一数据准备
cookie1,2015-04-10,1 cookie1,2015-04-11,5 cookie1,2015-04-12,7 cookie1,2015-04-13,3 cookie1,2015-04-14,2 cookie1,2015-04-15,4 cookie1,2015-04-16,4
创建数据库及表
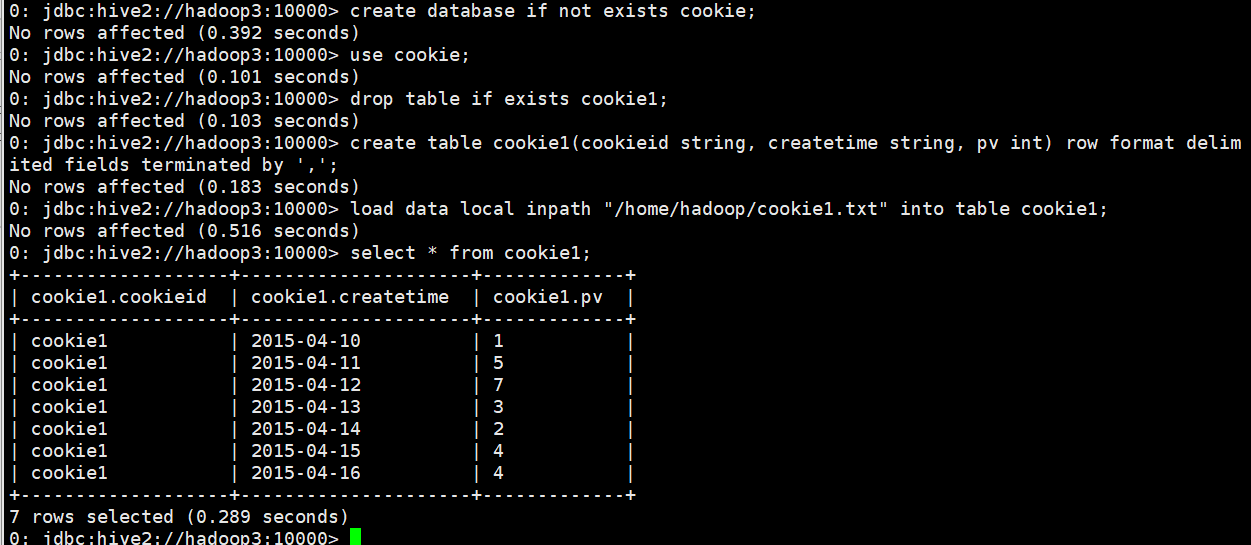
create database if not exists cookie; use cookie; drop table if exists cookie1; create table cookie1(cookieid string, createtime string, pv int) row format delimited fields terminated by ','; load data local inpath "/home/hadoop/cookie1.txt" into table cookie1; select * from cookie1;
SUM
查询语句
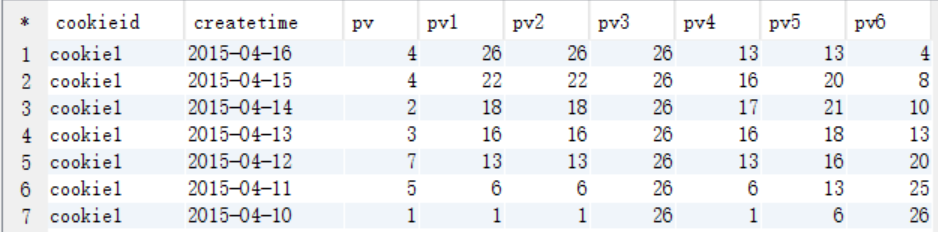
select cookieid, createtime, pv, sum(pv) over (partition by cookieid order by createtime rows between unbounded preceding and current row) as pv1, sum(pv) over (partition by cookieid order by createtime) as pv2, sum(pv) over (partition by cookieid) as pv3, sum(pv) over (partition by cookieid order by createtime rows between 3 preceding and current row) as pv4, sum(pv) over (partition by cookieid order by createtime rows between 3 preceding and 1 following) as pv5, sum(pv) over (partition by cookieid order by createtime rows between current row and unbounded following) as pv6 from cookie1;
查询结果
说明
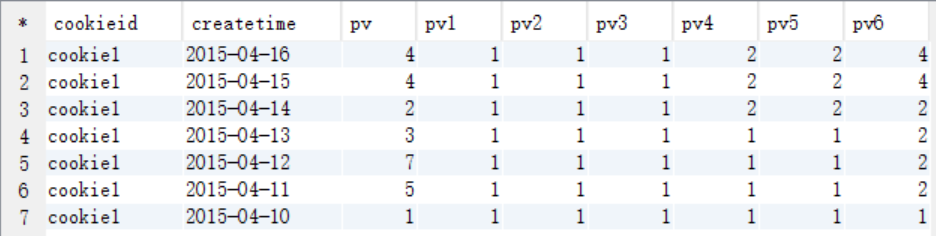
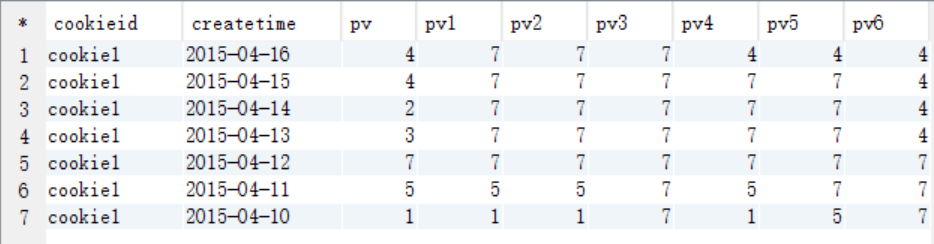
pv1: 分组内从起点到当前行的pv累积,如,11号的pv1=10号的pv+11号的pv, 12号=10号+11号+12号 pv2: 同pv1 pv3: 分组内(cookie1)所有的pv累加 pv4: 分组内当前行+往前3行,如,11号=10号+11号, 12号=10号+11号+12号, 13号=10号+11号+12号+13号, 14号=11号+12号+13号+14号 pv5: 分组内当前行+往前3行+往后1行,如,14号=11号+12号+13号+14号+15号=5+7+3+2+4=21 pv6: 分组内当前行+往后所有行,如,13号=13号+14号+15号+16号=3+2+4+4=13,14号=14号+15号+16号=2+4+4=10
如果不指定ROWS BETWEEN,默认为从起点到当前行;
如果不指定ORDER BY,则将分组内所有值累加;
关键是理解ROWS BETWEEN含义,也叫做WINDOW子句:
PRECEDING:往前
FOLLOWING:往后
CURRENT ROW:当前行
UNBOUNDED:起点,
UNBOUNDED PRECEDING 表示从前面的起点,
UNBOUNDED FOLLOWING:表示到后面的终点
–其他AVG,MIN,MAX,和SUM用法一样。
AVG
查询语句
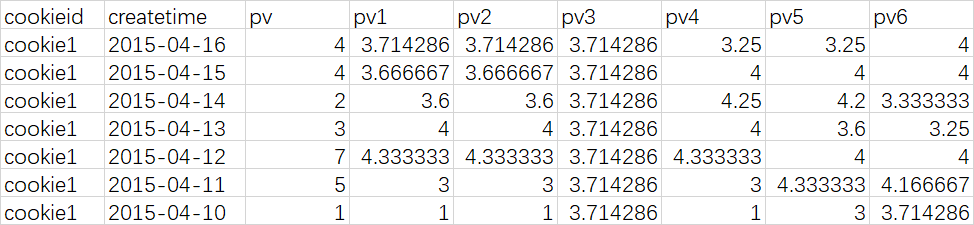
select cookieid, createtime, pv, avg(pv) over (partition by cookieid order by createtime rows between unbounded preceding and current row) as pv1, -- 默认为从起点到当前行 avg(pv) over (partition by cookieid order by createtime) as pv2, --从起点到当前行,结果同pv1 avg(pv) over (partition by cookieid) as pv3, --分组内所有行 avg(pv) over (partition by cookieid order by createtime rows between 3 preceding and current row) as pv4, --当前行+往前3行 avg(pv) over (partition by cookieid order by createtime rows between 3 preceding and 1 following) as pv5, --当前行+往前3行+往后1行 avg(pv) over (partition by cookieid order by createtime rows between current row and unbounded following) as pv6 --当前行+往后所有行 from cookie1;
查询结果
MIN
查询语句
select cookieid, createtime, pv, min(pv) over (partition by cookieid order by createtime rows between unbounded preceding and current row) as pv1, -- 默认为从起点到当前行 min(pv) over (partition by cookieid order by createtime) as pv2, --从起点到当前行,结果同pv1 min(pv) over (partition by cookieid) as pv3, --分组内所有行 min(pv) over (partition by cookieid order by createtime rows between 3 preceding and current row) as pv4, --当前行+往前3行 min(pv) over (partition by cookieid order by createtime rows between 3 preceding and 1 following) as pv5, --当前行+往前3行+往后1行 min(pv) over (partition by cookieid order by createtime rows between current row and unbounded following) as pv6 --当前行+往后所有行 from cookie1;
查询结果
MAX
查询语句
select cookieid, createtime, pv, max(pv) over (partition by cookieid order by createtime rows between unbounded preceding and current row) as pv1, -- 默认为从起点到当前行 max(pv) over (partition by cookieid order by createtime) as pv2, --从起点到当前行,结果同pv1 max(pv) over (partition by cookieid) as pv3, --分组内所有行 max(pv) over (partition by cookieid order by createtime rows between 3 preceding and current row) as pv4, --当前行+往前3行 max(pv) over (partition by cookieid order by createtime rows between 3 preceding and 1 following) as pv5, --当前行+往前3行+往后1行 max(pv) over (partition by cookieid order by createtime rows between current row and unbounded following) as pv6 --当前行+往后所有行 from cookie1;
查询结果
二数据准备
接下来介绍前几个序列函数,NTILE,ROW_NUMBER,RANK,DENSE_RANK,下面会一一解释各自的用途。
注意: 序列函数不支持WINDOW子句。(ROWS BETWEEN)
cookie1,2015-04-10,1 cookie1,2015-04-11,5 cookie1,2015-04-12,7 cookie1,2015-04-13,3 cookie1,2015-04-14,2 cookie1,2015-04-15,4 cookie1,2015-04-16,4 cookie2,2015-04-10,2 cookie2,2015-04-11,3 cookie2,2015-04-12,5 cookie2,2015-04-13,6 cookie2,2015-04-14,3 cookie2,2015-04-15,9 cookie2,2015-04-16,7
创建表
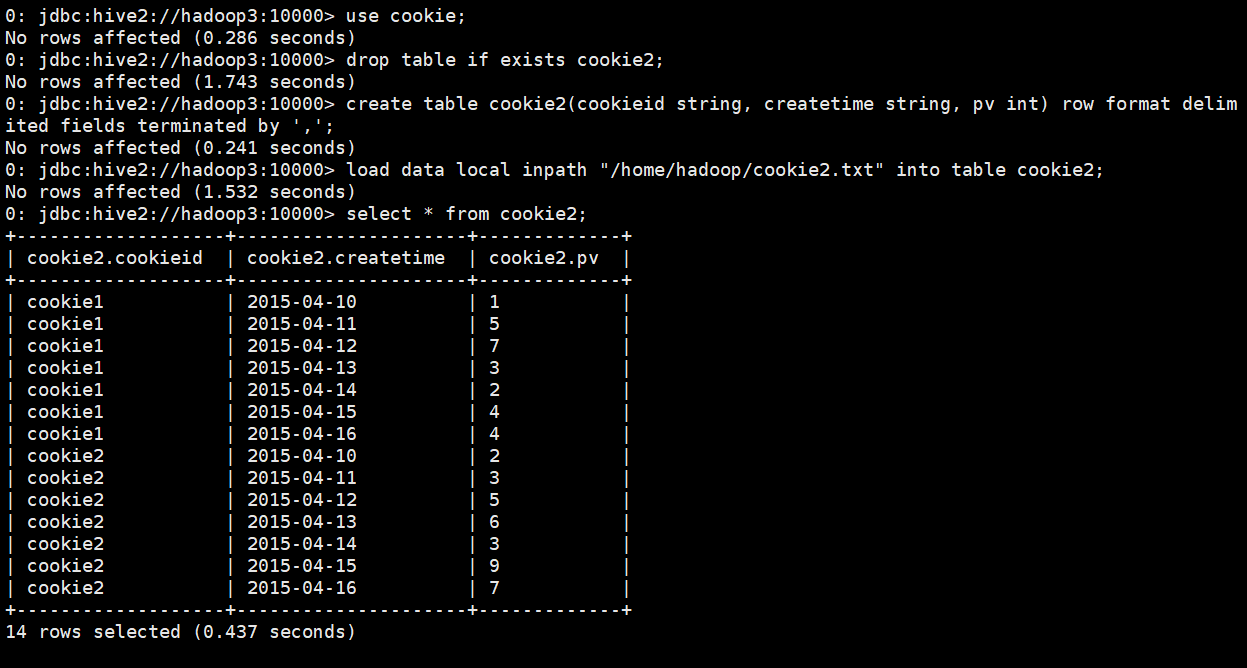
use cookie; drop table if exists cookie2; create table cookie2(cookieid string, createtime string, pv int) row format delimited fields terminated by ','; load data local inpath "/home/hadoop/cookie2.txt" into table cookie2; select * from cookie2;
NTILE
说明
NTILE(n),用于将分组数据按照顺序切分成n片,返回当前切片值
NTILE不支持ROWS BETWEEN,比如 NTILE(2) OVER(PARTITION BY cookieid ORDER BY createtime ROWS BETWEEN 3 PRECEDING AND CURRENT ROW)
如果切片不均匀,默认增加第一个切片的分布
查询语句
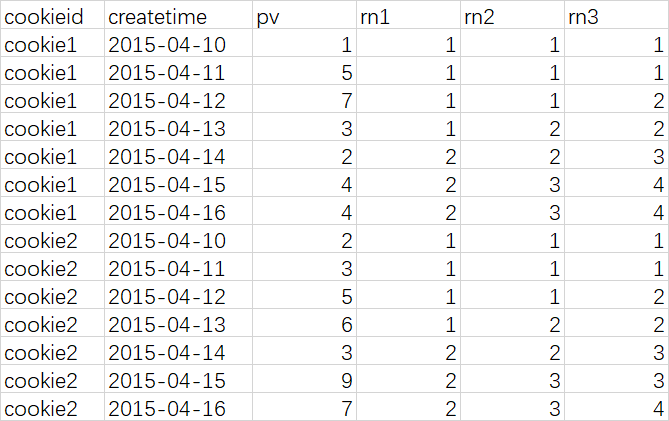
select cookieid, createtime, pv, ntile(2) over (partition by cookieid order by createtime) as rn1, --分组内将数据分成2片 ntile(3) over (partition by cookieid order by createtime) as rn2, --分组内将数据分成2片 ntile(4) over (order by createtime) as rn3 --将所有数据分成4片 from cookie.cookie2 order by cookieid,createtime;
查询结果
比如,统计一个cookie,pv数最多的前1/3的天
查询语句
select cookieid, createtime, pv, ntile(3) over (partition by cookieid order by pv desc ) as rn from cookie.cookie2;
查询结果
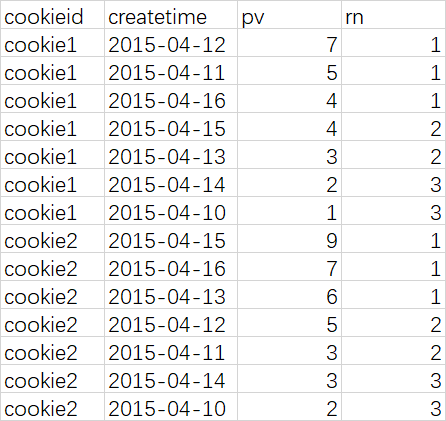
--rn = 1 的记录,就是我们想要的结果
ROW_NUMBER
说明
ROW_NUMBER() –从1开始,按照顺序,生成分组内记录的序列
–比如,按照pv降序排列,生成分组内每天的pv名次
ROW_NUMBER() 的应用场景非常多,再比如,获取分组内排序第一的记录;获取一个session中的第一条refer等。
分组排序
select cookieid, createtime, pv, row_number() over (partition by cookieid order by pv desc) as rn from cookie.cookie2;
查询结果
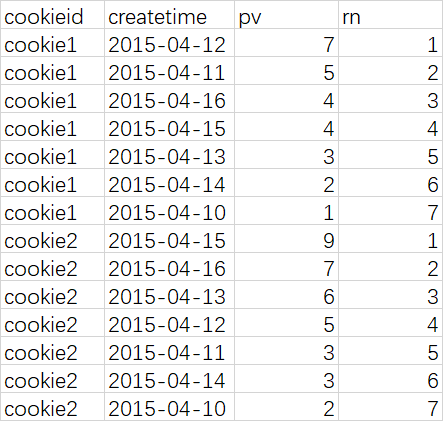
-- 所以如果需要取每一组的前3名,只需要rn<=3即可,适合TopN
RANK 和 DENSE_RANK
—RANK() 生成数据项在分组中的排名,排名相等会在名次中留下空位
—DENSE_RANK() 生成数据项在分组中的排名,排名相等会在名次中不会留下空位
查询语句
select cookieid, createtime, pv, rank() over (partition by cookieid order by pv desc) as rn1, dense_rank() over (partition by cookieid order by pv desc) as rn2, row_number() over (partition by cookieid order by pv desc) as rn3 from cookie.cookie2 where cookieid='cookie1';
查询结果
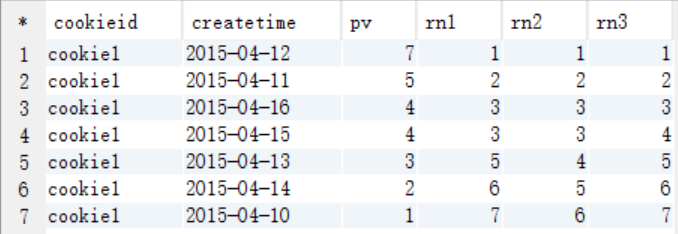
ROW_NUMBER、RANK和DENSE_RANK的区别
row_number: 按顺序编号,不留空位
rank: 按顺序编号,相同的值编相同号,留空位
dense_rank: 按顺序编号,相同的值编相同的号,不留空位
三数据准备
cookie3.txt
d1,user1,1000 d1,user2,2000 d1,user3,3000 d2,user4,4000 d2,user5,5000
创建表
use cookie; drop table if exists cookie3; create table cookie3(dept string, userid string, sal int) row format delimited fields terminated by ','; load data local inpath "/home/hadoop/cookie3.txt" into table cookie3; select * from cookie3;

CUME_DIST
说明
–CUME_DIST :小于等于当前值的行数/分组内总行数
查询语句
比如,统计小于等于当前薪水的人数,所占总人数的比例
select dept, userid, sal, cume_dist() over (order by sal) as rn1, cume_dist() over (partition by dept order by sal) as rn2 from cookie.cookie3;
查询结果
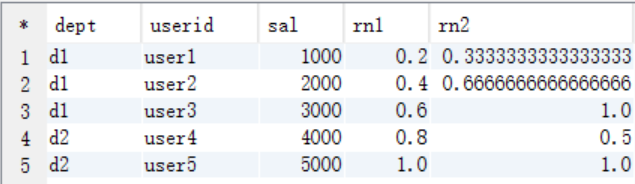
结果说明
rn1: 没有partition,所有数据均为1组,总行数为5,
第一行:小于等于1000的行数为1,因此,1/5=0.2
第三行:小于等于3000的行数为3,因此,3/5=0.6
rn2: 按照部门分组,dpet=d1的行数为3,
第二行:小于等于2000的行数为2,因此,2/3=0.6666666666666666
PERCENT_RANK
说明
–PERCENT_RANK :分组内当前行的RANK值-1/分组内总行数-1
查询语句
select dept, userid, sal, percent_rank() over (order by sal) as rn1, --分组内 rank() over (order by sal) as rn11, --分组内的rank值 sum(1) over (partition by null) as rn12, --分组内总行数 percent_rank() over (partition by dept order by sal) as rn2, rank() over (partition by dept order by sal) as rn21, sum(1) over (partition by dept) as rn22 from cookie.cookie3;
查询结果
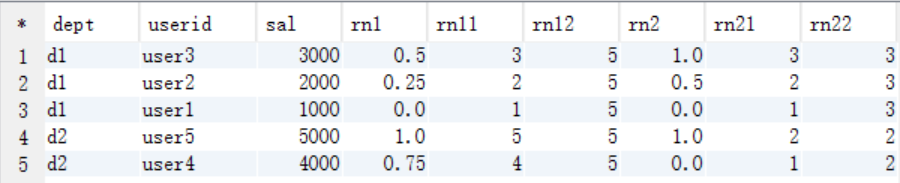
结果说明
–PERCENT_RANK :分组内当前行的RANK值-1/分组内总行数-1
rn1 == (rn11-1) / (rn12-1)
rn2 == (rn21-1) / (rn22-1)
rn1: rn1 = (rn11-1) / (rn12-1) 第一行,(1-1)/(5-1)=0/4=0 第二行,(2-1)/(5-1)=1/4=0.25 第四行,(4-1)/(5-1)=3/4=0.75 rn2: 按照dept分组, dept=d1的总行数为3 第一行,(1-1)/(3-1)=0 第三行,(3-1)/(3-1)=1
四数据准备
cookie4.txt
cookie1,2015-04-10 10:00:02,url2 cookie1,2015-04-10 10:00:00,url1 cookie1,2015-04-10 10:03:04,1url3 cookie1,2015-04-10 10:50:05,url6 cookie1,2015-04-10 11:00:00,url7 cookie1,2015-04-10 10:10:00,url4 cookie1,2015-04-10 10:50:01,url5 cookie2,2015-04-10 10:00:02,url22 cookie2,2015-04-10 10:00:00,url11 cookie2,2015-04-10 10:03:04,1url33 cookie2,2015-04-10 10:50:05,url66 cookie2,2015-04-10 11:00:00,url77 cookie2,2015-04-10 10:10:00,url44 cookie2,2015-04-10 10:50:01,url55
创建表
use cookie; drop table if exists cookie4; create table cookie4(cookieid string, createtime string, url string) row format delimited fields terminated by ','; load data local inpath "/home/hadoop/cookie4.txt" into table cookie4; select * from cookie4;
LAG
说明
LAG(col,n,DEFAULT) 用于统计窗口内往上第n行值
第一个参数为列名,
第二个参数为往上第n行(可选,默认为1),
第三个参数为默认值(当往上第n行为NULL时候,取默认值,如不指定,则为NULL)
查询语句
select cookieid, createtime, url, row_number() over (partition by cookieid order by createtime) as rn, LAG(createtime,1,'1970-01-01 00:00:00') over (partition by cookieid order by createtime) as last_1_time, LAG(createtime,2) over (partition by cookieid order by createtime) as last_2_time from cookie.cookie4;
查询结果
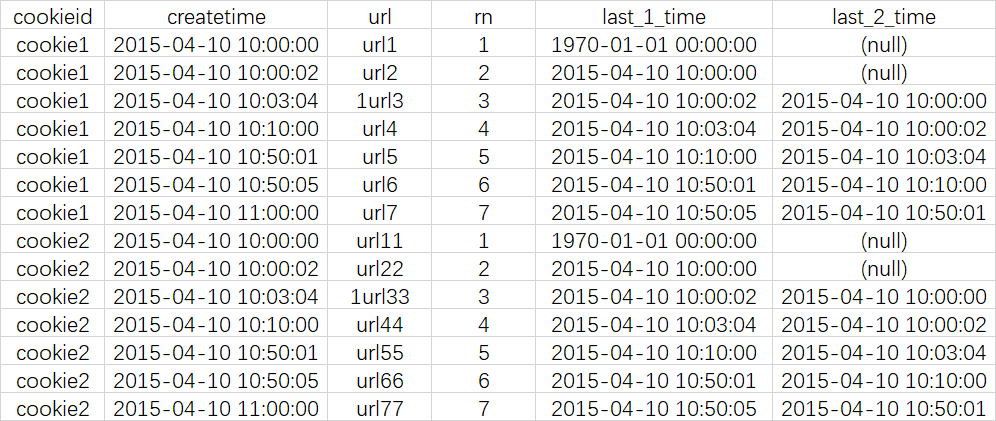
结果说明
last_1_time: 指定了往上第1行的值,default为'1970-01-01 00:00:00' cookie1第一行,往上1行为NULL,因此取默认值 1970-01-01 00:00:00 cookie1第三行,往上1行值为第二行值,2015-04-10 10:00:02 cookie1第六行,往上1行值为第五行值,2015-04-10 10:50:01 last_2_time: 指定了往上第2行的值,为指定默认值 cookie1第一行,往上2行为NULL cookie1第二行,往上2行为NULL cookie1第四行,往上2行为第二行值,2015-04-10 10:00:02 cookie1第七行,往上2行为第五行值,2015-04-10 10:50:01
LEAD
说明
与LAG相反
LEAD(col,n,DEFAULT) 用于统计窗口内往下第n行值
第一个参数为列名,
第二个参数为往下第n行(可选,默认为1),
第三个参数为默认值(当往下第n行为NULL时候,取默认值,如不指定,则为NULL)
查询语句
select cookieid, createtime, url, row_number() over (partition by cookieid order by createtime) as rn, LEAD(createtime,1,'1970-01-01 00:00:00') over (partition by cookieid order by createtime) as next_1_time, LEAD(createtime,2) over (partition by cookieid order by createtime) as next_2_time from cookie.cookie4;
查询结果
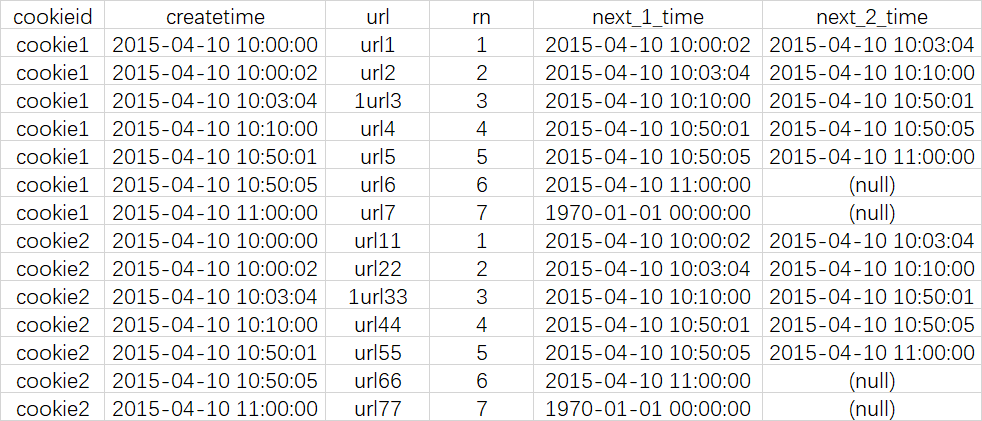
结果说明
--逻辑与LAG一样,只不过LAG是往上,LEAD是往下。
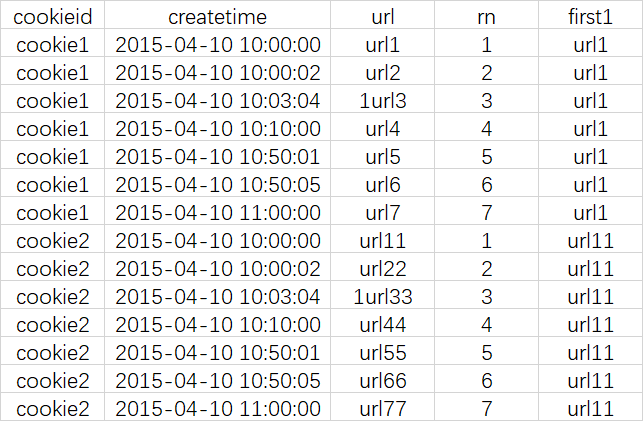
FIRST_VALUE
说明
取分组内排序后,截止到当前行,第一个值
查询语句
select cookieid, createtime, url, row_number() over (partition by cookieid order by createtime) as rn, first_value(url) over (partition by cookieid order by createtime) as first1 from cookie.cookie4;
查询结果
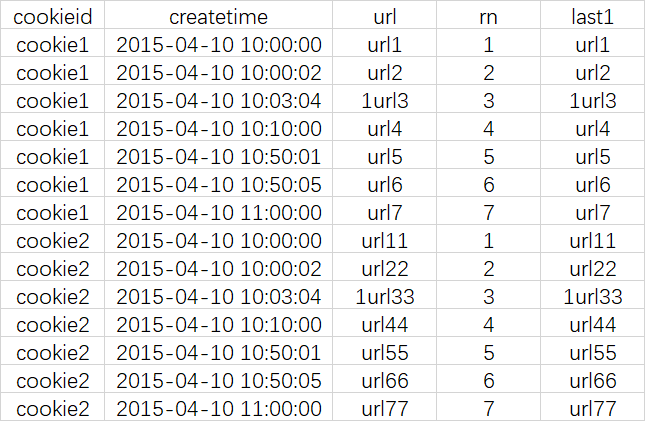
LAST_VALUE
说明
取分组内排序后,截止到当前行,最后一个值
查询语句
select cookieid, createtime, url, row_number() over (partition by cookieid order by createtime) as rn, last_value(url) over (partition by cookieid order by createtime) as last1 from cookie.cookie4;
查询结果
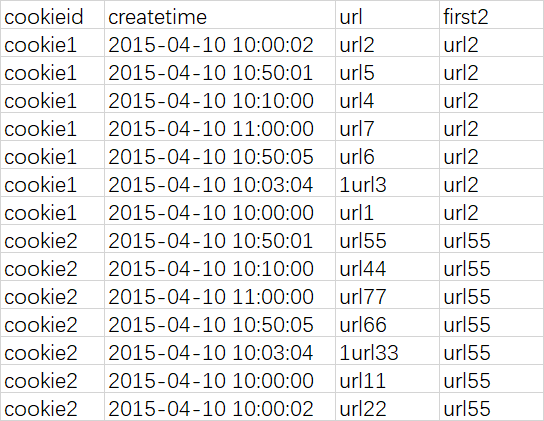
如果不指定ORDER BY,则默认按照记录在文件中的偏移量进行排序,会出现错误的结果
如果想要取分组内排序后最后一个值,则需要变通一下
查询语句
select cookieid, createtime, url, row_number() over (partition by cookieid order by createtime) as rn, LAST_VALUE(url) over (partition by cookieid order by createtime) as last1, FIRST_VALUE(url) over (partition by cookieid order by createtime desc) as last2 from cookie.cookie4 order by cookieid,createtime;
查询结果
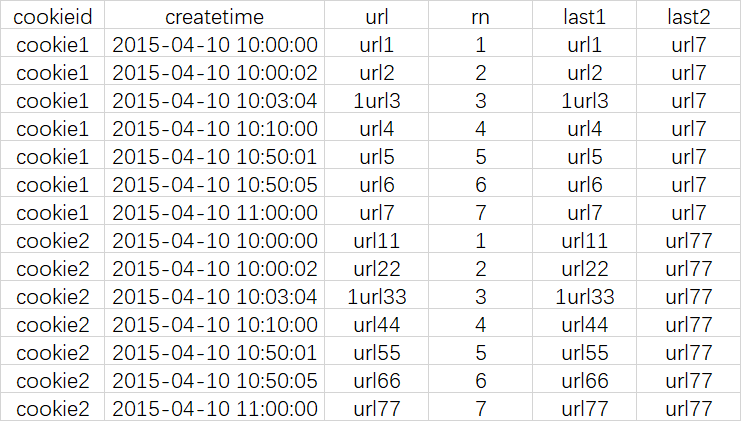
提示:在使用分析函数的过程中,要特别注意ORDER BY子句,用的不恰当,统计出的结果就不是你所期望的。
五数据准备
GROUPING SETS,GROUPING__ID,CUBE,ROLLUP
这几个分析函数通常用于OLAP中,不能累加,而且需要根据不同维度上钻和下钻的指标统计,比如,分小时、天、月的UV数。
2015-03,2015-03-10,cookie1 2015-03,2015-03-10,cookie5 2015-03,2015-03-12,cookie7 2015-04,2015-04-12,cookie3 2015-04,2015-04-13,cookie2 2015-04,2015-04-13,cookie4 2015-04,2015-04-16,cookie4 2015-03,2015-03-10,cookie2 2015-03,2015-03-10,cookie3 2015-04,2015-04-12,cookie5 2015-04,2015-04-13,cookie6 2015-04,2015-04-15,cookie3 2015-04,2015-04-15,cookie2 2015-04,2015-04-16,cookie1
创建表
use cookie; drop table if exists cookie5; create table cookie5(month string, day string, cookieid string) row format delimited fields terminated by ','; load data local inpath "/home/hadoop/cookie5.txt" into table cookie5; select * from cookie5;
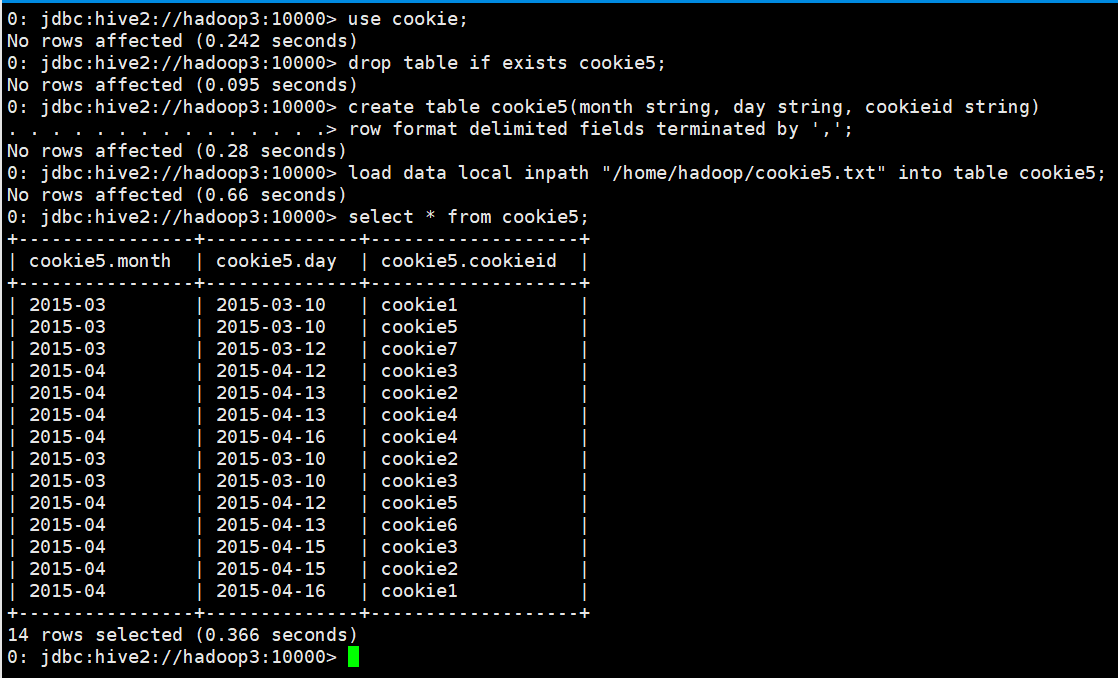
GROUPING SETS和GROUPING__ID
说明
在一个GROUP BY查询中,根据不同的维度组合进行聚合,等价于将不同维度的GROUP BY结果集进行UNION ALL
GROUPING__ID,表示结果属于哪一个分组集合。
查询语句
select month, day, count(distinct cookieid) as uv, GROUPING__ID from cookie.cookie5 group by month,day grouping sets (month,day) order by GROUPING__ID;
等价于
SELECT month,NULL,COUNT(DISTINCT cookieid) AS uv,1 AS GROUPING__ID FROM cookie5 GROUP BY month UNION ALL SELECT NULL,day,COUNT(DISTINCT cookieid) AS uv,2 AS GROUPING__ID FROM cookie5 GROUP BY day
查询结果
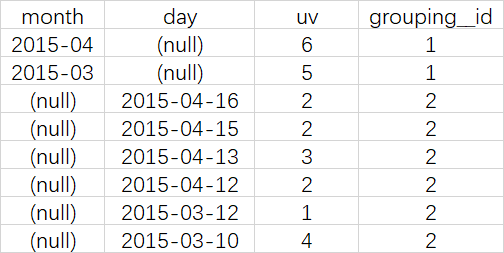
结果说明
第一列是按照month进行分组
第二列是按照day进行分组
第三列是按照month或day分组是,统计这一组有几个不同的cookieid
第四列grouping_id表示这一组结果属于哪个分组集合,根据grouping sets中的分组条件month,day,1是代表month,2是代表day
再比如
SELECT month, day, COUNT(DISTINCT cookieid) AS uv, GROUPING__ID FROM cookie5 GROUP BY month,day GROUPING SETS (month,day,(month,day)) ORDER BY GROUPING__ID;
等价于
SELECT month,NULL,COUNT(DISTINCT cookieid) AS uv,1 AS GROUPING__ID FROM cookie5 GROUP BY month UNION ALL SELECT NULL,day,COUNT(DISTINCT cookieid) AS uv,2 AS GROUPING__ID FROM cookie5 GROUP BY day UNION ALL SELECT month,day,COUNT(DISTINCT cookieid) AS uv,3 AS GROUPING__ID FROM cookie5 GROUP BY month,day

CUBE
说明
根据GROUP BY的维度的所有组合进行聚合
查询语句
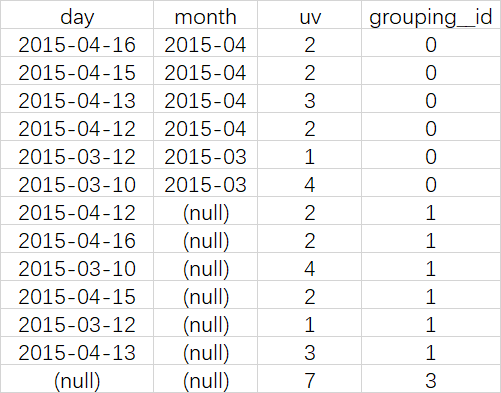
SELECT month, day, COUNT(DISTINCT cookieid) AS uv, GROUPING__ID FROM cookie5 GROUP BY month,day WITH CUBE ORDER BY GROUPING__ID;
等价于
SELECT NULL,NULL,COUNT(DISTINCT cookieid) AS uv,0 AS GROUPING__ID FROM cookie5 UNION ALL SELECT month,NULL,COUNT(DISTINCT cookieid) AS uv,1 AS GROUPING__ID FROM cookie5 GROUP BY month UNION ALL SELECT NULL,day,COUNT(DISTINCT cookieid) AS uv,2 AS GROUPING__ID FROM cookie5 GROUP BY day UNION ALL SELECT month,day,COUNT(DISTINCT cookieid) AS uv,3 AS GROUPING__ID FROM cookie5 GROUP BY month,day
查询结果
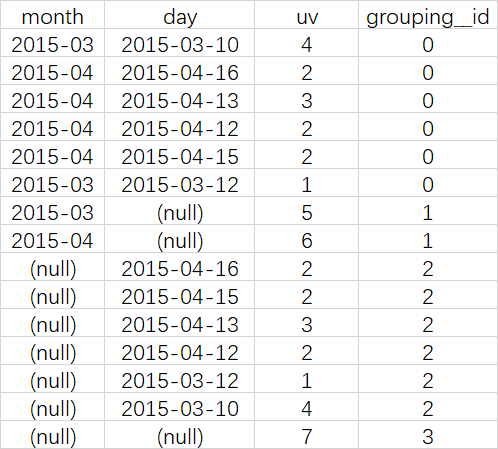
ROLLUP
说明
是CUBE的子集,以最左侧的维度为主,从该维度进行层级聚合
查询语句
-- 比如,以month维度进行层级聚合
SELECT month, day, COUNT(DISTINCT cookieid) AS uv, GROUPING__ID FROM cookie5 GROUP BY month,day WITH ROLLUP ORDER BY GROUPING__ID;
可以实现这样的上钻过程:
月天的UV->月的UV->总UV
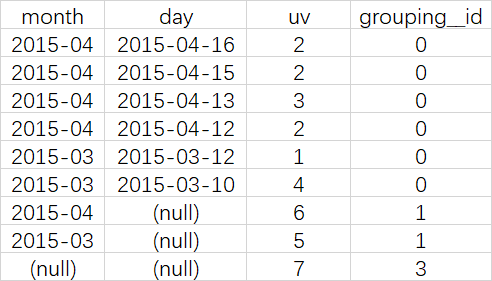
--把month和day调换顺序,则以day维度进行层级聚合:
可以实现这样的上钻过程:
天月的UV->天的UV->总UV
(这里,根据天和月进行聚合,和根据天聚合结果一样,因为有父子关系,如果是其他维度组合的话,就会不一样)