影响你的查询速度的原因是什么?
- 网速不给力,不稳定。
- 服务器内存不够,或者SQL 被分配的内存不够。
- sql语句设计不合理
- 没有相应的索引,索引不合理
- 表数据过大没有有效的分区设计
- 数据库设计太2,存在大量的数据冗余
那我们如何找到速度慢的原因呢?
- 首先你要知道是否跟sql语句有关,确保不是机器开不开机,服务器硬件配置太差,没网你说p啊
- sql server profiler,分析出sql慢的相关语句,就是执行时间过长,占用系统资源,cpu过多的工具
- 然后是这篇文章要说的,sql优化方法跟技巧,避免一些不合理的sql语句,取暂优sql
- 再然后判断是否使用啦,合理的统计信息。
- 确认表中使用啦合理的索引
- 数据太多的表,要分区,缩小查找范围
分析SQL语句执行的时间
1.记录查询时间和cpu占用时间
set statistics time on select * from DetitalIndex set statistics time off

2.记录I/O的支配
set statistics io on select * from dbo.Product set statistics io off

扫描计数:索引或表扫描次数
逻辑读取:数据缓存中读取的页数
物理读取:从磁盘中读取的页数
预读:查询过程中,从磁盘放入缓存的页数
lob逻辑读取:从数据缓存中读取,image,text,ntext或大型数据的页数
lob物理读取:从磁盘中读取,image,text,ntext或大型数据的页数
lob预读:查询过程中,从磁盘放入缓存的image,text,ntext或大型数据的页数
如果是物理次数和预读次数较多,可以使用索引进行优化。
如果不想使用sql命令去查看这些内容,可以在sqlserver的新建查询中 右击找到查询选项
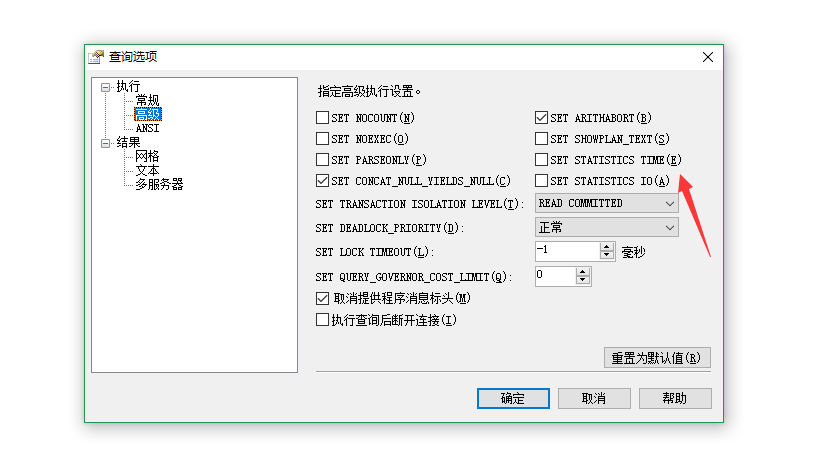
勾中Set statistics time 与 io 确定即可.
3.查看执行计划

鼠标放到这个图标会出现查询的详细步骤,且看到你哪个sql花费的开销有多大,如果哪个表的占比过大,证明该表的索引设计不对,或者说性能有待提高.
select是一把钢刀,磨好了可秒杀敌军将领!磨不好则是自杀。
1.保证不要出现*,请使用列代替*
2.使用where查询时,尽量避免多余的列
3.使用top 或 distinct 减少多余或重复
(常言道, 什么玩腻都是一把双刃剑)
1.distinct
distinct在查询一个字段或者很少字段的情况下使用,会避免重复数据的出现,给查询带来优化效果。
但是查询字段很多的情况下使用,则会大大降低查询效率。

这个测试结果代表了使用distint,数据库会占用cpu对数据进行筛选。 所以说少用distinct
2.判断表是否存在数据
select count(*) from IndentDetails select top(1) id from IndentDetails
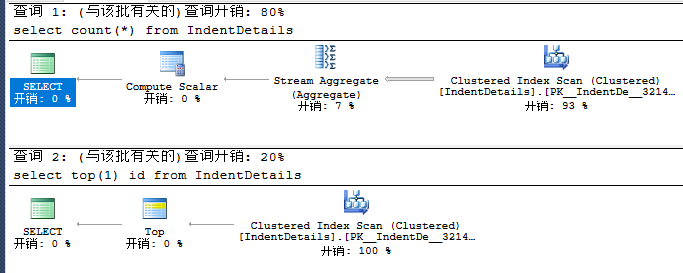
很显然下面的完胜
3.连接查询优化
select * from (select * from Student) o left join Grade on o.GradeId = Grade.GradeId select * from (Student s left join Grade g on s.GradeId=g.GradeId)

减少表连接可以提高查询性能,当然这个差距是由数据大小进行扩大的。
修改删除SQL性能优化
如果成群的操作,会造成cpu的利用率过高从而影响其他用户访问数据库.
再如果单个的迭代进行操作,那么效率就太低了.
所以我们采用折中的方式.进行分块操作
delete orderwhere id<1000 delete order where id>=1000 and id<2000 delete orderwhere id>=2000 and id<3000 .....