监控状态
nagios监控的状态比较特殊,它包含两种状态共通定义。所以单独拎出来说
两种状态
- 服务或主机的状态(即OK,WARNING,UP,DOWN等)
- 服务或主机所在的状态类型
状态类型有两种:SOFT 和 HARD
这些状态类型是监视逻辑的关键部分,因为它们用于确定何时执行事件处理程序以及何时最初发出通知。
本文档介绍了SOFT和HARD状态之间的差异,它们如何发生以及何时发生。
服务和主机检查重试
为了防止因暂时性问题引起的误报,Nagios Core允许您定义在服务或主机被视为“实际”问题之前应被(重新)检查多少次。这由主机和服务定义中的max_check_attempts选项控制。了解主机和服务如何(重新)检查以确定是否存在实际问题对于了解状态类型的工作方式非常重要。
SOFT States
Soft states 发生在以下场景:
- 当一个服务或者主机检测结果是是non-ok non-up state ,并且检测至今还没有达到max_check_attempts,这个就叫做SOFT state
- 当一个服务或者主机recovers从一个soft error, 这个就被认为是一个soft 恢复。
以下事情会发生,当主机或者服务经历了SOFT state变化时:
- the SOFT state is logged
- event handlers are excuted to handle the SOFT state
仅当在主配置文件中启用了log_service_retries或log_host_retries选项时,才会记录SOFT状态。
During SOFT state
当监控状态处于SOFT状态这段时间(毕竟有一个max_check_attempts)最最重要的是事情就是,event handlers的执行情况了。使用event handlers可能是特别有用,如果你想去尝试或者主动去解决一个问题,在这个SOFT状态变为HARD状态之前。$HOSTSTATETYPE$ or $SERVICESSTATETYPE$ macros 将会是SOFT值当event handlers被执行时,这个时候就允许你的Event handler脚本知道这个时候应该做正确的action.
HARD States
以下场景将会发生HARD State:
- 相对于SOFT state,当host or serivce已经是non-OK non-UP且检测次数已经达到max_check_attempts选项值(host or service中定义的),此时就是HARD error state
- 当一个host or service 从hard error state状态迁移到另一个错误状态时(如,WARNING to CRITICAL)
- 当一个service检查状态时non-ok并且它所在的host是DOWN or UNREACHABLE时
- 当一个host or service 从hard error state状态恢复时。这个也叫做hard恢复。
- 当一个passive host check 接收到。被动host checks会被看做是HARD,除非passive_host_checks_are_soft 选项是开启的
以下事情会发生,当主机或者服务经历了HARD state变化时:
- The HARD state is logged.
- Event handlers are executed to handle the HARD state.
- Contacts are notified of the host or service problem or recovery
执行事件处理程序时,$ HOSTSTATETYPE $或$ SERVICESTATETYPE $宏的值将为'HARD',这使您的事件处理程序脚本知道何时应采取纠正措施。有关事件处理程序的更多信息,请参见此处。
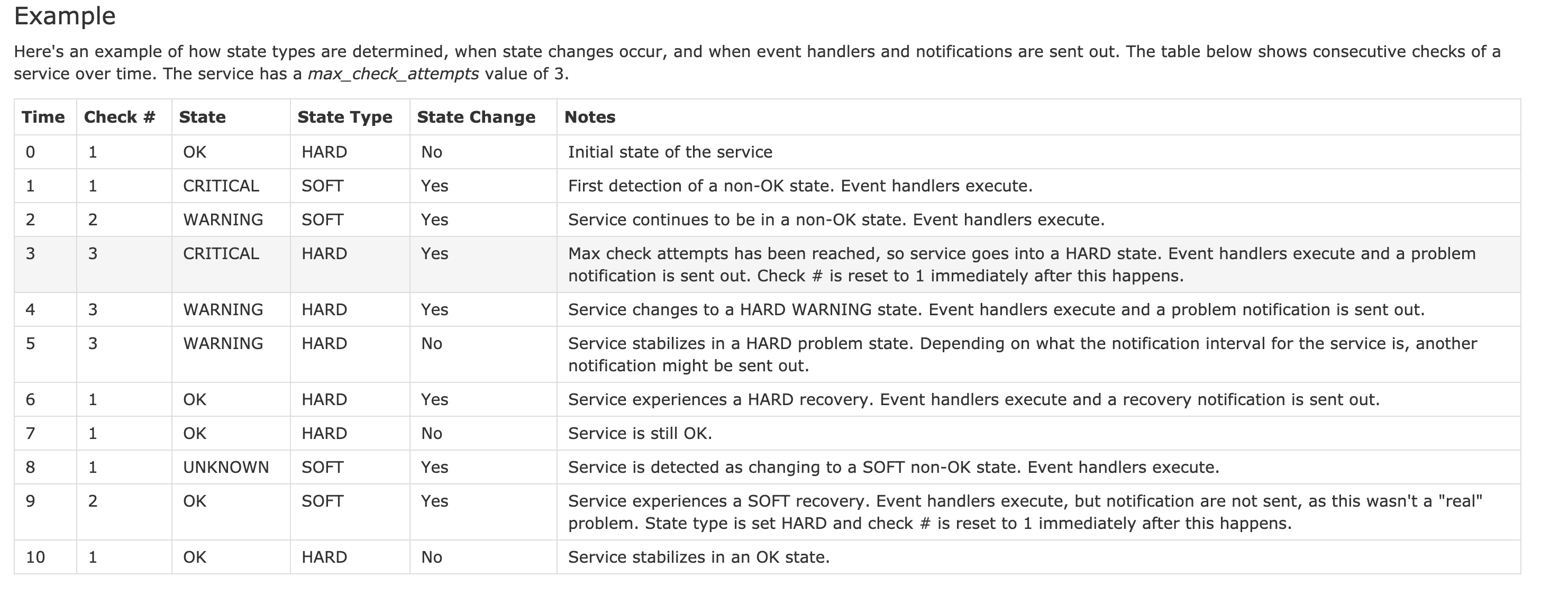
状态变化分析示例