本随笔参考多篇博客来写,就不再一一写出来了,如有冒犯多多包涵。
一、mysql体系结构
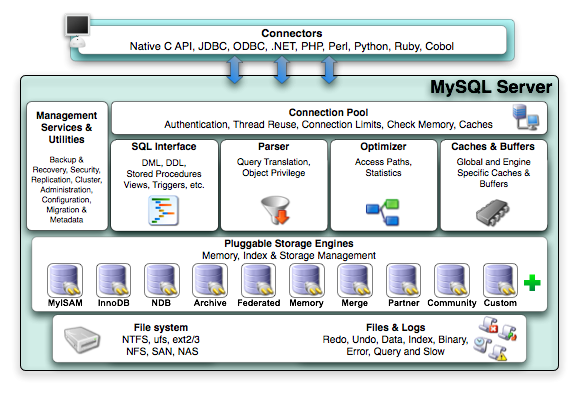
1.Connectors 连接器: 相当于一个驱动程序,不同的客户端程序连接Mysql时需要用的的驱动程序,例如c++、java客户端程序等等。
2.Connectors 连接池: 管理缓冲用户连接,线程处理等需要缓存的需求。
3.SQL Interface SQL接口:接收用户的sql命令,并给用户返回结果。
4.Parser 解析器:把SQL语句分解成数据结构,如果在分解过程中遇到错误,则说明这个语句有语法错误。
5.Optimizer 查询优化器:SQL在查询之前会被优化器进行优化,最后选择最优的策略进行查询。优化器的作用主要是对查询语句进行优化操作,包括选择合适的 索引,数据的读取方式,包括获取查询的开销信息,统计信息等,这也是为什么图中会有优化器指向存储引擎的箭头。
6.Cache & Buffers 缓存和缓冲区:如果查询缓存有命中的查询结果,查询语句就可以直接去查询缓存中取数据。
7.Engines 存储引擎:Mysql5.5之后默认的是innodb。
存储引擎是MySql中具体的与文件打交道的子系统。也是Mysql最具有特色的一个地方。
Mysql的存储引擎是插件式的。它根据MySql AB公司提供的文件访问层的一个抽象接口来定制一种文件访问机制(这种访问机制就叫存储引擎)
存储引擎:
锁:Mysql各存储引擎使用了三种级别的锁定机制:表级锁,页级锁(主要是BerkeleyDB存储引擎在使用),行级锁。同时,锁一般分有共享锁(read)和互斥锁(write),所以说并行写,串行读。
1.表级锁:表级锁是Mysql各存储引擎中最大粒度的锁定机制。该锁定机制的最大特点是实现逻辑非常简单,带来系统的负面影响最小。获取锁和释放锁的的速度 很快。因为一次锁定一个表,很好的避免了死锁的问题。
2.行级锁:锁定对象粒度很小,是目前锁定粒度最小的锁定机制。因为锁定粒度小,所以发生资源竞争的概率小,因此高并发性能好。但是每次获得锁和释放锁所 做的事情就更多,资源消耗也更大。
3.页级锁:锁定对象粒度和高并发性能介于行级锁和表级锁之间。
总而言之,Mysql这三种锁的性能大致可以归纳为:
表级锁:开销小,加锁快;不会出现死锁;锁定粒度大,发生锁冲突的概率最高,并发度最低;
行级锁:开销大,加锁慢;会出现死锁;锁定粒度最小,发生锁冲突的概率最低,并发度也最高;
页面锁:开销和加锁时间界于表锁和行锁之间;会出现死锁;锁定粒度界于表锁和行锁之间,并发度一般。
适用:从锁的角度来说,表级锁更适合于以查询为主,只有少量按索引条件更新数据的应用,如Web应用;而行级锁则更适合于有大量按索引条件并发更新少量不 同数据,同时又有并发查询的应用,如一些在线事务处理(OLTP)系统。
事务:Mysql和其他数据库产品有一个很大的不同点就是,是否支持事务由具体的存储引擎决定,有不支持事务的存储引擎,也有支持事务的存储引擎。事务就是 为了解决一组操作,要么全部执行,要么全部不执行。
那么,事务到底是如何工作的呢?
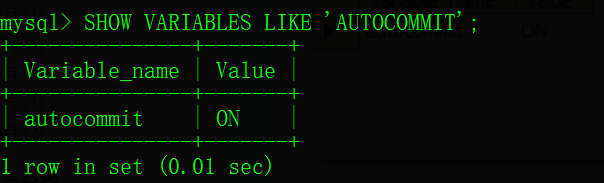
当我们显示开启一个事务的时候,只有等我们 执行了commit操作的时候,才会将操作的结果持久化,不commit就不会持久化。如果我们不开启事务,只执行一条sql就会马上持久化,因为Mysql默认是自动提交的,除非显式开启了一个事务。也就是说,开启事务,其实就是关闭了自动提交功能,改成了commit手动提交。
Mysql事务默认是采取自动提交的模式,除非显式开启一个事务:
事务的四个特性 ACID:原子性,一致性,隔离性,持久性。
原子性:原子性是指事务是一个不可分割的执行单元,事务中的操作要么全部执行,要么全部不执行。
一致性:一致性是指事务开启之前和事务结束之后事务的完整性约束没有被破坏,完整性约束包括唯一约束,外键约束,check约束等等。
隔离性:隔离性是指多个事务并发发生时,事务和事务之间是隔离的,事务查看数据更新时,要么是另一个事务修改它之前的状态,要么是一个事务修改完它之后 的状态,不可能是中间的状态。
持久性:持久性是指在事务提交之后,事务对数据的更改就会持久的保存在数据库中,不能被回滚。
隔离级别:
既然隔离性是为了解决多个事务并发时带来的问题的,那当多个事务并发时到底会导致哪些问题呢?
1.脏读:一个事务对一条数据进行了修改但还没有提交,另一个事务读取了修改后的数据并进行了进一步处理,就会产生未提交的数据依赖。
举一个例子:
| 时间 | 转账事务A | 取款事务B |
|---|---|---|
| T1 | 开始事务 | |
| T2 | 开始事务 | |
| T3 | 查询账户余额为1000元 | |
| T4 | 取出500元把余额改为500元 | |
| T5 | 查询账户余额为500元(脏读) | |
| T6 | 撤销事务余额恢复为1000元 | |
| T7 | 汇入100元把余额改为600元 | |
| T8 | 提交事务 |
A读取了B尚未提交的脏数,导致最后余额为600元。
2.不可重复读:一个事务在不同时间读取同一个数据,结果不一样
举一个例子:
| 时间 | 取款事务A | 转账事务B |
|---|---|---|
| T1 | 开始事务 | |
| T2 | 开始事务 | |
| T3 | 查询账户余额为1000元 | |
| T4 | 查询账户余额为1000元 | |
| T5 | 取出100元把余额改为900元 | |
| T6 | 提交事务 | |
| T7 | 查询账户余额为900元(和T4读取的不一致) |
可以看到最后读取的数据不一致。
3.幻读:幻读和不可重复读的概念类似,都是不同时间数据不一致,只不过幻读是针对新增数据,而不可重复读是针对更改数据。
看一个例子:
| 时间 | 统计金额事务A | 转账事务B |
|---|---|---|
| T1 | 开始事务 | |
| T2 | 开始事务 | |
| T3 | 统计总存款数为10000元 | |
| T4 | 新增一个存款账户,存款为100元 | |
| T5 | 提交事务 | |
| T6 | 再次统计总存款数为10100元(幻象读) |
4.更新丢失:多个事务同时对一个事务进行更新时,后者会覆盖前者的更新
| 时间 | 取款事务A | 转账事务B |
|---|---|---|
| T1 | 开始事务 | |
| T2 | 开始事务 | |
| T3 | 查询账户余额为1000元 | |
| T4 | 查询账户余额为1000元 | |
| T5 | 汇入100元把余额改为1100元 | |
| T6 | 提交事务 | |
| T7 | 取出100元将余额改为900元 | |
| T8 | 撤销事务 | |
| T9 | 余额恢复为1000元(丢失更新) |
隔离级别:
下面看看四种隔离级别的比较:
| 隔离级别 | 读数据一致性 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|---|
| 未提交读(Read uncommitted) | 最低级别,只能保证不读取物理上损坏的数据 | 是 | 是 | 是 |
| 已提交读(Read committed) | 语句级 | 否 | 是 | 是 |
| 可重复读(Repeatable read) | 事务级 | 否 | 否 | 是 |
| 可序列化(Serializable) | 最高级别,事务级 | 否 | 否 | 否 |