文件的定义
在没有操作系统的年代是没有文件这一定义的。文件实际上也是一个虚拟的东西,是建立在操作系统之上的一个概念。
通过文件能够让使用计算机的人更加方便的操纵硬盘上的数据,因为应用程序在运行时所有的数据全部存放于内存中,因内存具有断电数据丢失的特性故若想永久保留其中的一些数据则必须将该数据存放于硬盘上面。而人类对文件的操作实际上是在调用操作系统提供的一个接口对底层硬件发起系统调用(再次强调:只有操作系统才能直接调用硬件。应用程序或者说是用户都只能通过操作系统间接调用底层硬件)。因此可以理解为:文件是操作系统提供给人类操控硬盘的一个接口而已。
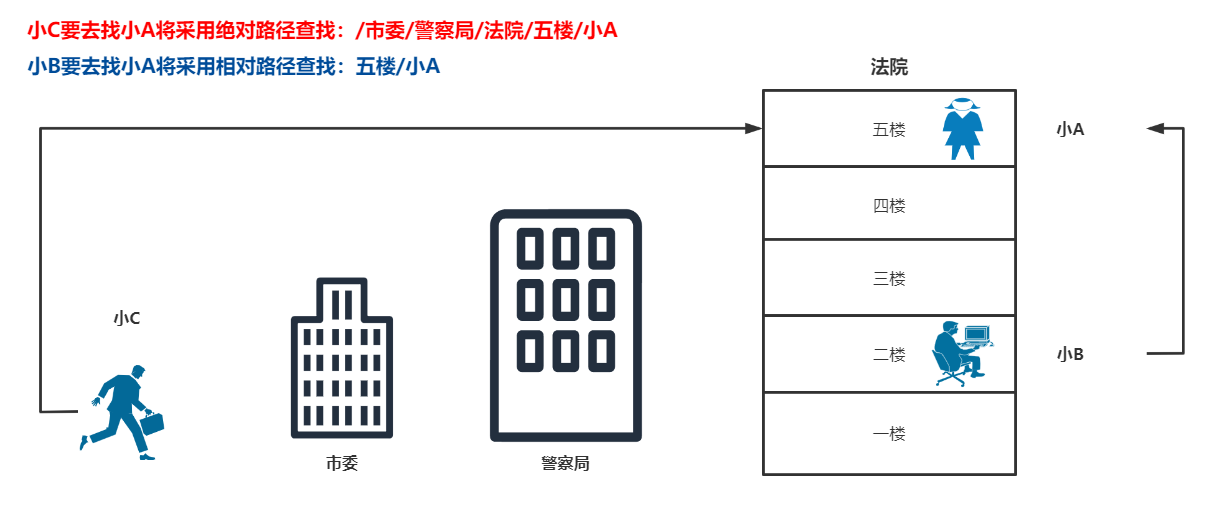
绝对路径与相对路径
这个比较简单,绝对路径是从根部查找,相对路径是从当前地查找。看下图即可明了:
open()方法
Python提供open()方法用于对文件的操作,并且返回一个文件对象。这里提一嘴:文件本身存取的内容全是字符串类型,所以用open()方法将其打开定然涉及到字符编码的问题。我们先看open()方法的使用,它的参数有以下几个:
====
open()方法常用参数详解 ====
file: 必需,文件路径(相对或者绝对路径)。
mode: 可选,文件内容读取与操作模式,*t模式以为文本内容读取模式打开文件。需要填入encoding,b模式为二进制模式读取文件内容,默认该参数为*t。*代表操作模式。
encoding: 可选(Python2没有该参数),当mode为*t时指定编码或解码格式。一般设置为utf-8。如不指定Windows平台默认为GBK,Mac和Linux平台为utf-8
====
open()方法其他参数详解 ====
buffering: 设置缓冲
errors: 报错级别
newline: 区分换行符(该点可做了解。一般默认为True)
closefd: 传入的file参数类型
一定要注意。在使用open()方法打开文件后,将文件赋值给一个变量待到文件操作完成后一定要将其进行关闭。至于具体原因下面会讲到。
Python2中open()方法
由于Python2中不能使用encoding参数指定编解码的方式。所以我们看看在Python2中open()应该怎样使用:
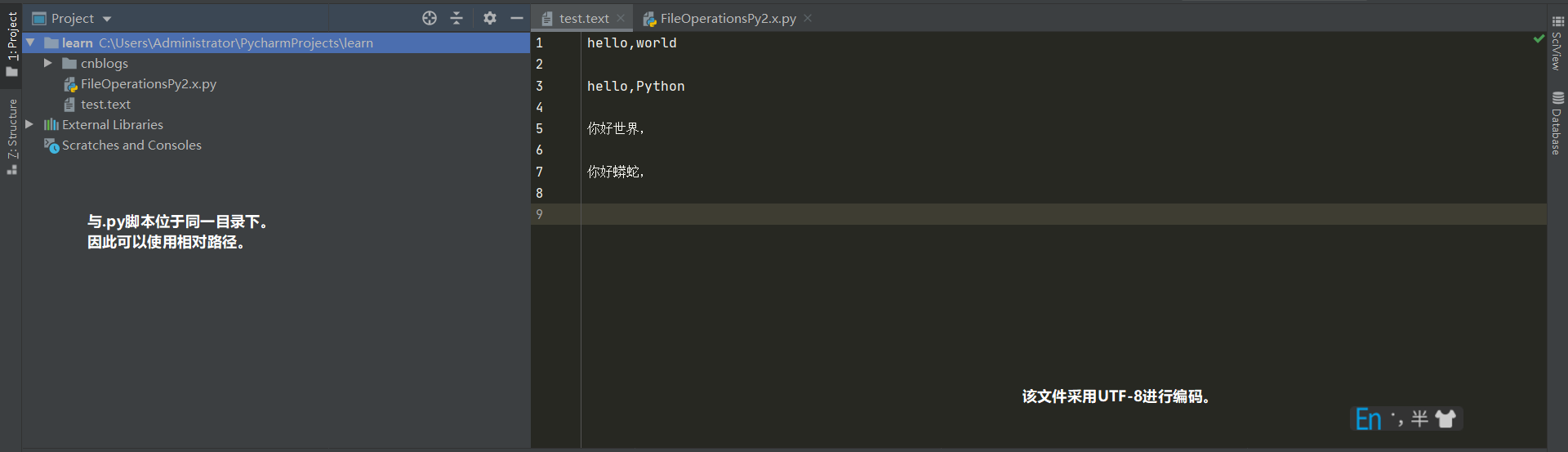
#!/usr/bin/env python2 #coding:utf-8 # import sys # reload(sys) # sys.setdefaultencoding('utf-8') # 设置默认的解码方式为 utf-8。如果这样操作就不用设置decode()了。 f = open(file="test.text",mode="rt",) data = unicode(f.read().decode("utf-8")) # unicode()将读取出的字符转为unicode字符存储于内存中。decode()设定解码方式。read()是读取全部文件内容 print data f.close() # 关闭文件。这一点非常重要!具体原因下面会讲到。 # ==== 执行结果 ==== Ps:可以看到换行符也算在里面的。这一点要注意 """ hello,world hello,Python 你好世界, 你好蟒蛇, """
Python3中open()方法
在Python3中如果不指定encoding参数则默认为GBK形式。一定要注意读取文件的存储格式,用什么格式存的就用什么格式来读。我们看一下具体的操作流程:
#!/usr/bin/env python3 # coding:utf-8 f = open(file="test.text", mode="rt", encoding="utf-8") data = f.read() # 由于Python3可以指定encoding参数并且字符串类型本身就是Unicode字符,所以直接用就好。 print (data) f.close() # ==== 执行结果 ==== Ps:可以看到换行符也算在里面的。这一点要注意 """ hello,world hello,Python 你好世界, 你好蟒蛇, """
with上下文管理器
上面讲到。open()过后关闭文件非常重要,但是有的朋友比较粗心大意。对此,Python提供with上下文管理器来防止读取文件后忘记关闭文件的情况发生。它的使用方法也非常简单,我们以Python3举例:
#!/usr/bin/env python3 # coding:utf-8 with open(file="test.text",mode="rt",encoding="utf-8") as f: # as f 实际上与 f = open() 相当。它被称为文件句柄 data = f.read() print (data) # 当操作完成后自动使用close()方法关闭打开的文件。至于为什么要关闭打开的文件具体原因下面会讲到。
with 上下文管理器还可以一次性打开多个文件。用逗号,来跟上下一个with ,用反斜杠 进行换行操作,如下:
#!/usr/bin/env python3 # coding:utf-8 with open(file="test.text",mode="rt",encoding="utf-8") as f1, open(file="test2.text",mode="rt",encoding="utf-8") as f2: data1 = f1.read() print (data1) print ("====手动分割====") data2 = f2.read() print (data2) # 当操作完成后自动使用close()方法关闭打开的文件。至于为什么要关闭打开的文件具体原因下面会讲到。 # ==== 执行结果 ==== Ps:可以看到换行符也算在里面的。这一点要注意 """ hello,world hello,Python 你好世界, 你好蟒蛇, ====手动分割==== """ 这里是test2的内容 """
控制文件读写内容的模式
t模式
好了,上面讲到了open()在Python2和Python3中不同的区别后,接下来就要讲mode参数。我们可以仔细的看到上面的代码示例中mode参数都是rt,其中的t就是代表以文本方式读取文件内容。只要以文本方式读取文件内容就必然涉及到文本中字符内容的编码解码操作,并且在Python中默认的读取文件内容的方式就是文本模式。
b模式
b模式代表二进制模式。二进制可以存储图片,音乐,视频等原生数据,当然也可以存文本数据。当使用b模式读取文件内容时不可以设置encoding参数,下面示例演示如果用b模式打开文本文件,将手动执行decode()的解码操作。
#!/usr/bin/env python3 # coding:utf-8 with open(file="test.text", mode="rb") as f: data = f.read().decode("utf-8") # 计算机本身就是二进制存储,要打开文本文件必然可行。前提是解码方式正确 print (data) # 当操作完成后自动使用close()方法关闭打开的文件。至于为什么要关闭打开的文件原因下面会讲到。 # ==== 执行结果 ==== Ps:可以看到换行符也算在里面的。这一点要注意 """ hello,world hello,Python 你好世界, 你好蟒蛇, """
控制文件读写操作的模式
r模式
还是mode参数。r代表read,只读的意思。当使用r模式打开文件时文件的指针将跑到最开始,并且如果文件不存在将会抛出异常。并且只能使用读取相关的方法,这里不做具体演示了。
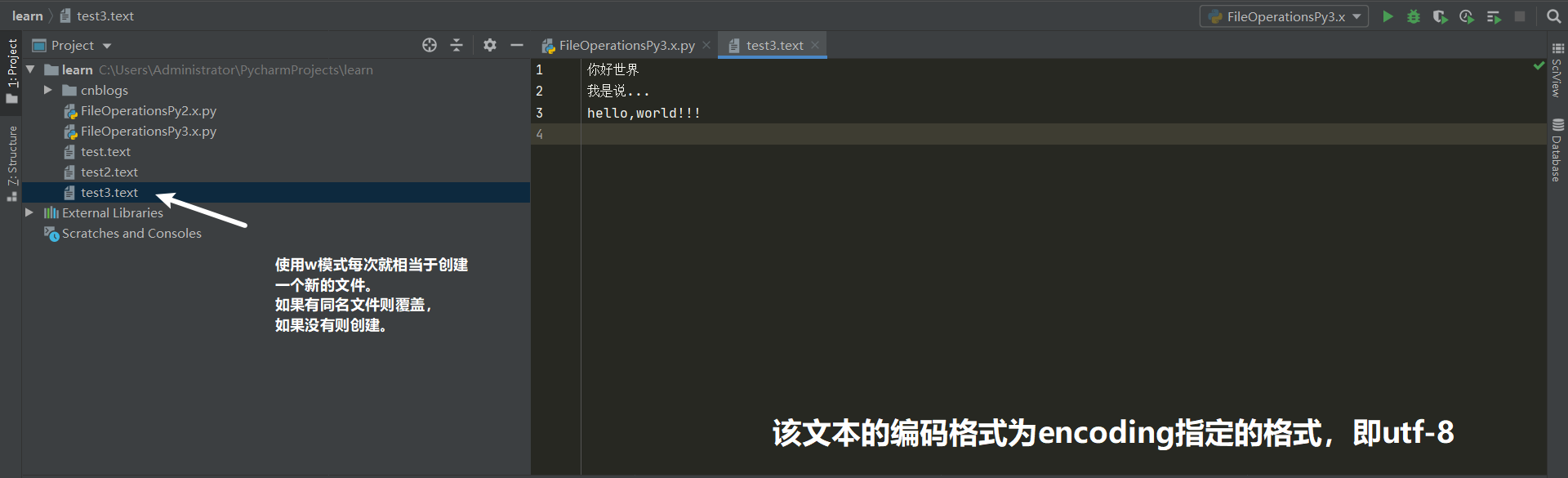
w模式
w模式代表write,只写的意思。当使用w模式打开文件时就相当于新建一个文件。如果文件已存在将清空原本文件中所有的内容,如果文件不存在则创建新文件,只能使用写入相关的方法。
#!/usr/bin/env python3 # coding:utf-8 with open(file="test3.text", mode="wt",encoding="utf-8") as f: # 该文件并不存在,当执行该脚本时将创建该文件。 data = "你好世界 我是说... hello,world!!! " f.write(data) # 写入unicode字符串至文件中。 # f.read() # 不能使用 read() 读相关的方法
a模式
a模式为追写模式,当文件不存在时创建新文件。只能执行写相关的操作,当文件存在时则打开文件,文件指针放到最后。所以被称为追写模式
强调
w模式与a模式的异同:1 相同点:在打开的文件不关闭的情况下,连续的写入,新写的内容总会跟在前写的内容之后
2 不同点:以
a模式重新打开文件,不会清空原文件内容,会将文件指针直接移动到文件末尾,新写的内容永远写在最后
#!/usr/bin/env python3 # coding:utf-8 # 以下代码执行了3次。第一次创建新文件写入一次内容,后两次文件指针在最后进行追写。所以你会看到... with open(file="test4.text", mode="at",encoding="utf-8") as f: # 该文件并不存在,当执行该脚本时将创建该文件。 data = "hello world!!! 我是说... 你好世界 " f.write(data) # 写入unicode字符串至文件中。写完后文件指针跑到末尾 # f.read() # 不能使用 read() 读相关的方法

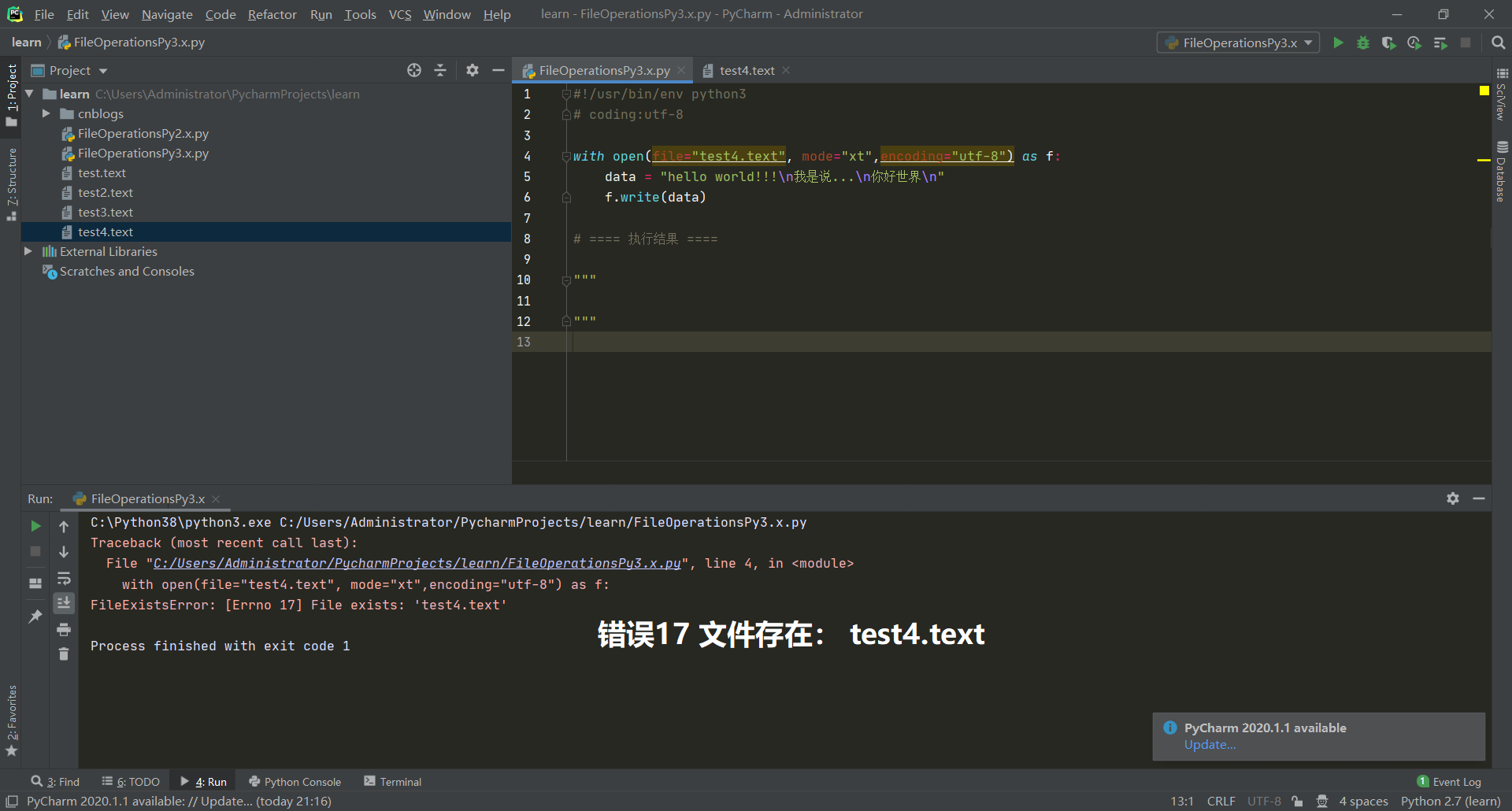
x模式
x模式与w模式都相同。唯一不同的地方在于如果需要打开的文件已存在,会抛出异常。而w模式会新建一个同名文件并且删除掉旧文件。
+方法
+这里是对 r w a 的一种扩展。代表可读可写,但是打开文件后文件指针的位置还是依照 r w a 原本的位置,应该尽量少用+方法。
#!/usr/bin/env python3 # coding:utf-8 with open(file="test4.text", mode="w+t",encoding="utf-8") as f: # 也可以写成 *t+ 。当然*+t更标准 data = "hello world!!! 我是说... 你好世界 " f.write(data) f.seek(0,0) # 由于写入过后文件指针跑到末尾,所以需要将文件指针放到开始才能读取出内容 print (f.read()) # 本来w模式不能读,但是使用了 + 方法后就就赋予w模式可读的权限。其他方法同理 # ==== 执行结果 ==== """ hello world!!! 我是说... 你好世界 """
需要注意,如果使用r+模式进行write()操作,那么会覆盖掉原本的值。具体看如下代码:
#!/usr/bin/env python3 # coding:utf-8 with open(file="test4.text", mode="r+t", encoding="utf-8") as f: data = "覆盖覆盖.." f.write(data) f.seek(0, 0) # 由于写入过后文件指针会移动,所以需要将文件指针放到开始才能读取出内容 print (f.read()) # 本来r模式不能写,但是使用了 + 方法后就就赋予r模式可写的权限。其他方法同理 # ==== 执行结果 ==== """ 覆盖覆盖.. 我是说... 你好世界 """
如果使用a+模式进行读取操作。则需要使用seek()方法操作文件指针到开头,否则将读取不出内容。因为a模式本身会将文件指针放到最后去。
#!/usr/bin/env python3 # coding:utf-8 with open(file="test4.text", mode="a+t", encoding="utf-8") as f: f.seek(0, 0) # 移动文件指针到开头,如不移动将读取不出内容 print (f.read()) # ==== 执行结果 ==== """ 覆盖覆盖.. 我是说... 你好世界 """
文件指针
seek()方法与3种模式
文件指针的移动一通常情况下不会用到。但是请注意:尽量在b模式下使用,t模式下一般只是使用(0,0),使用其他模式会抛出异常。代表将文件指针放在开头,具体原因在第三小节中讲。我们来看一下seek()的两个参数。
==== seek()方法的2个参数 ====
第一个参数为文件的指针移动位置,正数为向后移动负数为向前移动。
第二个参数为文件的指针依据文件的什么位置移动,
0代表开始位置,1代表当前位置,2代表结束位置。
注意:如果第二个参数为
0或者2,多次进行移动操作则以最后的操作为准(因为每次都是按照绝对位置移动)
seek(2,0)
seek(10,0)
seek(20,0)<-- 最终会移动到该位置而不是累加
如果第二个参数为
1,代表文件指针依据当前位置移动。相对移动是会进行累加的。这点要了解如果第二个参数为2,文件指针的移动应该使用负数向前移动。而不是使用正数向后移动
#!/usr/bin/env python3 # coding:utf-8 with open(file="test4.text", mode="rb") as f: #注意,文件指针除了(0,0)和(0,2)外,其他都应该用b模式进行。 print (f.tell()) # 打印当前文件指针的位置 0 f.seek(2,0) f.seek(10,0) f.seek(20,0) print (f.tell()) # 打印当前文件指针的位置 20 f.seek(-2,1) f.seek(-3,1) f.seek(-4,1) print (f.tell()) # 由于是相对定位,故可以累加。 20 - 9 ,文件指针在 11 # ==== 执行结果 ==== """ 0 20 11 """
文件指针移动单位
为什么说使用seek()方法的时候更推荐在b模式下进行呢?原因是这涉及到一个文件指针移动单位的问题。
只有在f.read(int)并且为t模式下的时候,文件指针的移动单位是字符,其他都是以字节为单位。
我们来看个实例:
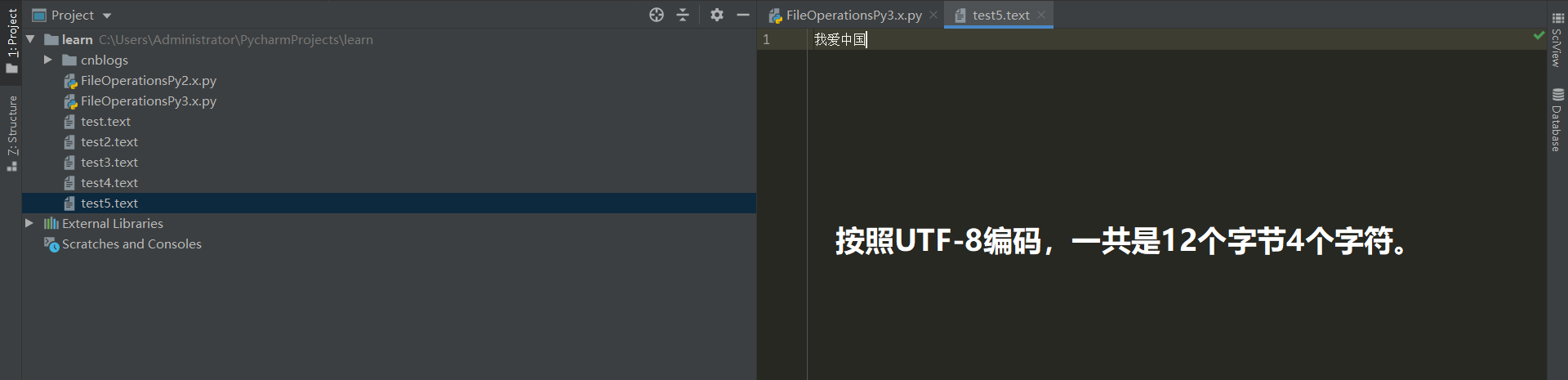
#!/usr/bin/env python3 # coding:utf-8 with open(file="test5.text", mode="rt", encoding="utf-8") as f: # r模式的指针默认放在0位置 f.seek(3, 0) # 只有在0模式下,t模式读取文件内容才不会抛出异常。根据0模式向后移动3个字节 print (f.read()) # ==== 执行结果 ==== Ps:如果seek()的第一个参数设置为4呢?岂不是抛出异常了? """ 爱中国 """ #!/usr/bin/env python3 # coding:utf-8 with open(file="test5.text", mode="rt", encoding="utf-8") as f: # r模式的指针默认放在0位置 f.seek(4, 0) # 修改为4,代表根据文件开头向后移动4个字节后执行decode()解码操作。 print (f.read()) # ==== 执行结果 ==== """ raceback (most recent call last): File "C:/Users/Administrator/PycharmProjects/learn/FileOperationsPy3.x.py", line 6, in <module> print (f.read()) File "C:Python38libcodecs.py", line 322, in decode (result, consumed) = self._buffer_decode(data, self.errors, final) UnicodeDecodeError: 'utf-8' codec can't decode byte 0x88 in position 0: invalid start byte """
读取文件的两种方法
for循环读取
注意:如果直接使用f.read()。当文件内容过于庞大时,这些内容全部会存放于Python程序的内存空间中。会给内存带来极大的压力,故在文件较小时才使用f.read(),太大的话将使用其他解决方案。做一个示例:
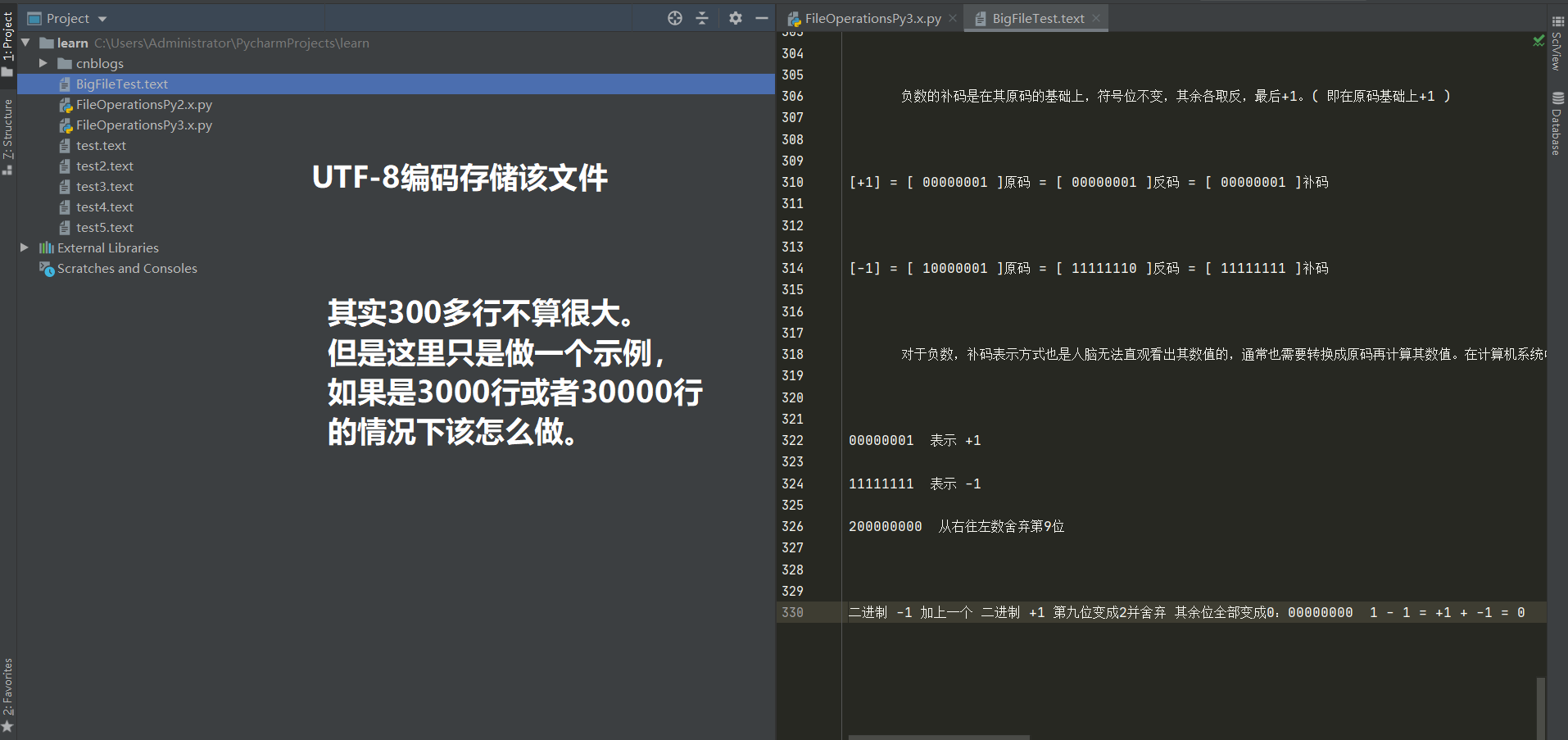
#!/usr/bin/env python3 # coding:utf-8 with open(file="BigFileTest.text", mode="rt", encoding="utf-8") as f: # r模式的指针默认放在0位置 for line in f: # 每次读一行。以换行符为结束 print (line) # 也就是说每次的在内存中的数据仅仅只有一行。
while循环读取
如果文件的所有数据都是在一行(Ps:有这种情况),那么使用for循环来读取文件就显得不适用了。这个时候我们要使用while循环来读取文件,因为我们知道f.read(int)的读取单位是字符(在t模式下,b模式下仍然是字节),所以我们可以自己制定每次读取的字符数量。
#!/usr/bin/env python3 # coding:utf-8 res = "" # 接收到的整体结果 with open(file="BigFileTest.text", mode="rt", encoding="utf-8") as f: # r模式的指针默认放在0位置 while 1: temp = f.read(512) # 代表每次读取512个字符。 res += temp if not len(temp): # 代表没有新的内容。 len(data) == 0 break print("读取完毕..") print(res)
写入文件的两种方法
文本编辑器内部实现原理
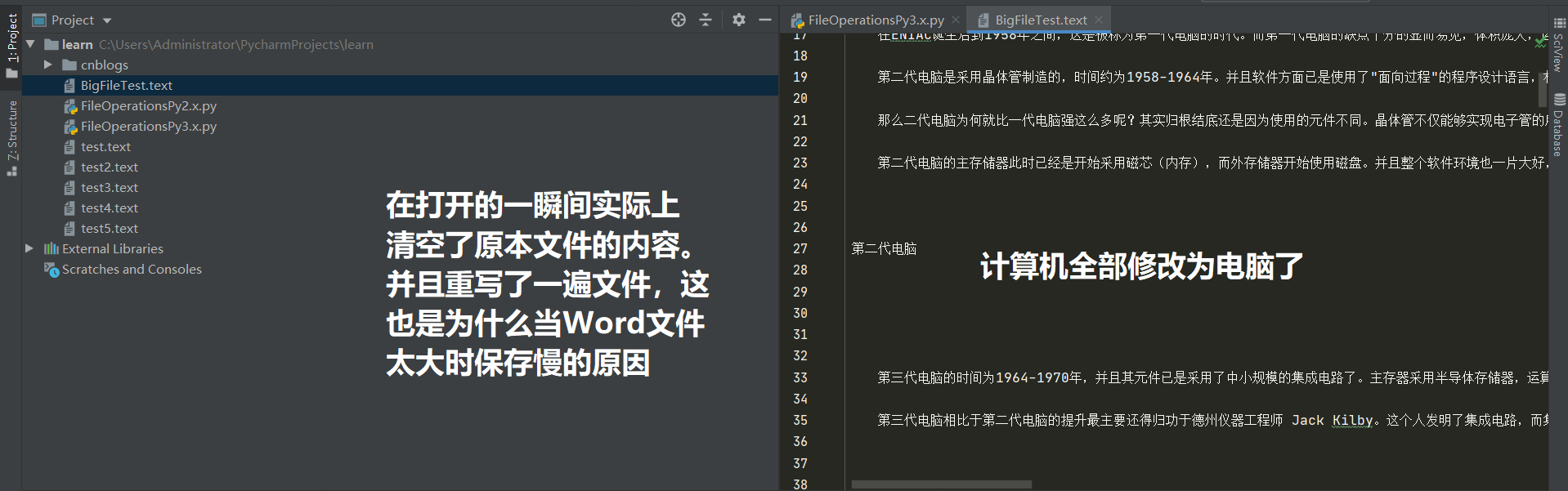
读取文件的两种形式我们已经介绍了,那么接下来介绍写入文件的两种形式。首先是文本编辑器的内部实现原理,在打开一个文本文件时其中所有的内容都会存放于内存中。对该文本内容的修改实际上全部都是在修改内存中的数据,当修改完成后点击保存时才会将内存的数据重新写入至硬盘中。你应该深有体会,打开一个特别大的文本文件时速度很慢,哪怕没做任何修改保存时速度也还是很慢。那么就是这个原因导致的。
#!/usr/bin/env python3 # coding:utf-8 data = "" # 用于存放数据 with open(file="BigFileTest.text", mode="rt", encoding="utf-8") as f: # r模式的指针默认放在0位置 while 1: temp = f.read(512) data += temp # 代表每次读取512个字符。 print (data) # 这里可以做其他操作 if not len(temp): # 代表没有新的内容。 len(temp) == 0 break print ("读取完毕..") data = data.replace("计算机", "电脑") # 模拟手动修改文件内容。将计算机修改为电脑,注意此时修改的是内存中的数据 with open(file="BigFileTest.text", mode="wt", encoding="utf-8") as f: # 读取后将Python应用程序中维护的data变量中的数据全部写入该文件。w模式会清空源文件的内容 f.write(data) print ("写入完毕..")
减少内存压力的同时写入文件
文本编辑器的做法是在内部维护了一个变量,用于提供给用户修改内容。这么做的好处就是用户可以修改文件内容与查看到所有的全部文件内容但是坏处是占用内存空间太大。这里再介绍一种减少内存压力的方式。
注意:两种方式没有优劣之分,只有使用场景不同的区别。
#!/usr/bin/env python3 # coding:utf-8 with open(file="BigFileTest.text", mode="rt", encoding="utf-8") as f1, open(file=".BigFileTest.text.swap", mode="wt", encoding="utf-8") as f2: # 以. 开头的文件代表隐藏文件。以swap结尾的文件代表交换文件(可以理解为临时文件) for line in f1: line = line.replace("计算机","电脑") # 每次拿到和修改的只有line f2.write(line) # 写入交换文件中 print ("操作完成..") import os os.remove("BigFileTest.text") # 删除源文件 os.rename(".BigFileTest.text.swap","BigFileTest.text") # 修改临时文件的名字。与源文件保持一致 """ 这么做的坏处是没办法随时的修改内存中的变量数据,因为内存中根本没存文本文件内容... 只能按照 设定好的程序走一遍..但是极大的节省了内存空间的占用。 """
文件操作方法大全
====文件操作方法大全====
read()读取某个文件(全部内容)。也可指定大小(字符为单位)
readline()读取一行文件内容
readlines()读取所有文件内容并返回一个列表,以行割开
write()写入一行数据,默认不会 需要手动换行
writelines()写入一行数据,通过列表的方式写到文件里面。
tell()显示当前文件光标的位置
seek()移动当前文件光标的位置(字节为单位,一般建议在b模式下使用)
readable()文件是否可读
writable()文件是否可读
closed文件是否关闭
encoding如果文件打开模式为b,则没有该属性
flush()立刻将文件内容从内存刷到硬盘(测试模式下使用)
扩展:为什么要关闭文件
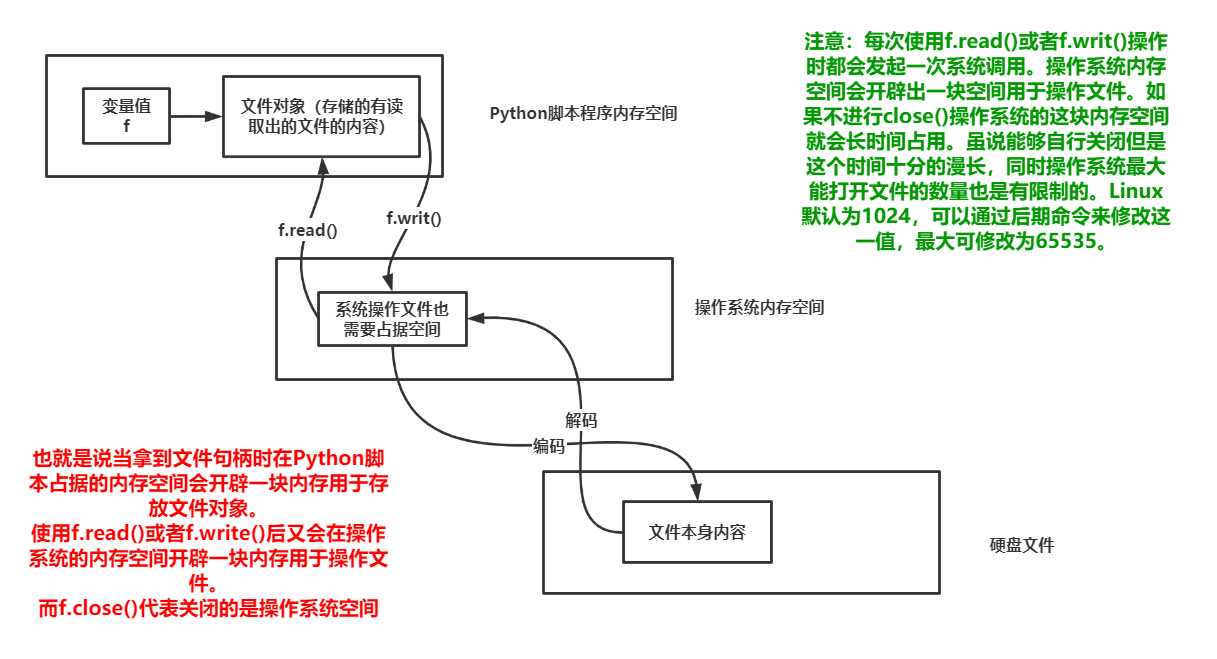
换行符在不同的平台下会有不同的差异。如Windows平台下其实实际使用的是
,而Linux以及Mac平台下都是使用的
。这是为何呢?还是使用图解: