词法分析主要有三个任务:分词、词性标注以及命名实体识别,句法分析主要是依存句法分析。本报告主要介绍分词、词性标注和依存句法分析。
一般在做依存句法分析任务时,都需要基于分词和词法分析的结果来做,所以报告内容这么安排也就很正常了。
目前解决这三个任务的方法主要有三种:基于序列标注的方法、基于转移(transition)的方法和基于图的方法。
分词
首先,来谈谈分词。
目前分词的几篇文章有:
复旦大学陈新驰有三篇文章:
- Long Short-Term Memory Neural Networks for Chinese Word Segmentation. Xinchi Chen. EMNLP 2015
- Gated Recursive neural network for chinese word segmentation. Xinchi Chen. ACL 2015
- Adversial Multi-criteria learning for chinese word segmentation. Xinchi Chen. ACL 2017(outstanding paper)
2015年百度有一篇用bilstm做命名实体识别,这里的话做分词,第一篇用bilstm,第二篇用gru,感觉这种论文就是比速度,第三篇文章考虑多准则(不同情况分词的标准不同),拿到了一个杰出论文奖。
除此之外,
State-of-the-art Chinese Word Segmentation with Bi-LSTMs. Ji Ma. EMNLP 2018
基本上是对bilstm做一个总结
Zen: Pre-training Chinese Text Encoder Enhanced by N-gram Representations, Shizhe Diao, 2019
把n-gram representation加到bert中,模型有点大
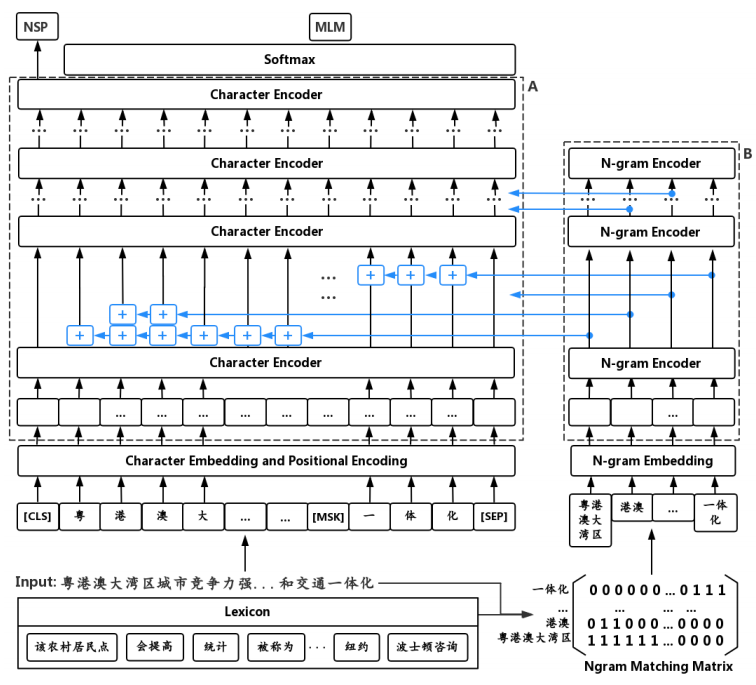
成绩相比BERT提升半个点
Towards Fast and Accurate Neural Chinese Word Segmentation with Multi-Criteria Learning, COLING 2020
又来一个多准则
Glyce: Glyph-vectors for Chinese Character Representations, 2020
基于BERT的提升也是微乎其微。
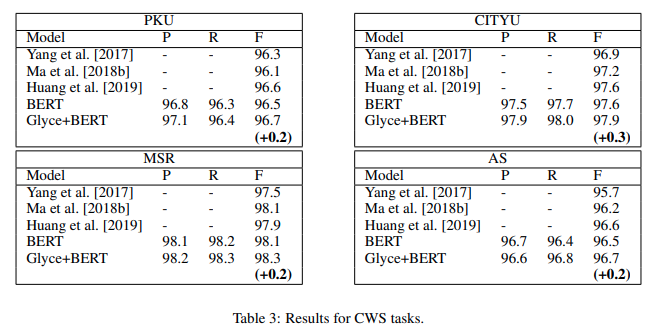
基于序列标注的方法是给字打标签,很难利用词级别的信息,为了引入词级别的信息可以采用以下三种方法:基于转移的方法、semi-CRF和DAG-LSTM/Lattice-LSTM。
- 基于转移的方法可以参考Transition-based Neural Network Word Segmentation, ACL 2016
- 基于Semi-CRF的方法可以参考Chinese Word Segmentation via BiLSTM+Semi-CRF with Relay Node
- 基于DAG-LSTM就是改进LSTM模型,将链式结构扩展到DAG结构,这里推荐:LatticeLSTM和Adversarial Multi-Criteria Learning for Chinese Word Segmentation, ACL 2017(outstanding paper)
词性标注
磁性标注一般都是比较简单,所以一般都是结合分词一起来做。
比如Joint CWS + POS Tagging的一篇文章A Feature-Enriched Neural Model for Joint Chinese Word Segmentation and Part-of-Speech Tagging, IJCAI 2017
该方法是使用BMES和词性的组合标签来给每个字打标签。
第二种方法是基于转移的方法,首先利用一个bilstm来提取上下文特征,然后在解码时每一步都预测一个动作,动作的候选集合为是否分词以及词性。
依存句法分析
在深度学习之前,依存句法分析主要是以基于转移的方法和基于图的方法。
基于转移的方法的一个经典的例子就是斯坦福陈丹琦的论文《A Fast and Accurate Dependency Parser using Neural Networks》,另一个是目前最好的CMU的《Transition-based Dependency Parsing with Stack Long Short-Term Memory》,通过三个LSTM来分别建模栈状态、待输入序列和动作序列。 其中因为栈需要入栈和出栈,因此作者提出了一个 Stack LSTM 来建模栈状态。
虽然基于 Stack LSTM 取得了非常好的效果,但是在目前的依存句法分析中,最流行的方法是基于图的方法经典的方法是 Biaffine 模型。直接用神经网络来预测每两个词之间存在依存关系的概率,这样我们就得到一个全连接图,图上每个边代表了节点 a 指向节点 b 的概率。然后使用MST等方法来来将图转换为一棵树。
Biaffine 模型其实和我们目前全连接自注意力模型非常类似。Biaffine模型十分简单,并且容易理解,并且在很多数据集上都取得了目前最好的结果。《Deep Biaffine Attention for Neural Dependency Parsing》
最后
词性标注和句法分析:An improved neural network model for joint POS tagging and dependency parsing. 2018
分词和句法分析:A Graph-based Model for Joint Chinese Word Segmentation and Dependency Parsing. 2019
本文主要内容来自于邱锡鹏2019年5月做的一篇报告