- 关于URL的一些基础内容
- URL模块的API解析
- URL的参数URLSearchParams类
- querystring模块
一、关于URL的一些基础内容
1.1 定义:
在WWW上,每一信息资源都有统一的且在网上唯一的地址,该地址就叫URL(Uniform Resource Locator,统一资源定位符),它是WWW的统一资源定位标志,就是指网络地址。
1.2 URL的组成部分:(以下面这个URL为例)
http://www.baidu.com:8080/news/index.asp?boardID=5&ID=24618&page=1#name
①协议部分:在双斜杠(//)前面的部分,示例中的协议部分是“http:”,在Internet中可以使用多种协议,如HTTP、FTP等。
②域名部分:例如示例中的“www.baidu.com”就是URL的域名部分。
③端口部分:端口部分不是URL的必须部分,在上面这个URL示例中包含有端口部分“8080”,端口与域名被冒号间隔开。
④虚拟目录部分:从URL中的第一个但斜杠(/)开始,到最后一个但斜杠(/),都是虚拟目录部分,示例中的“/news/”就是虚拟目录部分。
⑤文件名部分:最后一个但斜杠(/)后面就是文件名部分,有些URL没有参数和锚,文件名部分就会是URL的最后一个部分,这个示例中的文件名部分就是“index.asp”。
⑥参数部分:URL的参数部分是在问号(?)后面,如果URL没有有锚的话,参数就是URL的最后部分,这个示例中的参数部分是“boardID=5&ID=24618&page=1”。通常参数部分又被称为搜索部分、查询部分。
⑦锚部分:从井号(#)到最后,都是锚部分。示例中的锚部分是“name”
1.3 URL字符串与URL对象
在前面的URL组成分析中可以了解到URL的字符串类型,但是为了方便数据操作,通常需要在URL字符串与URL对象间进行转换。在node中存在两种转换方式,第一种是通过url模块上的url.parse(url)将URL字符串转换成URL对象;第二种是通过URL类的构造方式将URL字符串转换成URL对象。
需要注意的是url.parse()已被废弃,但目前不影响使用。URL类是基于HTML5标准中的WHATWG URL 标准实现实现的最新标准API。通过官方这张对比图来了解以下它们两者的异同:
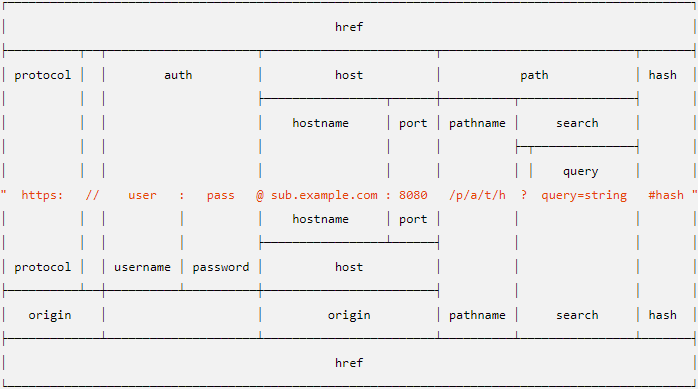
上方的是遗留的 url.parse() 返回的对象的属性。 下方的则是 WHATWG 的 URL 对象的属性。
通过对比可以看到,url.parse()生成的auth被username与password替代;并且新增了origin属性,还有一个细节需要注意,在新标准中取消了query属性。新版本还增加了一个URLSearchParams 类来解析URL字符串中的数据。
二、URL模块的API解析
2.1 new URL(input[,base])
通过URL字符串构造RUL对象。当URL字符串(input)是相对路径时,需要传入(base)以协议、主机地址、端口构成的基础地址。当然,如果RUL相对的是虚拟目录路径的话还需要相对的虚拟目录路径组成。
如果开启了国际化(ICU)模式,在构造时遇到Unicode字符时,将被使用Punycode算法自动转换成转换成ASCLL字符。
//解析相对的URL const myURL1 = new URL('/foo', 'https://example.org/'); //myURL1.href = https://example.org/foo //解析绝对的URL const myURL2 = new URL('https://example.org/foo/index.html'); //myURL2.href = https://example.org/foo/index.html //国际化解析带Unicode字符串的URL字符串 const myURL3 = new URL('https://测试'); //myURL3.href = https://xn--0zwm56d/
2.2 url.toString()
在url对象上调用toString()方法将返回序列化的URL。但是url.toString()由于不能自定义URL的序列化过程,实际上与rul.fref、url.toJSON()没什么区别。例如:
let urlM = require('url')
let url = new URL("https:127.0.0.1:12306/html/index.html?a=10&b=20");
console.log(url.href);
console.log(url.toString());
console.log(url.toJSON());
console.log(urlM.format(url));
//以上所有打印结果都是:https://127.0.0.1:12306/html/index.html?a=10&b=20
在上面的示例中有一个urlM.format()方法,这个方法也是用来实现URL对象序列化的方法,不过这个方法不是node内置类URL的方法,而是url模块的上的方法。
url模块上的format(URL[,options])可以通过options来配置自定义的URL序列化,自定义项分别有(默认值都为true,表示都包含):
auth<boolean>:是否包含用户名和密码;
fragment<boolean>:是否包含锚部分。
search<boolean>:是否包含参数部分(搜索查询部分)。
unicode<boolean>:是否将Unicode字符转换成ASCLL字符。
let urlM = require("url");
//示例一
let url = new URL('https://user:pass@sub.example.com:8080/p/a/t/h?query=string#hash');
console.log(url.href);
console.log(urlM.format(url,{auth:false,fragment:false,search:false}));
//打印结果
//https://user:pass@sub.example.com:8080/p/a/t/h?query=string#hash
//https://sub.example.com:8080/p/a/t/h
//示例二
const myURL = new URL('https://a:b@測試?abc#foo');
console.log(urlM.format(myURL, { fragment: false, unicode: true, auth: false }));
//打印结果:'https://測試/?abc'
在url.toString()的相关内容中,涉及到了rul.fref、url.toJSON()、url.format(URL[,options]),后面就不再对这些API重复解析了。
2.3 url.origin:获取只读的序列化的URL的orgin。(基本路径,包括:协议、身份信息、主机:域名+端口、IP+端口)
let url = new URL('https://user:pass@sub.example.com:8080/p/a/t/h?query=string#hash'); console.log(url.origin);//https://sub.example.com:8080
2.4 url.password:获取及设置URL的密码部分。
const myURL = new URL('https://abc:xyz@example.com'); console.log(myURL.password); // 打印 xyz myURL.password = '123'; console.log(myURL.href); // 打印 https://abc:123@example.com
2.5 url.pathname:获取及设置url的虚拟目录部分。
const myURL = new URL('https://example.org/abc/xyz?123'); console.log(myURL.pathname); // 打印 /abc/xyz myURL.pathname = '/abcdef'; console.log(myURL.href); // 打印 https://example.org/abcdef?123
2.6 url.port 获取及设置URL的端口部分。
端口值可以是数字或包含 0 到 65535(含)范围内的数字字符串。 将值设置为给定 protocol 的 URL 对象的默认端口将会导致 port 值变为空字符串('')。
端口为空字符串时,端口取决于协议/规范的默认端口。
2.7 url.protocol:获取及何止URL的协议部分。
const myURL = new URL('https://example.org'); console.log(myURL.protocol); // 打印 https: myURL.protocol = 'ftp'; console.log(myURL.href); // 打印 ftp://example.org/
2.8 url.search:获取及何止URL的序列化查询部分参数部分。
const myURL = new URL('https://example.org/abc?123'); console.log(myURL.search); // 打印 ?123 myURL.search = 'abc=xyz'; console.log(myURL.href); // 打印 https://example.org/abc?abc=xyz
2.9 url.searchParams:获取表示URL查询参数的URLSearchParams对象,该属性为只读。
关于url.searchParams详细见URLSearchParams类。
2.10 url.username:获取及设置URL的用户名部分。
const myURL = new URL('https://abc:xyz@example.com'); console.log(myURL.username); // 打印 abc myURL.username = '123'; console.log(myURL.href); // 打印 https://123:xyz@example.com/
2.11 url模块的一些其他方法:
url.fileURLToPath(url):用来将文件URL或URL对象转换成当前node所在系统对应的文件路径。


1 new URL('file:///C:/path/').pathname; // 错误: /C:/path/ 2 fileURLToPath('file:///C:/path/'); // 正确: C:path (Windows) 3 4 new URL('file://nas/foo.txt').pathname; // 错误: /foo.txt 5 fileURLToPath('file://nas/foo.txt'); // 正确: \nasfoo.txt (Windows) 6 7 new URL('file:///你好.txt').pathname; // 错误: /%E4%BD%A0%E5%A5%BD.txt 8 fileURLToPath('file:///你好.txt'); // 正确: /你好.txt (POSIX) 9 10 new URL('file:///hello world').pathname; // 错误: /hello%20world 11 fileURLToPath('file:///hello world'); // 正确: /hello world (POSIX)
url.pathToFileURL(path):用来将文件路径转换成文件URL路径。
1 new URL(__filename); // 错误: throws (POSIX) 2 new URL(__filename); // 错误: C:... (Windows) 3 pathToFileURL(__filename); // 正确: file:///... (POSIX) 4 pathToFileURL(__filename); // 正确: file:///C:/... (Windows) 5 6 new URL('/foo#1', 'file:'); // 错误: file:///foo#1 7 pathToFileURL('/foo#1'); // 正确: file:///foo%231 (POSIX) 8 9 new URL('/some/path%.js', 'file:'); // 错误: file:///some/path% 10 pathToFileURL('/some/path%.js'); // 正确: file:///some/path%25 (POSIX)
三、URL的参数URLSearchParams类
在网络请求中有get方法会直接将数据通过问好(?)间隔,将请求的查询数据直接拼接在请求地址后面,也就是URL的参数部分。有一些请求会直接采用手动拼接的方式直接在请求地址后面添加查询数据。
在URL类中有url.search来获取URL的参数部分,例如:
let url = new URL('https://user:pass@sub.example.com:8080/p/a/t/h?query=string#hash'); console.log(url.search);//?query=string
通过URL对象上search获取参数部分只是一个原始的字符串格式,并未对数据进行解析,这显然不是我们想要的。在URL对象中还有一个属性SearchParams属性,我们来看看这个属性得到的是,通过这个属性可以直接调用URLSearchParams类上的方法,可以理解为构造URL对象时给该属性添加了一个URLSearchParams构造对象。
let url = new URL('https://user:pass@sub.example.com:8080/p/a/t/h?query=string#hash'); console.log(url.searchParams.get("query"));//string
3.1 定义:URLSearchParams实例化的四种方式:
//1.构造一个空URLSearchParams()对象 let params1= new URLSearchParams(); //2.基于查询字符串构造URLSearchParams(string)对象 letparams2 = new URLSearchParams("a=10&b=abc&list=15&list=hello"); console.log(params2);//URLSearchParams { 'a' => '10', 'b' => 'abc', 'list' => '15', 'list' => 'hello' } //3.基于键值对集合构造URLSearchParams(object)对象 let params3 = new URLSearchParams({user: 'abc', query: ['first', 'second']}); console.log(params3);//URLSearchParams { 'user' => 'abc', 'query' => 'first,second' } //4.基于迭代对象构造URLSearchParams(iterable)对象 let params4 = new URLSearchParams([['user', 'abc'], ['query', 'first'], ['query', 'second']]); console.log(params4);//URLSearchParams { 'user' => 'abc', 'query' => 'first', 'query' => 'second' }
基于查询字符串构造URLSearchParams对象时,字符串开头可以带问号(?)。
基于键值对集合构造URLSearchParams对象时,传入的object每个属性的键和值都会被强制转化为字符串。
基于迭代对象构造URLSearchParams对象,类是Map的构造函数的迭代映射方式实例化一个新的对象。iterable可以是Array或者任何迭代对象。并且iterable本身也可以是任何迭代对象。
3.2 urlSearchParams.append(name,value):在查询字符串上添加一个新的键值对。
let params = new URLSearchParams("a=10&b=abc&list=15&list=hello"); params.append("c","['你','好']"); console.log(params.toString());//a=10&b=abc&list=15&list=hello&c=%5B%27%E4%BD%A0%27%2C%27%E5%A5%BD%27%5D
3.3 urlSearchParams.get(name):返回键是name的第一个键值对的值。如果没有该name名称的键则返回null。
let params = new URLSearchParams("a=10&b=abc&list=15&list=hello"); console.log(params.get("list"));//15
3.4 urlSearchParams.getAll(name):返回键是name的所有键值对,所有值被作为一个数组的项,将数组作为该键的值。如果没有该name名称的键则返回null。
let params = new URLSearchParams("a=10&b=abc&list=15&list=hello"); console.log(params.getAll("list"));//[ '15', 'hello' ]
3.5 urlSearchParams.has(name):如果name键存在则返回true。
let params = new URLSearchParams("a=10&b=abc&list=15&list=hello"); console.log(params.has("a"),params.has("b"),params.has("c"));//true true false
3.6 urlSearchParams.keys():返回一个键的ES6 Iterator对象。
let params = new URLSearchParams("a=10&b=abc&list=15&list=hello"); console.log(params.keys());//{ 'a', 'b', 'list', 'list' }
3.7 urlSearchParams.set(name,value):当name键不存在时添加键值对,当name键存在时则修改值。如果name键对应多个键值则修改第一个值为value,其他的删除。
let params = new URLSearchParams("a=10&b=abc&list=15&list=hello"); params.set("list","hhh"); console.log(params.keys());//{ 'a', 'b', 'list' }
3.8 urlSearchParams.sort():给键值对排序。
按现有名称就地排列所有的名称-值对。 使用稳定排序算法完成排序,因此保留具有相同名称的名称-值对之间的相对顺序。
该方法可以用来增加缓存命中。
const params = new URLSearchParams('query[]=abc&type=search&query[]=123'); params.sort(); console.log(params.toString()); // 打印 query%5B%5D=abc&query%5B%5D=123&type=search
3.9 urlSearchParams.toString():将查询参数对象序列化为查询参数字符串。必要时会存在百分号(%)编码字符(关于百分号编码字符可以了解这里:URL百分号编码)
let params = new URLSearchParams("a=10&b=abc&list=15&list=hello"); params.append("c","['你','好']"); console.log(params.toString());//a=10&b=abc&list=15&list=hello&c=%5B%27%E4%BD%A0%27%2C%27%E5%A5%BD%27%5D
3.10 urlSearchParams.values():将所有键的值作为一个迭代对象(Iterator)的整体返回。
let params = new URLSearchParams("a=10&b=abc&list=15&list=hello"); console.log(params.values());//URLSearchParams Iterator { '10', 'abc', '15', 'hello' }
3.11 urlSearchParams[Symbol.iterator]():基于URLSearchParams对象生成一个迭代对象,但是与其本身并没有多大区别,因为现在新版的平台都在Object原型上支持了迭代器。
const params = new URLSearchParams('foo=bar&xyz=baz'); console.log(params.entries());//URLSearchParams Iterator { [ 'foo', 'bar' ], [ 'xyz', 'baz' ] } console.log(params);//URLSearchParams { 'foo' => 'bar', 'xyz' => 'baz' } for (const [name, value] of params) { console.log(name, value); } // foo bar // xyz baz
3.12 url.domainToASCII(domain):将域名转换成ASCII编码格式。如果 domain 是无效域名,则返回空字符串
1 const url = require('url'); 2 console.log(url.domainToASCII('español.com')); 3 // 打印 xn--espaol-zwa.com 4 console.log(url.domainToASCII('中文.com')); 5 // 打印 xn--fiq228c.com 6 console.log(url.domainToASCII('xn--iñvalid.com')); 7 // 打印空字符串
3.13 url.domainToUnicode(domain):将ASCII编码格式的域名转换成Unicode编码格式。相当于url.domainToASCII(domain)的逆运算。
1 const url = require('url'); 2 console.log(url.domainToUnicode('xn--espaol-zwa.com')); 3 // 打印 español.com 4 console.log(url.domainToUnicode('xn--fiq228c.com')); 5 // 打印 中文.com 6 console.log(url.domainToUnicode('xn--iñvalid.com')); 7 // 打印空字符串
四、querystring模块
querystring模块同样也是用来解析URL的查询数据,相比urlSearchParams的固定模式解析,querystring模块主要用于解析自定义个查询参数格式的解析。
4.1 URL查询参数的百分号编码与解码:
1 let querystring = require("querystring"); 2 3 //将utf-8编码中包含的两个字节长度的字符转换成百分号编码(即URL编码)格式 4 let str1 = querystring.escape("a=用户名&b=密码"); 5 console.log(str1);//a%3D%E7%94%A8%E6%88%B7%E5%90%8D%26b%3D%E5%AF%86%E7%A0%81 6 7 //将百分号编码格式的查询参数转码成utf-8编码格式 8 let str2 = querystring.unescape(str1); 9 console.log(str2);//a=用户名&b=密码
通常情况下escape()和unescape()两个方法并不独立使用,而是在使用stringify()和parse()解析和封装URL的查询参数时使用,也就是说解析和封装URL查询参数的编码方法并不是内置,这也就意味可以自定义解析和封装的编码解码方法,从而实现一些加密功能。
4.2 URL查询参数的解析与封装:
1 let querystring = require("querystring"); 2 3 let str3 = querystring.stringify({ foo: 'bar', baz: ['qux', 'quux'], corge: '' }); 4 let str4 = querystring.parse(str3); 5 6 console.log(str3);//foo=bar&baz=qux&baz=quux&corge= 7 console.log(str4);//[Object: null prototype] { foo: 'bar', baz: [ 'qux', 'quux' ], corge: '' }
querystring.stringify()用来解析URL查询参数对象,从js的语法角度来说stringify()可以解析URLSearchParams对象,但是基于TS编写程序时会警告提示,由于TS能兼容js语法最终还是可以解析URLSearchParams对象。
querystring.parse()用来封装URL查询参数。这与URLSearchParams类的功能一致,当然URLSearchParams类也有自身的解析方法toString()。
相对于URLSearchParams类固定的操作URL查询参数的方法,querystring模块提供的解析与封装方法具备更多的灵活性,前面就有提到转码解码操作。其他详细来看下面的示例:
querystring.parse(str[, sep[, eq[, options]]]) //--将URL查询参数字符串解析封装成一个对象 //--str:URL查询参数字符串 //--sep:用来匹配分割每个键值对的符号,比如默认使用与符号(&)。 //--eq:用来匹配分割键与值的符号,比如默认使用等号(=)。 //--options<object>:{decodeURIComponent,maxKeys} //----decodeURIComponent:用来解析参数字符串百分号编码字符的方法,默认使用querystring.unescape()。 //-----maxKeys:用来指定解析参数字符串键的最大数量,默认值:1000。 querystring.stringify(obj[, sep[, eq[, options]]])//--将URL查询参数对象解析为查询参数字符串 //--obj:URL查询参数对象 //--sep:用来指定解析URL查询参数字符串间隔键值对的符号。默认使用与符号(&)。 //--eq:用来指定解析URL查询参数字符串间隔键与值的符号。默认使用等号(=)。 //--options<object>:{encodeURIComponent} //----encodeURIComponent:用来转码URL查询参数的编码,默认情况下使用querystring.escape()实现百分比编码。