JAVA中的迭代器大多作为私有的内部类实现,不妨我们先以ArrayList为例
先看一下继承树
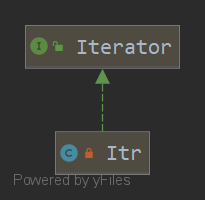
1.Iterator和Iterable
首先,我们需要先看一下,Iterator接口中,声明了那些方法
注意默认方法有方法体,只不过为了简洁,这里没有贴上代码,而是用分号代替了,请不要过于关注于此
//判断当前迭代器是否指向了最后一个元素
boolean hasNext();
//放回迭代器指向的元素,并将迭代器指向下一个元素
E next();
//移除迭代器刚刚遍历到的元素
default void remove();
//遍历还没有遍历过的元素
default void forEachRemaining(Consumer<? super E> action);
迭代器使用的泛型一般就是外部类
既然说到了Iterator接口,那我们就得看一下Iterable接口了
这两个接口不仅名字相似,实际上也确实息息相关
比如Iterable的第一个方法
//返回一个迭代器(Iterator的实例)
Iterator<T> iterator();
接下来的这个方法用于遍历集合中的元素
default void forEach(Consumer<? super T> action)
//稍后再谈
default Spliterator<T> spliterator();
2.ArrayList中的Itr
private class Itr implements Iterator<E>
由于ArrayList的底层是一个数组,所以迭代器实现很简单,用一个int型数据(cursor)记录一下当前指向(下一个next要返回的)第几个元素就行了
于此同时,还需要一个变量lastRet记录上一个返回的哪个元素,一般情况下,lastRet = cursor - 1,但是,当出现删除时,lastRet记为-1,直到下次执行next()或者forEachRemaining().
lastRet用于避免重复删除,不可以连续调用remove()两次
注意遍历过程中还要不停检查modCount,值得一提的是,Itr自身的remove()并不会引起与modCount相关的异常,因为在执行remove()时,expectedModCount也做了改变
list的加强for循环就是用Iterator实现的哦
3.ListIterator接口
先看一下ArrayList中,ListIterator的实现类的继承树
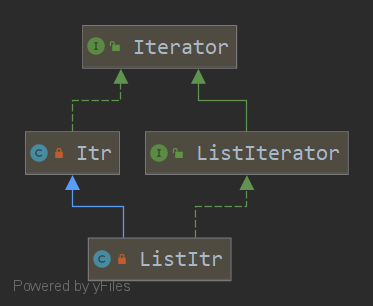
它的方法如下
和Iterator相同的
boolean hasNext();
E next();
void remove();
少了一个forEachRemaining方法
和以上Iterator相反的是
boolean hasPrevious();
E previous();
由于Iterator只可以向后挪动,所以实际上,ArrayList的相关方法中,没有任何一个方法可以使得cursor变小
ListIterator声明了这两个方法,表明ListIterator在Iterator的基础上,反向遍历
但是没有方法提供了设置遍历的开始是在结尾还是开头
此外还声明了以下方法
//返回如果调用next,应该返回那个下标对应的值
int nextIndex();
//返回如果调用previous,应该返回那个下标对应的值
int previousIndex();
//将当前迭代器的元素更换为e
void set(E e);
//在当前位置新增一个元素
void add(E e);
4.ArrayList中的ListItr
首先要提的就是
ArrayList.listIterator()方法,用于返回一个ListItr,但是这个方法并没有定义在Iterable接口中
同时ArrayList.listIterator(int index)方法,可以指定ListItr的起始位置
在实现listIterator时,相关变量的定义还是没变,cursor记录下一次执行next()要返回的元素下标
其set()和add()方法,其实就是内部加了一些检测,然后调用了ArrayList的set()和add()方法
这两个方法有值得注意的地方
当cursor等于3时,add()执行,其后cursor指向的是3还是4呢
看一下源码
int i = cursor;
//在i位置插入一个元素,i和i之后的元素都往后挪一位
ArrayList.this.add(i, e);
//指向原来指向的元素
cursor = i + 1;
//禁止remove的执行
lastRet = -1;
expectedModCount = modCount;
可以看出,就元素而言,add()方法并不会改变cursor指向的元素,如果想遍历到刚刚插入的元素,就只能使用E previous()方法了
而对于set()方法
public void set(E e) {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
ArrayList.this.set(lastRet, e);
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
可以看到,set()方法基于lastRet,也就是说,和remove一样,lastRet 为-1时是不可用的
那么我们先来总结一下,什么时候lastRet为-1呢
**
1.迭代器刚刚构造出
2.执行完remove()
3.执行完add()
**
可以注意到set()并没有更新expectedModCount ,但是实际上,ArrayList.set(int index,E e)本身就没有更新modMount。
5.Spliterator接口
老规矩,看一下ArrayList实现类的继承树
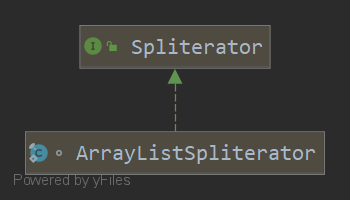
相信你一定还记得,Iterable的default Spliterator<T> spliterator()方法,可见实际上这也是一个很重要的接口
这个接口大致就是把一个ArrayList分为几段,以加速并行处理。
6.ArrayList的spliterator
由于之前的描述比较抽象,我们先来看一段测试代码
public void test12(){
Stream<Integer>stream = Stream.iterate(1,t->t+1);
ArrayList<Integer>list=new ArrayList<>();
stream.limit(10).forEach(list::add);
Spliterator<Integer> iterator = list.spliterator();
Spliterator<Integer> spliterator = iterator.trySplit();
//第一段输出
iterator.forEachRemaining(System.out::println);
System.out.println();
//第二段输出
spliterator.forEachRemaining(System.out::println);
}
输出的结果是:
第一段输出:6,7,8,9,10
第二段输出:1,2,3,4,5
可以看出这个迭代器实际上就是把一个ArrayList分为多个字串,每个分出来的迭代器分别遍历个子的字串
我们按顺序看起,重点关注一下它的trySpilt方法
构造器:
ArrayListSpliterator(ArrayList<E> list, int origin, int fence,
int expectedModCount) {
this.list = list; // OK if null unless traversed
this.index = origin;
this.fence = fence;
this.expectedModCount = expectedModCount;
}
通过ArrayList.spliterator()构造时,默认的传入值是(this,0,-1,0)
这些值我们暂时不知道什么意思,那让我们先看trySpilt方法吧
public ArrayListSpliterator<E> trySplit() {
int hi = getFence(), lo = index, mid = (lo + hi) >>> 1;
return (lo >= mid) ? null : // divide range in half unless too small
new ArrayListSpliterator<E>(list, lo, index = mid,
expectedModCount);
}
通过这个方法我们可以看出,实际上每次trySplit都是对半分的
而且index就是最低位,fence就是最高位,那为什么fence一开始会是-1呢?
让我们看看getFence方法
private int getFence() { // initialize fence to size on first use
int hi; // (a specialized variant appears in method forEach)
ArrayList<E> lst;
//如果fence小于0
if ((hi = fence) < 0) {
if ((lst = list) == null)
hi = fence = 0;
else {
//fence为-1就会进入这里,变成该list的size最大值
expectedModCount = lst.modCount;
hi = fence = lst.size;
}
}
return hi;
}
看到这里我们还有一个疑问,为啥modcount一开始为0?
那我们需要看一下forEachRemaining才能解答这个问题
另外一个值得注意的点就是这个迭代器没有hasNext和next方法
public void forEachRemaining(Consumer<? super E> action) {
int i, hi, mc; // hoist accesses and checks from loop
ArrayList<E> lst; Object[] a;
if (action == null)
throw new NullPointerException();
if ((lst = list) != null && (a = lst.elementData) != null) {
if ((hi = fence) < 0) {
//这里已经将modCount置位正常值了
//但是为什么要延迟到这里呢
mc = lst.modCount;
hi = lst.size;
}
else
mc = expectedModCount;
if ((i = index) >= 0 && (index = hi) <= a.length) {
for (; i < hi; ++i) {
@SuppressWarnings("unchecked") E e = (E) a[i];
action.accept(e);
}
if (lst.modCount == mc)
return;
}
}
throw new ConcurrentModificationException();
}
为什么不直接置为modCount呢,偏偏要先搞成一个0呢
我想,原因应该是,创建好SplitIterator后,如果没有遍历,而是首先加了几个元素,在这种写法下,代码仍然可以正常运行
更优秀的是,当一次遍历结束之后,如果又添加了新的值,那么他会从新添加值开始遍历起.
当然,这其中不能有remove操作,因为index这个属性察觉不到,而且,一旦执行trySplit方法,也就不能再有增删操作了
7.HashIterator
HashIterator是定义在HashMap中的一个抽象迭代器
实际上,HashMap并不能直接使用迭代器,而是需要拿到KeySet或者ValueSet这样的Set才可以使用迭代器
Iterator it = map.keySet().iterator();
但是实际上,HashIterator还是通过遍历HashMap的散列数组来查找的
看几段源码就明白了:
final Node<K,V> nextNode() {
Node<K,V>[] t;
Node<K,V> e = next;
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (e == null)
throw new NoSuchElementException();
//这里写得比较绕
//其实就是按链表查找,如果链表找到了尾部,那就寻找下一个有元素的散列地址
if ((next = (current = e).next) == null && (t = table) != null) {
do {} while (index < t.length && (next = t[index++]) == null);
}
return e;
}
可以看到这里并没有特殊处理树节点,因为树节点是普通节点的子类,而树节点在插入的过程中,也一直维护了next指针.
看一下HashMap中,putTreeVal()方法的插入代码
TreeNode<K,V> xp = p;
//找到了某个叶子节点
if ((p = (dir <= 0) ? p.left : p.right) == null) {
//保存下一个节点
Node<K,V> xpn = xp.next;
//新节点的下一个节点就是xpn
TreeNode<K,V> x = map.newTreeNode(h, k, v, xpn);
if (dir <= 0)
xp.left = x;
else
xp.right = x;
//赋值新的下一个节点
xp.next = x;
x.parent = x.prev = xp;
//维护的双向链表哦
if (xpn != null)
((TreeNode<K,V>)xpn).prev = x;
moveRootToFront(tab, balanceInsertion(root, x));
return null;
}
我们可以看到,即使树节点,也可以按照普通节点的方法遍历
不过,请注意,HashMap,普通节点只有next,没有prev
这意味着,只有树节点才能构建出双向链表
除nextNode之外,还有一个remove方法
实际上就是调用了HashMap的removeNode方法,并修改了expectedModCount值,不做多余赘述了
HashIterator中包括构造器,一共只有四个方法,并且都不是抽象方法,HashIterator定义为抽象类,只是单纯不希望被创建实例对象
8.HashMap中的HashIterator子类
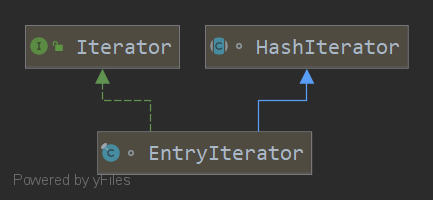
一共三个子类,继承Iterator方便外部调用
final class KeyIterator extends HashMap.HashIterator
implements Iterator<K> {
public final K next() { return nextNode().key; }
}
final class ValueIterator extends HashMap.HashIterator
implements Iterator<V> {
public final V next() { return nextNode().value; }
}
final class EntryIterator extends HashMap.HashIterator
implements Iterator<Map.Entry<K,V>> {
public final Map.Entry<K,V> next() { return nextNode(); }
}