打开xlsx错误解决
使用pandas读取excel文件时,会调用xlrd库,由于xlrd更新至2.0.1版本后只支持xls文件,所以使用pd.read_excel(‘c:/文夹夹/aa.xlsx’)会出现报错。
解决方法:
使用pd.read_excel(‘c:/文件夹/aa.xlsx’,engine=‘openpyxl’)
Series和DataFrame之间概念区别

Series 一维数据,一行或者一列 以及转换成列表
1.1 创建一个Series,可以用列表或者一个字典,如果是列表,index值默认就是自增的id,当然也可以指定index
p = pd.Series([1,2,3,"four","5",6.0],index=["第1个","第2个","第3个","第4个","第5个","第6个"])
# print(p.index) # Index(['第1个', '第2个', '第3个', '第4个', '第5个', '第6个'], dtype='object') 是个列表可以按列表取值
# print(p.values) #[1 2 3 'four' '5' 6.0] 此时是一个numpy的数组
# print(p.values.tolist() #[1 2 3 'four' '5' 6.0] 此时是一个数组
1.2 也可以用一个字段创建,key就是index,value就是value,字典的形式serise被包含在一个元祖内.
p1 = pd.Series({"第一个":1,"第二个":2,"第三个":3,"第四个":"four","第五个":5.0}),
2.1 数据查询
print(p[["第1个","第2个"]]) #查询多个值,返回的是series
print(p["第1个"]) #查询一个值返回的就是那个值本身
DataFrame 二维数据或者多维的数据,多行多列,除了index行索引外,还有个columns列索引
1.1 创建一个DataFrame,用字典形式创建,key值变成列索引
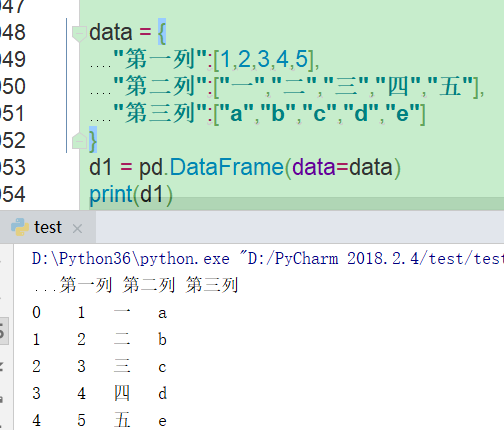
1.2 从excel csv txt文本读取也是返回一个DataFrame对象
2.1 从DataFrame对象中读取一个Series对象
查询列
print(d1["第一列"])
print(d1[["第一列","第二列"]])
查询行
print(d1.loc[1:])
print(d1.loc[:2])
print(d1.loc[0:4]) #和python语法不同,loc是闭区间.
查询数据的方法

用读取csv,并且设置日期为首列为例
p = pd.read_csv(pth,encoding="gbk",)
p.set_index("日期",inplace=True)
print(p.head(10)) #数据如下

一. df.loc 通过标签索引字符串查询数据
#1.1使用单个label查询数值 行或者列,传入单个值,精确匹配,得到一个值
print(p.loc["2011/3/1","天气情况"]) #>>>> 多云
#使用多个label查询数值 ,传入多个值,得到一个series
print(p.loc["2011/3/1",["天气情况","最高温度"]])
'''
天气情况 多云
最高温度 5℃
Name: 2011/3/1, dtype: object
'''
# 1.2使用多个值批量查询
print(p.loc[["2011/3/1","2011/3/3"],"天气情况"])
'''
日期
2011/3/1 多云
2011/3/3 晴
Name: 天气情况, dtype: object
'''
#1.3使用值的区间查询
#行index按区间查询
print(p.loc["2011/3/1":"2011/3/3","天气情况"])
#列index按区间查询
print(p.loc["2011/3/1","最低温度":"天气情况":])
#行和列都按区间查询,返回一个DataFrame
print(p.loc["2011/3/1":"2011/3/3","最低温度":"天气情况":])
#1.4使用条件表达式查询 找到天气情况为乌云的所有列表数据
print(p.loc[p["天气情况"] =="多云",:])
#多个条件用逻辑符号,每个条件用括号包裹进行过滤
print(p.loc[(p["天气情况"] =="多云") |( p["天气情况"] =="晴~多云"),:])
#1.5使用函数形式进行条件查询
print(p.loc[lambda x:(x["天气情况"] =="多云") |( x["天气情况"] =="晴~多云"),:])
#1.6使用自定义函数形式进行条件查询
#df默认index是日期,把日期强转字符串,过滤出2011年的天气晴的日期
def aa(df):
return (df.index.str.startswith("2011")) & (df["天气情况"] =="晴")
print(p.loc[aa, :])
二. df.iloc 通过标签索引数字查询数据 待补充
3.1 数据新增的4中方法
# 1.直接赋值,我们来新增一列最高温度和最低温度差
# 让我们把下面的温度去除单位并改变类型为整数类型便于计算
p.loc[:,"最高温度"]=p.loc[:,"最高温度"].str.replace("℃","").astype("int")
p.loc[:,"最低温度"]=p.loc[:,"最低温度"].str.replace("℃","").astype("int")
#然后新增温差列,这里就是2个Series列相减,并返回一个Series列
p.loc[:,"温差"]=p["最高温度"]-p["最低温度"]
print(p.head(10))
# 2.df.apply
#apply处理的是一个Series列,并且用axis参数标注Index是行索引还是列索引,默认是axis是1为列索引,0是为行索引
#比如添加一列做判断,如果最高温度>=10为高温,反之为低温
def wendu(x):
if x["最高温度"]>=10:
return "高温"
else:
return "低温"
p.loc[:,"最高温度"]=p.loc[:,"最高温度"].str.replace("℃","").astype("int")
p.loc[:,"最低温度"]=p.loc[:,"最低温度"].str.replace("℃","").astype("int")
p.loc[:,"高温低温判断"] = p.apply(wendu,axis=1)
print(p.head(10))
print(p["高温低温判断"].value_counts()) #对Series单列的数据进行聚合统计
'''高温 1038
低温 58
Name: 高温低温判断, dtype: int64'''
# 3.df.assgin 可以同时添加多个列到DateFrame,和apply不同,不用指定axis,而是直接指定列的索引
#我们把最高温度和最低温度都加10,assign方法不会修改原数据,
p.loc[:,"最高温度"]=p.loc[:,"最高温度"].str.replace("℃","").astype("int")
p.loc[:,"最低温度"]=p.loc[:,"最低温度"].str.replace("℃","").astype("int")
p =p.assign(
#add_10 就是一个新的列名索引
add_10 = lambda x:x["最高温度"]+10,
add2_10 = lambda x:x["最低温度"]+10,
)
print(p.head(10))
# 4.按条件选择分组分别赋值
#高低温差大于10度算温差大,先创建一个新列
p["温差大吗"]="" #pandas会用广播语法对列的每行都赋值为空值
p.loc[:,"最高温度"]=p.loc[:,"最高温度"].str.replace("℃","").astype("int")
p.loc[:,"最低温度"]=p.loc[:,"最低温度"].str.replace("℃","").astype("int")
p.loc[ p["最高温度"]- p["最低温度"]>10,"温差大吗"]="温差10度以上"
print(p.head(10))
4.1 pandas里的一些统计函数语法
p.loc[:,"最高温度"]=p.loc[:,"最高温度"].str.replace("℃","").astype("int")
p.loc[:,"最低温度"]=p.loc[:,"最低温度"].str.replace("℃","").astype("int")
print(p.head(10))
## Pandas统计函数
# 1.汇总类统计 describe 有针对数字列的各种汇总的计算,mean 平均值 std标准差 ,min最小值 max最大值
print(p.describe())
# 1.1 也可以计算某一列的统计数据
print(p["最低温度"].mean(),p["最低温度"].std())
# 2.唯一去重和按值计算 对于非数字类型的数据 有unique()唯一性去重 value_counts()按值计数
print(p["天气情况"].unique())
print(p["天气情况"].value_counts())
# 3.相关系数和协方差 cov()协方差矩阵 corr()相关系数矩阵 ,针对数字类型的数据
print(p["最低温度"].cov(p["最高温度"])) #查看最低温度和最高温度的协方差矩阵,
5.1 pandas对于缺失值的处理
- 对于这种excel,头2行为空,我们读取的时候可以用skiprows参数越过
p = pd.read_csv(pth,encoding="gbk",skiprows=2)

输入p.isnull() 会对所有行和列进行空值检测,返回布尔,当然也可以对单列进行空值检测,p["分数"].isnull()

或者用notnull()检测不为空的数据,p.loc[p["分数"].notnull(),:] # isnull和notnull 检测是否空值,用于Series和DataFrame

- 接下来我们把第一列为空的数据丢弃掉
# dropna:丢弃 删除缺失值
# axis: 删除行或者列 {0 or "index",1 or "columns"} 默认为0
#
# how:如果等于any 任何空值都能删除,all代表所有值为空才删除
#
# inplace, 布尔值,true 表示直接修改当前数据
p.dropna[axis="columns",how="all",inplace=True]

- 接下来我们把每一行都为空的行给删除掉
p.dropna[axis="index",how="all",inplace=True]

- 将分数列空值的填充为0分
# fillna 填充空值
# value 用于填充的值,可以是单个值,或者字典,key为列名,value为值
# method ffill(forward fill)使用前一个不为空的值 bfill(backword fill)使用后一个不为空的值
# axis: 按行或者列填充 {0 or "index",1 or "columns"} 默认为0
# inplace, 布尔值,true 表示直接修改当前数据
p.fillna({"分数":0}) 或者 p.loc[:,"分数"]=p["分数"].fillna(0)

- 将姓名列空值填充,这里根据规律的出用ffill方法
p.loc[:,"姓名"]=p["姓名"].fillna(method = "ffill")

- 保存
p.to_excel(pth,index=False)index=False 就是不要默认生成的index列

6.1 pandas的SettingWithCopyWarning的错误解决办法
官方文档解释https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy

pth = r"D:杂项py课程pandas est22.csv"
p = pd.read_csv(pth,encoding="gbk")
#pandas的SettingWithCopyWarning的错误解决办法
con = p["日期"].str.startswith("2011/3") # 设置过滤条件,取2011年3月份的数据
# p[con]["温差"] = 0 # 这里就会报错 SettingWithCopyWarning
'''
SettingWithCopyWarning的原因根据官方文档解释 是因为p[con]["温差"] 是分成2个步骤的,等于p.get[con].set["温差"]
第一步get获取到的数据是对DataFrame筛选后获取的子DataFrame对象,而这个子对象可能是copy,可能是view
view指的是子对象,对子对象的更改直接影响原DataFrame的更改,而copy是对原DataFrame的一个备份,不影响原始数据.
所以导致有时候成功有时候报错.
解决办法思路:我们把copy还是view给他定义清楚,然后再做set赋值操作.
一:用loc函数,loc函数是直接在原始DataFrame上操作,就是view操作
二:对筛选内容复制一份,直接在复制的子对象上操作
'''
#解决办法1: 用loc方法
p.loc[con,"温差"] = 0
#解决办法2: 复制出一个子对象,所有的结果对原始数据不存在影响
p1 = p[con].copy()
p1["温差"]=0
7.1 pandas的数据排序功能
pth = r"D:杂项py课程pandas est22.csv"
p = pd.read_csv(pth,encoding="gbk")
p.loc[:,"最低温度"] = p["最低温度"].str.replace("℃","").astype(int)
p.loc[:,"最高温度"] = p["最高温度"].str.replace("℃","").astype(int)
## pandas数据排序
'''
Series排序:
Series.sort_values(ascending=True,inplace =True)
DataFrame.sort_values(by,ascending=True,inplace =True)
by:字符串或者列表,用于单列排序或者多列排序
或者通过by和ascending 2个参数使用列表多多列进行自定义排序
'''
#Series排序
# print(p["最高温度"].sort_values(ascending=False))
#DataFrame 排序 多列都按升序排序
#天气情况 最高温度都按升序排列
p.sort_values(by=["最高温度","天气情况"],ascending=True,inplace=True)
#天气情况 按升序排列 最高温度按降序排列
p.sort_values(by=["最高温度","天气情况"],ascending=[True,False],inplace=True)
print(p.head(50))
8.1 pandas字符串的处理方法
pandas的字符串是默认支持正则语法
p = pd.read_csv(pth,encoding="gbk")
p.loc[:,"最低温度"] = p["最低温度"].str.replace("℃","").astype(int)
p.loc[:,"最高温度"] = p["最高温度"].str.replace("℃","").astype(int)
'''
pandas字符串处理
1.先获取Series的str属性,然后在属性上调用相关函数
2.只能使用于字符串数据,数字列不能用
3.DataFrame上没有str属性和处理方法
4.Series.str不是python原生的字符串,更多方法看官方文档https://pandas.pydata.org/docs/reference/series.html 搜索string handling
5.str是Series属性,而silce等方法是str的方法,不可以用p["最低温度"].slice调用,
多个方法可以反复用str.方法调用 比如:p["最低温度"]str.slice[:,6].str.repleace("!",".")
'''
9.1 pandas axis轴概念的理解


但是对于跨行或者跨列轴的概念理解,就是指定了那个axis就按另一个axis方向进行遍历.

10.1 pandas 数据合并

例如下面这组数据
data1 = pd.DataFrame(
{"姓名":["谢霆锋","张学友","梁静茹","谢霆锋","张学友","张韶涵"],
"歌曲": ["谢谢你的爱", "吻别", "勇气", "黄种人", "遥远的她","淋雨一直走"]}
)
data2 = pd.DataFrame(
{"姓名":["谢霆锋","刘德华","梁咏琪","张韶涵"],
"歌曲": ["因为爱所以爱", "17岁", "花火", "快乐崇拜"]}
)


d1 = pd.DataFrame({'姓名': ['张三', '张三', '王五'],'班级': ['1班', '2班', '1班'],'分数': [30,20,10]})
d2 = pd.DataFrame({'姓名': ['张三', '张三', '王五','王五'],'班级': ['1班', '1班', '1班','2班'],'分数': [80,50,60,70]})
# 当然on也可以加入列表,表示2张表用多个索引进行关联
d3 = pd.merge(d1,d2,on=["姓名","班级"],how="inner")

那么对于不同的索引值要怎么处理呢???
d1 = pd.DataFrame({'姓名': ['张三', '张三', '王五'],'班级': ['1班', '2班', '1班'],'分数': [30,20,10]})
d2 = pd.DataFrame([[40,"1班"],[70,"2班"],[5,"2班"]],index=["张三","李四","王五"],columns=["分数","班级"])
# d2的姓名变成了默认索引,这种情况下我们可以用left_on指定用d1的姓名数据,然后开启d2的right_index为true,让2个索引进行关联
d3 = pd.merge(d1,d2,left_on="姓名",right_index=True,how="inner")

11.1 index的意义
index 包括行index或者列index,本身不是数据本体内容,是pandas添加上去的,主要是为了更快的查找数据.
如果index是唯一的,pandas会使用哈希优化表,查找性能为1次 p.index.is_unique #判断index是否有唯一性
如果index不是唯一,但是有序的,会通过二分法查找,查询性能为指数级下降. p.index.is_monotonic_increasing #判断index是否单调递增
如果index不是唯一且无序的,每次查找都要扫描所有数据,性能最低下.
- 设置index 使用p.setindex("日期",inplace=True,drop=False),
把日期设置为索引列,drop默认是true, 默认情况下,日期列设置了索引列,就从列中删除了.如果设置false,在列中依旧显示.效果如下

例:平时我们查找2011年的数据,p.loc[p['日期']=="2011/3/1"],但是如果默认索引就是日期,那么p.loc["2011/3/1"] 查询结果一样,因为查询默认本身就是查索引
- 不同对象,但是相同的索引值是可以相互进行计算的,比如:
a = pd.Series([1,2,3],index=["a","b","c"])
b = pd.Series([1,2,3],index=["d","b","f"])
print(a+b) #结果只有b这个索引项会进行数值相加
- index有更多的强大的数据结构支持, (了解)
