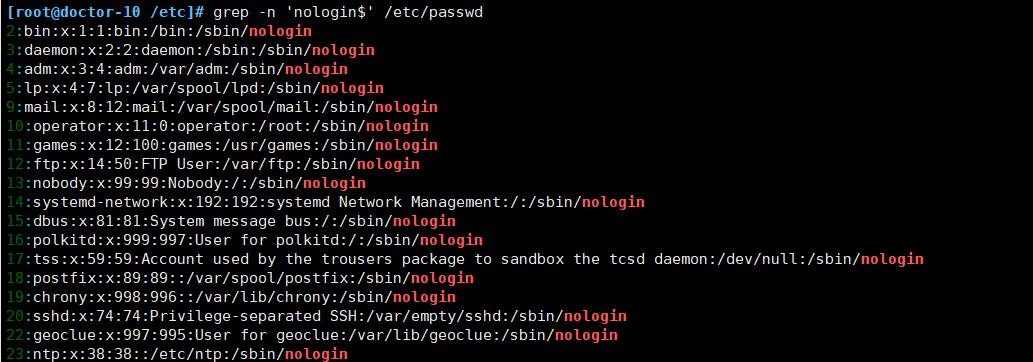
-
-A 打印出满足匹配模式的后# 行(# 指定要显示的行数)
-A NUM, --after-context=NUM Print NUM lines of trailing context after matching lines. Places a line containing a group separator (described under --group-separator) between contiguous groups of matches. With the -o or --only-matching option, this has no effect and a warning is given.代码案例:

-
-B 显示满足匹配模式的前#行(# 指定要显示的行数)
-B NUM, --before-context=NUM Print NUM lines of leading context before matching lines. Places a line containing a group separator (described under --group-separator) between contiguous groups of matches. With the -o or --only-matching option, this has no effect and a warning is given.代码案例:

-
-C 显示满足匹配模式的前后 #行(# 指定要显示的行数)
-C NUM, -NUM, --context=NUM Print NUM lines of output context. Places a line containing a group separator (described under --group-separator) between contiguous groups of matches. With the -o or --only-matching option, this has no effect and a warning is given.代码案例: