Spark基础
第一节:什么是Spark?Spark的特点和结构
1、什么是Spark?
Spark是一个针对大规模数据处理的快速通用引擎。
类似MapReduce,都进行数据的处理
2、Spark的特点:
(1)基于Scala语言、Spark基于内存的计算
(2)快:基于内存
(3)易用:支持Scala、Java、Python
(4)通用:Spark Core、Spark SQL、Spark Streaming
MLlib、Graphx
(5)兼容性:完全兼容Hadoop
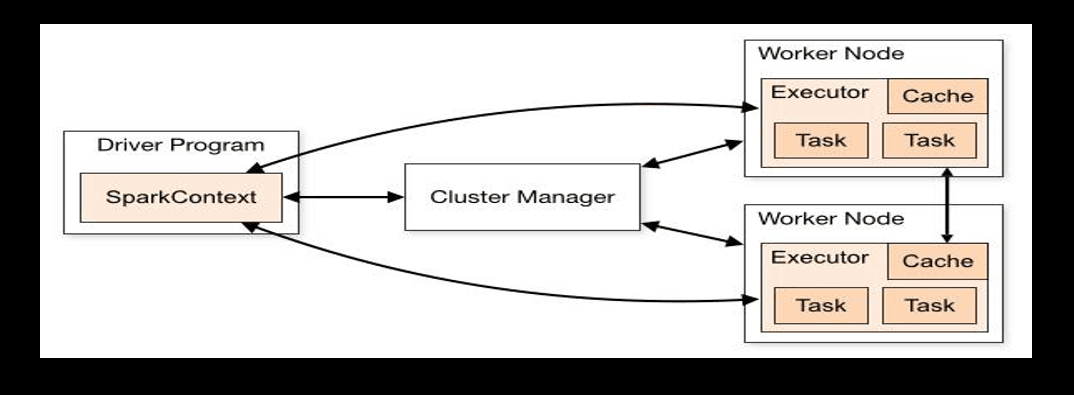
3、Spark体系结构:主从结构
(1)主节点:Master
(2)从节点:Worker
第二节:搭建Spark的伪分布模式环境
1、解压:tar -zxvf spark-2.1.0-bin-hadoop2.4.tgz -C ~/training/
2、配置参数文件: conf/spark-env.sh
export JAVA_HOME=/root/training/jdk1.7.0_75
export SPARK_MASTER_HOST=bigdata11
export SPARK_MASTER_PORT=7077
conf/slaves ----> 从节点的主机信息
bigdata11
3、启动Spark伪分布环境
sbin/start-all.sh
Spark Web Console: http://192.168.88.11:8080
示例图: