一.Java虚拟机JVM规格描述
JVM的设计目标是提供一个基于抽象规格描述的计算机模型,为解释程序开发人员提范的任何系统上运行。
JVM对其实现的某些方面给出了具体的定义,特别是 对Java可执行代码,即字节码(Bytecode)的格式给出了明确的规格。
这一规格包括操作码和操作数的语法和数值、标识符的数值表示方式、以及 Java类文件 中的Java对象、常量缓冲池在JVM的存储映象。
这些定义为JVM解释器开发人员提供了所需的信息和开发环境。Java的设计者希望给开发人员以随心所欲使用Java的自由。
JVM定义了控制Java代码解释执行和具体实现的五种规格,
它们是:
1、JVM指令系统
JVM指令系统同其他计算机的指令系统极其相似。Java指令也是由 操作码和操作数两部分组成。
操作码为8位二进制数,操作数进紧随在操作码的后面,其长度根据需要而不同。操作码用于指定一条指令操作的性质(在这里我们采 用汇编符号的形式进行说明),
如iload表示从存储器中装入一个整数,anewarray表示为一个新数组分配空间,iand表示两个整数的" 与",ret用于流程控制,表示从对某一方法的调用中返回。
当长度大于8位时,操作数被分为两个以上字节存放。JVM采用了"big endian"的编码方式来处理这种情况,即高位bits存放在低字节中。
这同 Motorola及其他的RISC CPU采用的编码方式是一致的,而与Intel采用的"little endian "的编码方式即低位bits存放在低位字节的方法不同。
Java指令系统是以Java语言的实现为目的设计的,其中包含了用于调用方法和监视多先程系统的指令。Java的8位操作码的长度使得JVM最多有256种指令,目前已使用了160多种操作码。
2、JVM指令系统
所有的CPU均包含用于保存系统状态和处理器所需信息的寄存器组。如果虚拟机定义较多的寄存器,便可以从中得到更多的信息而不必对栈或内存进行访问,这有 利于提高运行速度。
然而,如果虚拟机中的寄存器比实际CPU的寄存器多,在实现虚拟机时就会占用处理器大量的时间来用常规存储器模拟寄存器,这反而会降低 虚拟机的效率。
针对这种情况,JVM只设置了4个最为常用的寄存器。它们是:
(1)pc程序计数器;
(2)optop操作数栈顶指针;
(3)frame当前执行环境指针;
(4)vars指向当前执行环境中第一个局部变量的指针;
(5)所有寄存器均为32位。pc用于记录程序的执行。optop,frame和vars用于记录指向Java栈区的指针。
3、JVM栈结构
作为基于栈结构的计算机,Java栈是JVM存储信息的主要方法。
当JVM得到一个Java字节码应用程序后,便为该代码中一个类的每一个方法创建一个栈框架 ,以保存该方法的状态信息。
每个栈框架包括以下三类信息:
(1)局部变量;
(2)执行环境;
(3)操作数栈;
局部变量用于存储一个类的方法中所用到的局部变量。vars寄存器指向该变量表中的第一个局部变量。
执行环境用于保存解释器对Java字节码进行解释过程中所需的信息。它们是:上次调用的方法、局部变量指针和操作数栈的栈顶和栈底指针。
执行环境是一个执 行一个方法的控制中心。例如:如果解释器要执行iadd(整数加法),首先要从frame寄存器中找到当前执行环境,
而后便从执行环境中找到操作数栈,从 栈顶弹出两个整数进行加法运算,最后将结果压入栈顶。
操作数栈用于存储运算所需操作数及运算的结果。
4、JVM碎片回收堆
Java类的实例所需的存储空间是在堆上分配的。解释器具体承担为类实例分配空间的工作。
解释器在为一个实例分配完存储空间后,便开始记录对该实例所占用的内存区域的使用。一旦对象使用完毕,便将其回收到堆中。
在Java语言中,除了new语句外没有其他方法为一对象申请和释放内存。对内存进行释放和回收的工作是由Java运行系统承担的。
这允许Java运行系 统的设计者自己决定碎片回收的方法。在SUN公司开发的Java解释器和Hot Java环境中,碎片回收用后台线程 的方式来执行。
这不但为运行系统提供了良好的性能,而且使程序设计 人员摆脱了自己控制内存使用的风险。
5、JVM存储区
JVM有两类存储区:常量缓冲池和方法区。常量缓冲池用于存储类名称、方法和字段名称以及串常量。
方法区则用于存储Java方法的字节码。对于这两种存储 区域具体实现方式在JVM规格中没有明确规定。
这使得Java应用程序的存储布局必须在运行过程中确定,依赖于具体平台的实现方式。
JVM是为Java字节码定义的一种独立于具体平台的规格描述,是Java平台独立性的基础。
目前的JVM还存在一些限制和不足,有待于进一步的完善,但无论如何,JVM的思想是成功的。
对比分析:如果把Java原程序想象成我们的C++原程序,Java原程序编译后生成的字节码就相当于C++原程序编译后的80x86的机器码(二进制程 序文件),
JVM虚拟机相当于80x86计算机系统,Java解释器相当于80x86CPU。在80x86CPU上运行的是机器码,在Java解释器上运 行的是Java字节码。
Java解释器相当于运行Java字节码的“CPU”,但该“CPU”不是通过硬件实现的,而是用软件实现的。Java解释器实际上就是特定的平台下的一 个应用程序。
只要实现了特定平台下的解释器程序,Java字节码就能通过解释器程序在该平台下运行,这是Java跨平台的根本。
当前,并不是在所有的平台 下都有相应Java解释器程序,这也是Java并不能在所有的平台下都能运行的原因,它只能在已实现了Java解释器程序的平台下运行。
二.Java虚拟机的体系结构
虚拟机由类加载器、运行数据区、执行引擎、本地方法接口、本地方法库组成。
虚拟机体系结构如下图所示:

当虚拟机运行一个程序时,它会使用类加载器加载Java程序的类文件,并且在计算机内申请一块内存区域,作为运行数据区。
用来存储程序的类文件、创建的静态对象和实例对象、方法、局部变量、中间结果、方法的返回值等内容。
为了管理和有效地利用已申请的内存区域,虚拟机把内存划分为堆、栈、方法区、程序计数器、本地方法栈。
运行数据区的方法区存储了包含程序使用import语句导入的JDK类库在内的类信息、各种常量、静态变量、代码编译后的字节码等内容;
本地方法栈用来存储调用非java代码编写的方法(Native Method)使用到的数据,这些方法包括用其它语言编写的第三方库和操作系统自身提供的API;
堆用来存储程序中动态创建的类实例对象;栈用来存储程序调用方法过程中,使用到的参数、局部变量、中间结果、返回值等内容;
程序计数器用来存储当前程序执行的指令(指令可以理解为类中的可执行代码)。
执行引擎负责执行方法区中的字节码,在执行字节码的过程中会在堆中创建实例对象,在栈中存取当前方法调用的参数、局部变量、中间结果、返回值等,
也会通过本地方法接口调用第三方库方法和操作系统自身提供的API。
当启动一个Java程序时,就会运行一个Java虚拟机,每个Java程序都会对应一个Java虚拟机,运行中的Java虚拟机,也可以称为Java虚拟机的一个实例。
Java程序运行结束关闭后,运行这个程序的Java虚拟机也会关闭。
例如,如果在电脑运行了三个Java程序,就会有三个Java虚拟机在运行。
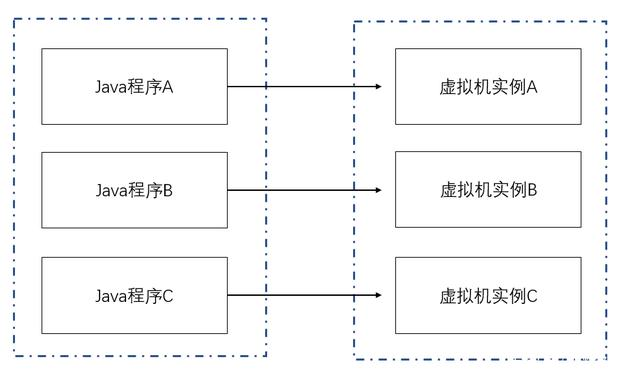
每个Java程序的主类都会有一个main()方法,虚拟机启动Java程序时,它会调用主类的main()方法作为Java程序的入口,
这个main()方法的访问权限必须是public,并且是无返回值的静态方法,方法的参数是一个String类型的数组。
下面是HelloWorld程序代码:

HelloWorld程序只有一个HelloWorld类,HelloWorld类内部必须有一个main()方法,当HelloWorld程序运行时,虚拟机会调用HelloWorld类的main()方法作为HelloWorld程序的入口。
在Windows命令行窗口运行HelloWorld程序的命令如下:
java HelloWorld
其中“java”就是虚拟机程序名称,Windows会启动一个虚拟机实例,“java”后面的“HelloWorld”是包含main()方法已编译的class文件名称,
虚拟机启动后,会加载HelloWorld.class文件到内存,并调用HelloWorld.class文件内的main()方法,HelloWorld程序进入运行状态,
main()方法内部的语句会得到执行,当main()方法内部的所有语句都执行完成后,main方法返回,HelloWorld程序结束,运行这个HelloWorld程序的虚拟机实例也会退出。
注意:
jdk,jre,JVM的关系:
JDK(Java Development Kit) 是 Java 语言的软件开发工具包(SDK)。
在JDK的安装目录下有一个jre目录,里面有两个文件夹bin和lib,在这里可以认为bin里的就是jvm,lib中则是jvm工作所需要的类库,而jvm和 lib合起来就称为jre。
三.为什么要使用Java虚拟机
Java语言的一个非常重要的特点就是与平台的无关性。而使用Java虚拟机是实现这一特点的关键。
一般的高级语言如果要在不同的平台上运行,至少需要编 译成不同的目标代码。而引入Java语言虚拟机后,Java语言在不同平台上运行时不需要重新编译。
Java语言使用模式 Java虚拟机屏蔽了与具体平台相关的信息,使得Java语言编译程序 只需生成在Java虚拟机上运行的目标代码(字节码),就可以在多种平台上不加修改地运行。
Java虚拟机在执行字节码时,把字节码解释成具体平台上的机器指令执行。
四.谁需要了解Java虚拟机
Java虚拟机是Java语言底层实现的基础,对Java语言感兴趣的人都应对Java虚拟机有个大概的了解。这有助于理解Java语言的一些性质,也有 助于使用Java语言。
对于要在特定平台上实现Java虚拟机的软件人员,Java语言的编译器作者以及要用硬件芯片实现Java虚拟机的人来说,则必须 深刻理解Java虚拟机的规范。
另外,如果你想扩展Java语言,或是把其它语言编译成Java语言的字节码,你也需要深入地了解Java虚拟机。
五.JVM概念
1、JIT编译器
虽然没有规定,但所有流行的JVM实现都并非只有简单的解释器:除解释器外,它们还自带了复杂的JIT编译器。
启动Java应用程序时,将首先启动并初始化JVM。JVM启动并初始化后,它将立即开始解释并运行Java字节码。
在合适的情况下,解释器将对程序的某些部分进行编译,再将原生可执行代码加载到内存中,并开始执行这些代码而不是经过解释后的Java字节码。
这样生成的代码的执行速度通常要快得多。对代码进行编译还是解释取决于很多因素。对于经常被调用的例程,JIT编译器很可能对其进行编译以生成原生代码。
JIT方法的优点在于,分发的文件可以是跨平台的,且用户无需等待整个应用程序编译完毕。JVM初始化后,应用程序将立即开始执行,而优化是在幕后完成的。
2、基本数据类型
JVM提供了几个内置的基本数据类型,这是Java未被视为纯粹的OOP语言的主要原因。这些类型的变量不是对象,且始终都包含值。
Java名称 描述和长度 取值范围(含)
byte 有符号字节(8位) 128~127
short 有符号短整型(16位) 32768~32767
int 有符号整型(32位) 231~2311
long 有符号长整型(64位) 263 ~2631
float 单精度浮点数(32位) 不精确的浮点值
double 双精度浮点数(64位) 不精确的浮点值
char 单个Unicode UTF-16字符(16位) Unicode字符0~655535
boolean 布尔值 True/False
请注意,并非所有JVM语言都支持创建基本类型变量,并将其他一切都视为对象。你将看到,这通常不是问题,
因为Java类库包含包装基本类型的包装对象,而包含Java在内的大多数语言都会在必要时自动使用这些包装对象。这个过程被称为自动装箱(auto-boxing)。
3、类
函数和变量都是在类中声明的。即便是应用程序的入口函数(在程序启动时调用的函数main())也是在类中声明的。
JVM只支持单继承模型,即类最多继承一个类。这影响不大,因为使用了名为“接口”的结构来缓解这种影响,你将在下一章看到。
接口基本上是一个函数原型(只有函数的定义,而没有代码)和常量列表,编译器要求实现了接口的类必须提供这些函数的实现。
类可实现任意数量的接口,但必须提供这些接口定义的每个方法的实现。
本书介绍的有些语言对开发人员隐藏了上述事实。
例如,不同于Java,有些语言允许在类声明外面定义函数和变量,甚至允许可执行代码位于函数定义外面。还有些语言支持继承多个类。在内部,这些语言巧妙地规避了JVM的限制和设计决策。
JVM类通常以包的方式进行分组。在下一章,你将看到类是如何组织的。
4、引用类型
与大多数现代编程语言一样,JVM不直接操作指向对象的内存指针,而使用引用类型。引用变量要么指向特定的类实例,要么什么都不指向。
如果一个引用变量指向特定的对象,就可使用它来调用该对象的方法或访问其公有属性。
如果一个引用变量没指向任何东西,就被称为空引用(null reference)。使用空引用来调用方法或访问属性时,将在运行阶段引发错误。
引用和空引用
请看下面的代码:
Product p = new Product(); p.setName("zhangfangming");
假设这里的Product是当前程序可使用的一个类。我们创建一个Product实例,并让变量p指向它。接下来,我们对这个对象实例调用方法setName。
JVM没有提供直接访问这个Product对象所在内存单元的途径,而只提供了指向该对象的引用。当你使用变量p时,JVM将确定为访问这个变量指向的对象,需要访问哪个内存单元。
我们在前述代码片段中添加如下代码行:
p = null; p.setName("Hello World");
可显式地将引用设置为null。请注意,对于在方法内声明的变量,并非必须这样做,因为方法结束时,将自动清理这些变量,但这样做也是完全合法的。
现在变量p是一个空引用。下一段将介绍对象实例不再被任何引用变量指向后将发生的事情。
上述代码能够通过编译,但程序运行时,最后一行将引发NullPointerException异常。如果没有提供错误处理功能,应用程序将崩溃。
5、垃圾收集器
JVM不要求程序员在创建和销毁对象时手工分配和释放内存块。通常,程序员只需在需要时创建对象即可。
有一个名为GC的进程,它每隔一段时间让应用程序停止执行,并在内存中扫描不再在作用域内的对象(不能被任何对象访问的对象),再将这些对象从内存中删除,并收回释放的内存空间。
以前,这个进程会导致严重的性能问题,但它使用的算法已得到极大的改进。另外,根据应用程序的需求,系统管理员可配置GC的众多参数,以更好地控制它。
开发人员应始终牢记GC算法。如果你不断地创建大量的对象,并确保它们位于作用域内(即让所有这些对象都是可访问的,如将它们存储在应用程序可访问的列表中),
那么迟早会导致内存耗尽,进而引发错误。
示例:
假设你为一个在线商店开发了一个电子商务应用程序,同时假设每位已登录的用户都有一个ShoppingBasket实例,其中存储了该用户已加入到购物车中的商品。
现在假设今天有一位已登录的用户,他打算购买一块香皂和一盒饼干。对于这位用户,应用程序将创建两个Product实例(每件商品一个),并将它们添加到ShoppingBasket的products列表中,
结账前,这位用户发现Amazon也有这样的饼干,但价格低得多,因此决定将其从购物车中删除。
从技术上说,应用程序将从products列表中删除相应的Product实例。但这样做后,表示Chocolate cookies的Product实例就成了孤儿对象。
鉴于没有任何引用指向它,应用程序再也无法访问它,过段时间后,JVM的GC启动,它发现应用程序无法访问表示Chocolate cookies的Product对象,因此决定将其删除,从而释放它占用的内存。
为避免GC将对象删除,有多种技巧。其中一个著名的技巧是,在应用程序需要使用大量类似的对象时,将这些对象放在一个对象池(对象列表)中。
在应用程序需要对象时,只需从池中取回一个,并根据需要修改它。使用完毕并不再需要该对象时,将其放回到对象池中。
由于这些对象始终在作用域内(未用时,这些对象位于应用程序能够访问的对象池中),GC不会销毁它们。
6、向后兼容
负责维护JVM和Java类库的人深知企业开发人员的需求:现在编写的代码最好以后也能运行。
在向后兼容方面,JVM做得很不错;如果你熟悉Python 2和Python 3,就知道情况并非总是如此。
较新的JVM版本能够运行针对较旧的JVM版本编译的应用程序,条件是应用程序没有使用在较新的JVM版本中已删除的API或技术。
例如,在Java 8 JVM实例上运行的项目可加载并使用针对Java 6编译的库,但反过来行不通,即在Java 6 JVM实例上运行的应用程序不能加载针对更高版本编译的类。
当然,与其他平台和语言一样,负责维护JDK和Java类库的人必须时不时地摒弃一些类和技术。
在向后兼容性方面,JVM虽然存在问题,但总体而言比众多其他的平台和语言要好得多。另外,通常仅当有合适的替代品后,才会将API删除。
7、构建工具
在项目比较简单的年代,为自动化编译和打包过程,使用的是简单的批文件或操作系统shell脚本文件。
随着项目越来越复杂,定义这样的脚本越来越难。另外,对于不同的操作系统,必须编写完全不同的脚本。
不久后,第一套专用的Java构建工具应运而生。它们使用的是XML构建文件,让你能够编写跨平台的脚本。最初,必须编写冗长而繁琐的脚本;
但后来,这些工具采用了约定优先于配置的范式。遵循这些工具指定的约定时,需要编写的代码少得多;但如果你面对的不是默认情形,可能需要花很大的精力来让工具按你希望的做。
为自动化构建过程,较新的工具放弃了XML文件,转而提供了脚本语言。
在这些工具中,很多都提供了如下功能。
内置的依赖管理器:能够从著名的网络仓库下载附加库。
自动运行单元测试,并在测试失败时停止打包。
JDK本身没有提供构建工具,但几乎每个项目都至少使用了下面一个开源的构建自动化工具。
Apache Ant(没有内置的依赖管理器,使用的是基于XML的构建脚本)。
Apache Maven(通过使用XML文件引入了约定优先于配置的原则,并使用插件)。
Gradle(构建脚本是使用Groovy或Kotlin编写的)。
只要使用的是流行的IDE,JVM程序员就无需过多地考虑构建自动化工具,因为所有IDE都能够生成构建脚本。
如果要获得更大的控制权,可手工编写脚本,并让IDE根据你编写的脚本来编译、测试和运行项目。