模块的分类
1、什么是模块
模块就是一系列功能的集合体 模块大致分为四种类别: 1、一个py文件就是一个模块,文件名叫test.py,模块名叫test 2、一个包含有__init__.py文件的文件夹称之为包,包也是模块 3、使用C编写并链接到python解释器的内置模块 4、已被编译为共享库或DLL的C或C++扩展 模块的三种来源: 1、自带的模块 2、第三方模块:pip3 install requests 3、自定义的模块
2、为何要用模块
1、(自带的模块,第三方模块)拿来主义,提升开发效率
2、自定义模块 ---> 是为了解决代码冗余的问题
3、如何用模块
模块都是被导入使用的
以spam.py为例来介绍模块的使用:文件名为spam.py,模块名为spam
#spam.py print('from the spam.py') money=1000 def read1(): print('spam模块:',money) def read2(): print('spam模块') read1() def change(): global money money=0
模块的使用
import语句
要想在另外一个py文件中引用foo.py中的功能,需要使用import foo,首次导入模块会做三件事: 1、执行源文件代码 2、产生一个新的名称空间用于存放源文件执行过程中产生的名字 3、在当前执行文件所在的名称空间中得到一个名字foo,该名字指向新创建的模块名称空间,若要引用模块名称空间中的名字,需要加上该前缀,如下 加上spam.作为前缀就相当于指名道姓地说明要引用spam名称空间中的名字,所以肯定不会与当前执行文件所在名称空间中的名字相冲突,并且若当前执行文件的名称空间中存在money,
执行spam.read1()或spam.change()操作的都是源文件中的全局变量money
首次导入模块发生的事情
首次导入模块发生的事情 1、运行spam.py,创建一个模块的名称空间,将spam.py运行过程中产生的名字都丢到模块的名称空间中 2、在当前名称空间中得到一个名字,该名字是指向模块的名称空间
import spam # 导入模块spam import spam import spam # print(spam) # <module 'spam' from 'E:\PYTHON\pycharm project\project\day14\模块的使用1\spam.py'> # ps:后续的导入直接引用首次的导入的成功,不会重复执行spam.py,不会重复创建名称空间 print(spam.money) # 引用模块spam中变量money的值 print(spam.read1) # <function read1 at 0x00000267C1C2A0D0> print(spam.read2) # <function read2 at 0x00000267C1C2A310> print(spam.change) # <function change at 0x00000267C1C2A1F0> spam.read1() # 调用模块spam的read1()函数 spam.read2() # >>>: # spam模块 # spam模块: 1000 money = 2000 spam.change() print(money) # 2000 print(spam.money) # 0
导入规范
通常情况下所有的导入语句都应该写在文件的开头,然后分为三部分:
第一部分:先导入自带的模块
第二部分:导入第三方
第三部分:导入自定义的
import的其他用法(as)
import os,sys,re # 在一行导入,用逗号分隔开不同的模块 import spam as sm # 在当前位置为导入的模块起一个别名
from...import语句
form...import...与import语句基本一致 唯一不同的是 使用import spam导入模块后,引用模块中的名字都需要加上spam.作为前缀 而使用from sapm import money,read1,read2,change则可以在当前执行文件中直接引用模块spam中的名字 from spam import money print(money) # 1000 直接使用模块spam中的money ''' 无需加前缀的好处是使得我们的代码更加简洁, 坏处则是容易与当前名称空间中的名字冲突, 如果当前名称空间存在相同的名字, 则后定义的名字会覆盖之前定义的名字。 ''' money = 20 # 将来自于spam模块的money覆盖了 print(money) # 20 # 引用的是当前作用域的money
fom...import...的其他用法
# 起别名 from spam import money,read1,read2,change from spam import money as m,read1 as r1,read2 as r2,change as cg print(m) print(r1) print(r2) # from... import * from spam import * # 把spam中所有的名字都导入到当前执行文件的名称空间中,在当前位置直接可以使用这些名字 print(money) print(read1) print(read2) print(change)
__all__
模块的编写者可以在自己的文件中定义__all__变量用来控制*代表的意思
#spam.py print('from the spam.py') __all__=['money','read1'] # 该列表中所有的元素必须是字符串类型,每个元素对应spam.py中的一个名字 money=1000 def read1(): print('spam模块:',money) def read2(): print('spam模块') read1() def change(): global money money=0
循环导入问题
循环导入问题指的是在一个模块加载/导入的过程中导入另外一个模块,而在另外一个模块中又返回来导入第一个模块中的名字,
由于第一个模块尚未加载完毕,所以引用失败、抛出异常,究其根源就是在python中,同一个模块只会在第一次导入时执行其内部代码,
再次导入该模块时,即便是该模块尚未完全加载完毕也不会去重复执行内部代码
解决方案
# 方案一:导入语句放到最后,保证在导入时,所有名字都已经加载过 # 文件:m1.py print('正在导入m1') x='m1' from m2 import y # 文件:m2.py print('正在导入m2') y='m2' from m1 import x # 文件:run.py内容如下,执行该文件,可以正常使用 import m1 print(m1.x) print(m1.y) # 方案二:导入语句放到函数中,只有在调用函数时才会执行其内部代码 # 文件:m1.py print('正在导入m1') def f1(): from m2 import y print(x,y) x = 'm1' # 文件:m2.py print('正在导入m2') def f2(): from m1 import x print(x,y) y = 'm2' # 文件:run.py内容如下,执行该文件,可以正常使用 import m1 m1.f1()
注意:循环导入问题大多数情况是因为程序设计失误导致,上述解决方案也只是在烂设计之上的无奈之举,在我们的程序中应该尽量避免出现循环/嵌套导入,
如果多个模块确实都需要共享某些数据,可以将共享的数据集中存放到某一个地方,然后进行导入
模块的搜索路径优先级
模块其实分为四个通用类别
1、使用纯python代码编写的py文件 2、包含一系列模块的包 3、使用C编写并链接到Python解释器中的内置模块 4、使用C或C++编译的扩展模块
模块的搜索路径优先级为
1、内存中已经导入好的 2、内置 3、sys.path sys.path也被称为模块的搜索路径,它是一个列表类型
注意
列表中的每个元素其实都可以当作一个目录来看:在列表中会发现有.zip或.egg结尾的文件,
二者是不同形式的压缩文件,事实上Python确实支持从一个压缩文件中导入模块,
我们也只需要把它们都当成目录去看即可。
软件开发的目录规格
1、区分py文件的两种途径
一个python文件有两种用途: 1、被当主程序脚本执行 2、被当做模块导入
为了区别同一个文件的不同用途,每个py文件都内置了__name__变量,该变量在py文件被当做脚本执行时赋值为"__main__",在py文件被当做模块导入时赋值为模块名。 作为模块spam.py的开发者,可以在文件末尾基于__name__在不同应用场景下值的不同来控制文件执行不同的逻辑。
if __name__ == '__main__': # spam.py被当做脚本执行时运行的代码 pass else: # spam.py被当做模块时运行的代码 pass
2、软件开发目录规范
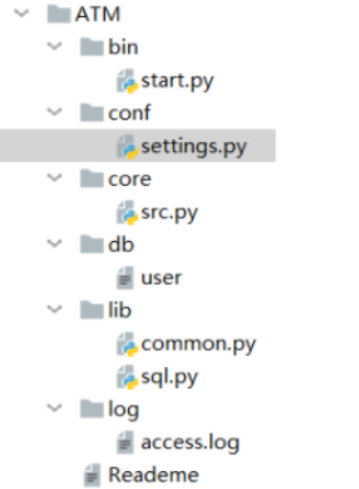
规范化开发: 一个py文件中:1、文件加载问题 2、代码可读性差,查询麻烦 要将一个py文件分开,合理的分成多个py文件 settings.py: 配置文件 就是放置一些项目中需要的静态参数,比如文件路径,数据库配置,软件的默认设置等 common.py: 公共组件文件 这里面放置一些我们常用的公共组件函数,并不是我们核心逻辑的函数,而更像是服务于整个程序中的公用的插件,程序中需要即调用。比如我们程序中的装饰器auth,有些函数是需要这个装饰器认证的,但是有一些是不需要装饰器认证的,它既是何处需要何处调用即可,比如还有密码加密功能,序列化功能,日志功能等这些功能都可以放在这里 src.py: 这个文件主要存放的就是核心逻辑功能,你看你需要进行选择的这些核心功能函数,都应该放在这个文件中 start.py: 项目启动文件,你的项目需要有专门的文件启动,而不是在你的核心逻辑部分启动的,目的就是放在显眼的位置,方便启动,start.py文件中引用sys模块,动态获取目录 类似于register文件: 这个文件文件名不固定,register只是我们项目中用到的注册表,但是这种文件就是存储数据的文件,类似于文本数据库,那么我们一些项目中的数据有的是从数据库中获取的,有些数据就是这种文本数据库中获取的,总之,你的项目中有时会遇到一些数据存储在文件中,与程序交互的情况,所以我们要单独设置这样的文件 log文件: log文件顾名思义就是存储log日志的文件,日志主要是供开发人员使用,比如你的项目中出现一些bug问题,比如开发人员对服务器做的一些操作都会记录到日志中,以便开发者浏览,查询。 设计一个层次清晰的目录结构,就是为了达到以下两点: 1、可读性高:不熟悉这个项目的代码的人,一眼就能看懂目录结构,直到程序启动脚本是哪个,测试目录在哪儿,配置在哪儿等,从而非常快速的了解这个项目 2、可维护性高:定义好组织规划后,维护者就能很明确的知道,新增的哪个文件和代码应该放在什么目录之下,这个好处是,随着时间的推移,代码配置的规模增加,项目结构不会混乱,仍然能够组织良好。
包的使用
包的介绍
随着模块数目的增多,把所有模块不加区分地放到一起也是极不合理的,于是Python为我们提供了一种把模块组织到一起的方法,即创建一个包。
包就是一个含有__init__.py文件的文件夹,文件夹内可以组织子模块或子包,例如

#1. 在python3中,即使包下没有__init__.py文件,import 包仍然不会报错,而在python2中,包下一定要有该文件,否则import 包报错 #2. 创建包的目的不是为了运行,而是被导入使用,记住,包只是模块的一种形式而已,包的本质就是一种模
包的使用
包属于模块的一种,因而包以及包内的模块均是用来被导入使用的,而绝非被直接执行,首次导入包(如import aaa): 1、执行包下的__init__.py文件 2、产生一个新的名称空间用于存放__init__.py执行过程中产生的名字 3、在当前执行文件所在的名称空间中得到一个名字aaa,该名字指向__init__.py的名称空间
强调
1、关于包相关的导入语句也分为import和from ... import ...两种,但是无论哪种,无论在什么位置,在导入时都必须遵循一个原则:
凡是在导入时带点的,点的左边都必须是一个包,否则非法。可以带有一连串的点,如import 顶级包.子包.子模块,但都必须遵循这个原则。
但对于导入后,在使用时就没有这种限制了,点的左边可以是包,模块,函数,类(它们都可以用点的方式调用自己的属性)。 2、包A和包B下有同名模块也不会冲突,如A.a与B.a来自俩个命名空间 3、import导入文件时,产生名称空间中的名字来源于文件,import 包,产生的名称空间的名字同样来源于文件,即包下的__init__.py,导入包本质就是在导入该文件
相对导入与绝对导入
绝对导入
""" 以顶级包为起始 """ from aaa import m1
相对导入
""" 代表当前文件所在的目录, .. 代表当前目录的上一级目录,依次类推 相对导入仅限于包的导入,相对导入不能出包 """ from . import m1
注意
针对包内部模块之间的相互导入推荐使用相对导入,需要特别强调: 1、相对导入只能在包内部使用,用相对导入不同目录下的模块是非法的 2、无论是import还是from-import,但凡是在导入时带点的,点的左边必须是包,否则语法错误
from 包 import *
在使用包时同样支持from pool.futures import * ,毫无疑问*代表的是futures下__init__.py中所有的名字,通用是用变量__all__来控制*代表的意思 #futures下的__init__.py __all__=['process','thread']
总结
1、导包就是在导入包下面的__init__.py文件 2、包内部的导入应该使用相对导入,相对导入也只能在包内部使用,而且...取上一级不能出包 3、使用语句中的 . 代表的是访问属性 m.n.x ---> 向m要n,向n 要 x 而导入语句中的 . 代表的是路径分隔符 import a.b.c ---> a/b/c,文件夹下a下有子文件夹b,文件夹下有子文件或文件夹c 所以导入语句中点的左边必须是一个包
常用模块的使用
详情参见:https://www.cnblogs.com/linhaifeng/articles/6384466.html