- day02, 03
- 2.1.2 standalone 属性
- 2.2 xml 元素(Element)
- 2.3 xml 属性
- 2.4 xml 注释
- 2.5 CDATA区
- 2.6 转义字符
- 2.7 处理指令
- 3. xml 约束
- 4. XML 编程(CRUD)
day02, 03 XML
Author:相忠良
Email:ugoood at 163 dot com
起始于:March 7, 2018
最后更新日期:April 1, 2018
本笔记依据传智播客方立勋老师 Java Web 的授课视频内容记录而成,中间加入了自己的理解。本笔记目的是强化自己学习所用。若有疏漏或不当之处,请在评论区指出。谢谢。
1. xml语言和作用
XML = Extensible Markup Language = 可扩展标记语言。目前遵循W3C组织于2000年发布的 XML1.0 规范。
xml 作用就是用来描述关系数据(结构化数据),如下图那个样的数据:
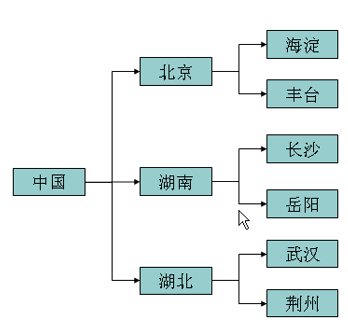
所以,xml 可用于保存关系数据,也经常用作软件配置文件,来描述程序模块之间的关系。
如下(内容在下节)。
2. xml语法详解
2.1 xml 语法声明
2.1.1 encoding 属性
建个config.xml文件,写入如下代码后, 用浏览器打开,以检查xml语法的正确性:
<?xml version="1.0" encoding="UTF-8"?>
<soft>
<a>
<a1>中国</a1>
<a2></a2>
</a>
<b>
<b1></b1>
<b2></b2>
</b>
</soft>
中国人面临的编码问题:
xml 声明为 utf-8, 但记事本默认保存为gb2312(os默认编码方式),所以浏览器无法正确解析(因为你写的xml文档已经声明让ie浏览器用utf-8方式去解析)。
注意将上面文件另存为encoding为utf-8模式保存,否则浏览器无法解析。若用eclipse工具不存在这样的问题(细节已自动处理)。
2.1.2 standalone 属性
其值可为 yes 和 no。 yes 代表该 xml 文档是独立的, no 代表是非独立,既依赖于别的文档,用浏览器应该不能直接打开。但ie浏览器不关注这个,依然能打开。
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
2.2 xml 元素(Element)
xml 元素 = xml 标签
写法:
含有标签体: <a>www.cnblogs.com/ZhongliangXiang/</a>
不含标签体: <a></a> 简写为 <a/>
必须只有一个根标签。
标签中出现的换行和空格,都会作为标签内容处理(用换行和空格使得文档内容清晰的习惯可能要被迫改变)!下面两段代码意义是不一样的:
<a>www.cnblogs.com/ZhongliangXiang/</a>
<a>
www.cnblogs.com/ZhongliangXiang/
</a>
2.3 xml 属性
一个标签可有多个属性,每个属性都有自己的名字。
XML 技术中,属性所代表的信息也可以用子元素的形式来描述,如:
<input name="text"></input>
<input>
<name>text</name>
</input>
2.4 xml 注释
方式:<!--注释-->
xml声明前不能有注释。
这不能写注释
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
2.5 CDATA区
把不希望 xml 引擎解析的内容放入 CDATA 区,而是当做原始内容直接输出:
做实验时注意encoding问题,把encoding改为"gb2312",或下面文件另存时更改编码方式为utf-8。
<?xml version="1.0" encoding="UTF-8"?>
<soft>
<![CDATA[
<a>
<a1>中国</a1>
<a2></a2>
</a>
]]>
<b>
<b1></b1>
<b2></b2>
</b>
</soft>
2.6 转义字符
原始样式给人看,用转义;
给程序看,用 CDATA。
| 特殊字符 | 替代符号 |
|---|---|
| & | & |
| < | < |
| > | > |
| " | " |
| ' | ' |
2.7 处理指令
简称PI(processing instruction), 用来指挥解析引擎如何解析XML文档内容。
如:xml中使用 xml-stylesheet 指令,通知xml解析引擎,应用某css文件显示xml文档内容。<?xml-stylesheet type="text/css" href="1.css"?>
我机器ie无法达到效果,而谷歌浏览器可以。
具体例子:
config1.xml:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/css" href="config1.css"?>
<soft>
<a>
<a1 id="a1">中国</a1>
<a2 id="a2">美国</a2>
</a>
<b>
<b1 id="b1">日本</b1>
<b2 id="b2">韩国</b2>
</b>
</soft>
再建一个 config1.css 文件,写入:
#a1{
font-size: 200px;
color: red;
}
#a2{
font-size: 150px;
color: blue;
}
#b1{
font-size: 100px;
color: green;
}
#b2{
font-size: 50px;
color: pink;
}
3. xml 约束
xml 技术里,可以编写一个文档来约束另外一个 xml 文档的书写规范,这称为 xml 约束。
为啥需要 xml 约束?
xml 文档通常作为程序配置文件来使用。 框架开发者需告诉该框架使用者如何编写 xml 文档,这就需要 xml 约束,通常是框架开发者写给框架使用者的。
框架设计者才需写 DTD 来约束使用框架的人。
常用的约束技术:
- xml DTD(Document Type Definition)
- xml Schema
3.1 xml DTD
DTD 文档应使用 utf-8 或 unicode 编码书写。
下图,左侧是 xml 文档,右侧是 dtd 约束文档。dtd 限制了左侧 xml 文档写法。

左图(书+)代表“书架”标签里可以有多个“书”标签。#PCDATA是 parse character data,可以认为是字符串的意思。
例子:
建立book.dtd文件:
<!ELEMENT 书架(书+)>
<!ELEMENT 书(书名,作者,售价)>
<!ELEMENT 书名 (#PCDATA)>
<!ELEMENT 作者 (#PCDATA)>
<!ELEMENT 售价 (#PCDATA)>
建立book.xml文件:
其中,<!DOCTYPE 书架SYSTEM "book.dtd">用来声明该 xml 文档遵循 book.dtd 约束。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE 书架 [
<!ELEMENT 书架(书+)>
<!ELEMENT 书(书名,作者,售价)>
<!ELEMENT 书名 (#PCDATA)>
<!ELEMENT 作者 (#PCDATA)>
<!ELEMENT 售价 (#PCDATA)>
]>
<书架>
<书>
<书名>Java培训教程</书名>
<作者>张三</作者>
<售价>39.00</售价>
</书>
<书>
<书名>JavaScript网页开发</书名>
<作者>李四</作者>
<售价>28.00</售价>
</书>
<!-- <a></a> ie 无法校验dtd约束,用eclipse则可以-->
</书架>
DTD 也可写在 xml 文档内部,如下:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE 书架 SYSTEM "book.dtd">
<书架>
<书>
<书名>Java培训教程</书名>
<作者>张三</作者>
<售价>39.00</售价>
</书>
<书>
<书名>JavaScript网页开发</书名>
<作者>李四</作者>
<售价>28.00</售价>
</书>
</书架>
3.2 引用 DTD 约束
- 当引用的文件在本地时,采用如下写法:
<!DOCTYPE 书架 SYSTEM "book.dtd">
它表示:书架及子标签将遵循 book.dtd 约束。 - 当引用的文件是一个公共的文件时,采用下面写法:
<!DOCTYPE 文档根节点 PUBLIC "DTD名称" "DTD文件的URL">
例如:
<!DOCTYPE web-app PUBLIC "-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN" "http://java.sun.com/dtd/web-app_2_3.dtd">
3.3 DTD约束语法细节
- 元素定义
- 属性定义
- 实体定义
3.4 元素定义
元素类型可为元素内容、或类型。
<!ELEMENT 元素名称 元素类型>
元素为内容,则用()括起来,如:
<!ELEMENT 书(书名,作者,售价)>
<!ELEMENT 书名 (#PCDATA)>
元素为类型,则直接写,DTD 有如下几种类型:
- EMPTY: 用于定义空元素, 如
<br/>或<hr/>; - ANY: 表元素可为任意类型。
如在 book.dtd 中,将第一句修改为:
<!ELEMENT 书架 ANY>
则书架可放任何标签,book.xml 在 eclipse 中也不会报错。
3.5 元素定义2

3.6 属性 attribute
在 DTD 中为标签定义属性。
在 DTD 中,通过 ATTLIST为标签定义属性。

属性定义的设置说明:
-
REQUIRED: 必须设置该属性
-
IMPLIED: 可设置也可不设置
-
FIXED: 固定某个值,且在xml中不能为该属性设置其他值
- 直接使用默认值: 在xml中若不设置该属性,则使用默认值
例子:
在book.dtd中加入如下内容:
<!ATTLIST 页面作者
姓名 CDATA #IMPLIED
年龄 CDATA #IMPLIED
联系信息 CDATA #REQUIRED
网站职务 CDATA #FIXED "页面作者"
个人爱好 CDATA "上网"
>
依据上面的 dtd 定义, 有一个新的 demo.xml 文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<?DOCTYPE 书架 SYSTEM "book.dtd">
<页面作者 联系信息="China"></页面作者>
“页面作者” 标签上面代码中眼睛看到只有1个属性,但实际上有3个属性,只不过其中2个属性:网站职务、个人爱好都有默认值了,且网站职务属性值不可由 xml 文档更改。
3.7 常用属性值类型
CDATA: 表属性值为普通文本字符串;ENUMERATEDIDENTITY(实体)
3.7.1 属性值类型 -> ENUMERATED(枚举)

练习解读上图代码的意思。
3.7.2 属性值类型 -> ID

练习解读上图代码的意思。
注意:我们以后会经常为某些数据配 ID,这个 ID 的值最好不要以数字开头!
3.7.3 属性值类型 -> ENTITY(实体)
实体用于为一段内容起个别名,类似于变量的概念。
实体分为:
- 引用实体 -- 引用实体在 dtd 中定义,用在
XML文档中; - 参数实体 -- 定义和使用都在 dtd 文档中。
引用实体:
引用实体在dtd中定义,用在 XML 文档中。
语法格式:<!ENTITY 实体名称 "实体内容">
引用方式:&实体名称
举例, 在某个 dtd 文件中有:
<!ENTITY copyright "I am a programmer">
......
©right
上述代码中,copyright可类比为变量名,©right则表示该变量的内容"I am a programmer"。
例子:
在book.dtd文件中加入<!ENTITY bookname "javaweb开发">,同时在 book.xml 中,加入<书名>&bookname;</书名>。我们用浏览器打开 book.xml,看到 &bookname会被替换成javaweb开发。
注:这个实验,我没做成功,好像现在的浏览器已经不支持引用实体了。
参数实体:
定义和使用都在 dtd 文档中,用处是简化书写,做到代码重用。

3.8 自检是否能读懂 DTD 文档
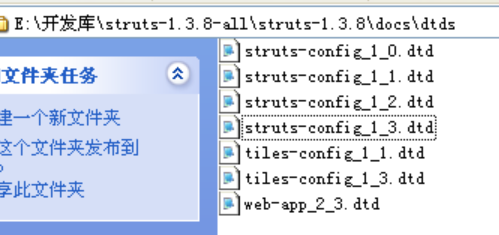
试着读上述图片所示的 struts2 的DTD文档。
3.9 DTD 案例
目的是验证自己是否能读懂 dtd 约束文档。
dtd文件来自:http://www.w3school.com.cn/dtd/dtd_examples.asp
且把那个 CATALOG 的 dtd 文档写入 下面新建的 CATALOG.xml 文件前面,如下:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE CATALOG [
<!ENTITY AUTHOR "John Doe">
<!ENTITY COMPANY "JD Power Tools, Inc.">
<!ENTITY EMAIL "jd@jd-tools.com">
<!ELEMENT CATALOG (PRODUCT+)>
<!ELEMENT PRODUCT
(SPECIFICATIONS+,OPTIONS?,PRICE+,NOTES?)>
<!ATTLIST PRODUCT
NAME CDATA #IMPLIED
CATEGORY (HandTool|Table|Shop-Professional) "HandTool"
PARTNUM CDATA #IMPLIED
PLANT (Pittsburgh|Milwaukee|Chicago) "Chicago"
INVENTORY (InStock|Backordered|Discontinued) "InStock">
<!ELEMENT SPECIFICATIONS (#PCDATA)>
<!ATTLIST SPECIFICATIONS
WEIGHT CDATA #IMPLIED
POWER CDATA #IMPLIED>
<!ELEMENT OPTIONS (#PCDATA)>
<!ATTLIST OPTIONS
FINISH (Metal|Polished|Matte) "Matte"
ADAPTER (Included|Optional|NotApplicable) "Included"
CASE (HardShell|Soft|NotApplicable) "HardShell">
<!ELEMENT PRICE (#PCDATA)>
<!ATTLIST PRICE
MSRP CDATA #IMPLIED
WHOLESALE CDATA #IMPLIED
STREET CDATA #IMPLIED
SHIPPING CDATA #IMPLIED>
<!ELEMENT NOTES (#PCDATA)>
]>
<!-- 下面是根据 dtd 文档写的 xml 文档 -->
<CATALOG>
<PRODUCT>
<SPECIFICATIONS>aaaa</SPECIFICATIONS>
<OPTIONS>bbbb</OPTIONS>
<PRICE>cccc</PRICE>
<NOTES>dddd</NOTES>
</PRODUCT>
</CATALOG>
上面代码里的 <PRICE>cccc</PRICE>, 表明 dtd 约束的劣势(dtd 会逐渐淘汰),即 dtd 无法详细约束数据类型(PRICE 应该是数字,但 dtd 无法提供这样的约束,这就需要另一种约束: Schema 约束。下节讲。)。
4. XML 编程(CRUD)
CRUD = Create, Read, Update, Delete
XML 编程:就是在XML文档里增、删、改、查数据,简称 CRUD。
4.1 XML 解析技术(DOM 和 SAX)概述及对比
xml 解析方式有两种:
- dom(Document Object Model) -- wec推荐的解析xml的方式;
- sax(Simple API for XML) -- xml 社区事实标准,所有解析器都支持它。
关于 dom 和 sax 这两种 xml 解析方式的解释,如下图:
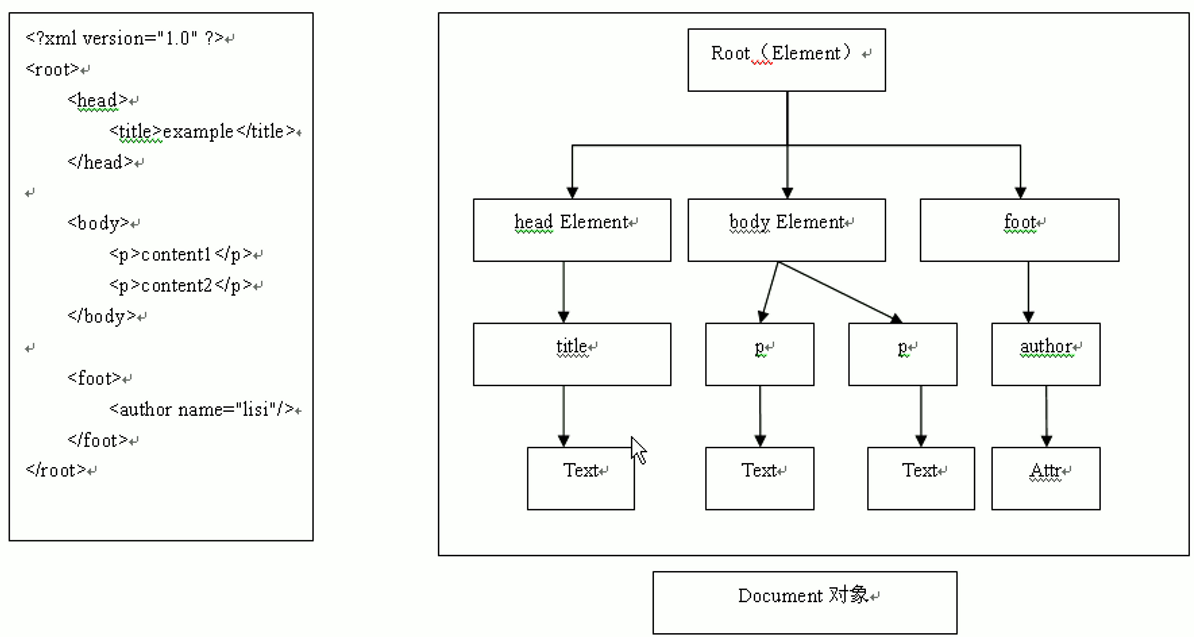
关于 dom 解析方式:
优点:方便地支持 cud,r 当然也没问题;缺点:需将整个 xml 整个文档所述内容以各种对象(如element对象,text对象,attribute对象)的形式存储在内存中,即不适合处理大 xml 文档,耗费内存多。
关于 sax 解析方式:
sax 以逐行读取的方式处理 xml 文档。优点:内存占用极少;缺点:不能 cud,只能 r。
4.2 调整 jvm 内存大小
动机:运行大文件或内容,超出 jvm 默认占用内存大小。
方法:
Eclipse 中,执行程序是选择 Run Configuration -> Arguments -> VM arguments 中填写-Xmx1024m,意为调整为1024m内存, 点 Run 运行即可。
4.3 XML 解析开发包(Jaxp(sun), Jdom, dom4j)
XML 解析包有 Jaxp(sun), Jdom, dom4j。性能上 dom4j 最优, Jaxp(sun) 最差但却是sun开发的,涉及到标准一类的事情。因此,我们要学习 dom4j 和 Jaxp(sun), 不学习 Jdom。
4.4 Jaxp
Jaxp 开发包是J2SE的一部分,创建工程后不需额外导入。它由javax.xml,org.w3c.dom和org.xml.sax包及其子包组成。
在javax.xml.parsers包中,定义了几个工厂类,程序员调用这些工厂类,可以得到 xml 文档的 DOM 或 SAX 的解析器,从而实现对xml文档的解析。
4.4.1 使用 Jaxp 进行 DOM 解析(读取)
就是用 javax.xml.parsers 包中的 DocumentBuilderFactory 创建 DOM 模式的解析器对象。完整过程例子如下:
材料准备-> 在项目的 src 目录下创建book.xml文档,内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<书架>
<书>
<书名 name="xxxx">Java培训教程</书名>
<作者>张三</作者>
<售价>39.00</售价>
</书>
<书>
<书名>JavaScript网页开发</书名>
<作者>李四</作者>
<售价>28.00</售价>
</书>
</书架>
建立Demo.java:
重点:4步
- 建工厂
- 获取dom解析器
- 获取document
- 用之
需求1:读取 <书名>JavaScript网页开发</书名> 中书名标签的值
// 使用dom方式对xml文档进行crud
public class Demo {
@Test
public void read1() throws Exception {
//1.创建工厂
DocumentBuilderFactory factory =
DocumentBuilderFactory.newInstance();
//2.得到 dom 解析器
DocumentBuilder builder = factory.newDocumentBuilder();
//3.解析 xml 文档,得到代表文档的 document
Document document = builder.parse("src/book.xml");
//4.使用该 document 做事情,举例如下:
NodeList list = document.getElementsByTagName("书名");
Node node = list.item(1);
String content = node.getTextContent();
System.out.println(content);
}
}
输出结果:
JavaScript网页开发
注意:dom解析下,xml 文档的每一个组成部分都会用一个对象表示,例如标签用Element, 属性用Attr,但不管什么对象,都是Node的子类,所以开发时可把获取的任意节点当作Node对待。
需求2:遍历 xml 文档中所有标签(Element)
// 需求:得到 xml 文档中所有标签
@Test
public void read2() throws Exception {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.parse("src/book.xml");
// 得到根节点
Node root = document.getElementsByTagName("书架").item(0);
list(root); // 递归找root下的孩子
}
private void list(Node node) {
if (node instanceof Element)
System.out.println(node.getNodeName());
NodeList children = node.getChildNodes();
for (int i = 0; i < children.getLength(); i++) {
Node child = children.item(i);
list(child);
}
}
输出结果:
书架
书
书名
作者
售价
书
书名
作者
售价
需求3:获取<书名 name="xxxx">Java程序设计</书名>中属性name的值
// 需求:获得 标签的属性值
@Test
public void read3() throws Exception {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.parse("src/book.xml");
// node 强转成 Element
Element bookname = (Element) document.getElementsByTagName("书名")
.item(0);
String value = bookname.getAttribute("name");
System.out.println(value);
}
4.4.2 使用 Jaxp 进行 DOM 解析(增删改)
本节基于book.xml文档做了些示例代码,book.xml文档如下:
<?xml version="1.0" encoding="UTF-8"?>
<书架>
<书>
<书名>Java培训教程</书名>
<作者>张三</作者>
<售价>39.00</售价>
</书>
<书>
<书名>JavaScript网页开发</书名>
<作者>李四</作者>
<售价>28.00</售价>
</书>
</书架>
增删改花10多分钟学习下下面代码就行了:
// 向 xml 文档添加节点:<售价>59.00元</售价>
@Test
public void add1() throws Exception {
// 获取 document 对象
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.parse("src/book.xml");
// 1.创建节点
Element price = document.createElement("售价");
price.setTextContent("59.00元");
// 2.把创建的节点挂在第1本书上
Element book = (Element) document.getElementsByTagName("书").item(0);
book.appendChild(price);
// 3.把更新后的内存对象 document 写回到 xml 文档
TransformerFactory tf_factory = TransformerFactory.newInstance(); // 建transformer工厂
Transformer tf = tf_factory.newTransformer(); // 获得转换器
tf.transform(new DOMSource(document), new StreamResult(
new FileOutputStream("src/book.xml"))); // 注意 源 和 目地 的写法
}
// 向 xml 文档指定位置添加节点:<售价>59.00元</售价>
@Test
public void add2() throws Exception {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.parse("src/book.xml");
// 1.创建节点
Element price = document.createElement("售价");
price.setTextContent("59.00元");
// 2.获得参考节点
Element ref = (Element) document.getElementsByTagName("售价").item(0);
// 3.获得欲插入崽的节点
Element book = (Element) document.getElementsByTagName("书").item(0);
// 4.插入参考节点的前面
book.insertBefore(price, ref);
// 5.更新 xml 文档
TransformerFactory tf_factory = TransformerFactory.newInstance();
Transformer tf = tf_factory.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(
new FileOutputStream("src/book.xml")));
}
// 向 xml文档指定标签添加属性:<书名>Java培训教程</书名> 添加name="xxxx"属性
@Test
public void addArr() throws Exception {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.parse("src/book.xml");
// 1.获得节点
Element book_name = (Element) document.getElementsByTagName("书名").item(
0);
// 2.添加属性
book_name.setAttribute("name", "xxxx");
// 3.更新 xml 文档
TransformerFactory tf_factory = TransformerFactory.newInstance();
Transformer tf = tf_factory.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(
new FileOutputStream("src/book.xml")));
}
// 删除指定节点:<售价>59.00</售价>
@Test
public void delete() throws Exception {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.parse("src/book.xml");
// 1.获得要删除的节点
Element price = (Element) document.getElementsByTagName("售价").item(0);
// 2.通过儿子找爸爸
Element book = (Element) price.getParentNode();
// 3.调用爸爸删崽
book.removeChild(price);
// 4.更新 xml 文档
TransformerFactory tf_factory = TransformerFactory.newInstance();
Transformer tf = tf_factory.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(
new FileOutputStream("src/book.xml")));
}
// 更新售价:<售价>59.00</售价> -> <售价>109.00</售价>
@Test
public void update() throws Exception {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.parse("src/book.xml");
// 1.获得要更新的节点
Element price = (Element) document.getElementsByTagName("售价").item(0);
// 2.更新价格
price.setTextContent("109.00");
// 3.更新 xml 文档
TransformerFactory tf_factory = TransformerFactory.newInstance();
Transformer tf = tf_factory.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(
new FileOutputStream("src/book.xml")));
}
4.5 用xml作为持久化设备实现考生成绩管理系统的分析--众多项目为什么设置UI,dao,XmlUtils,domain包的解释
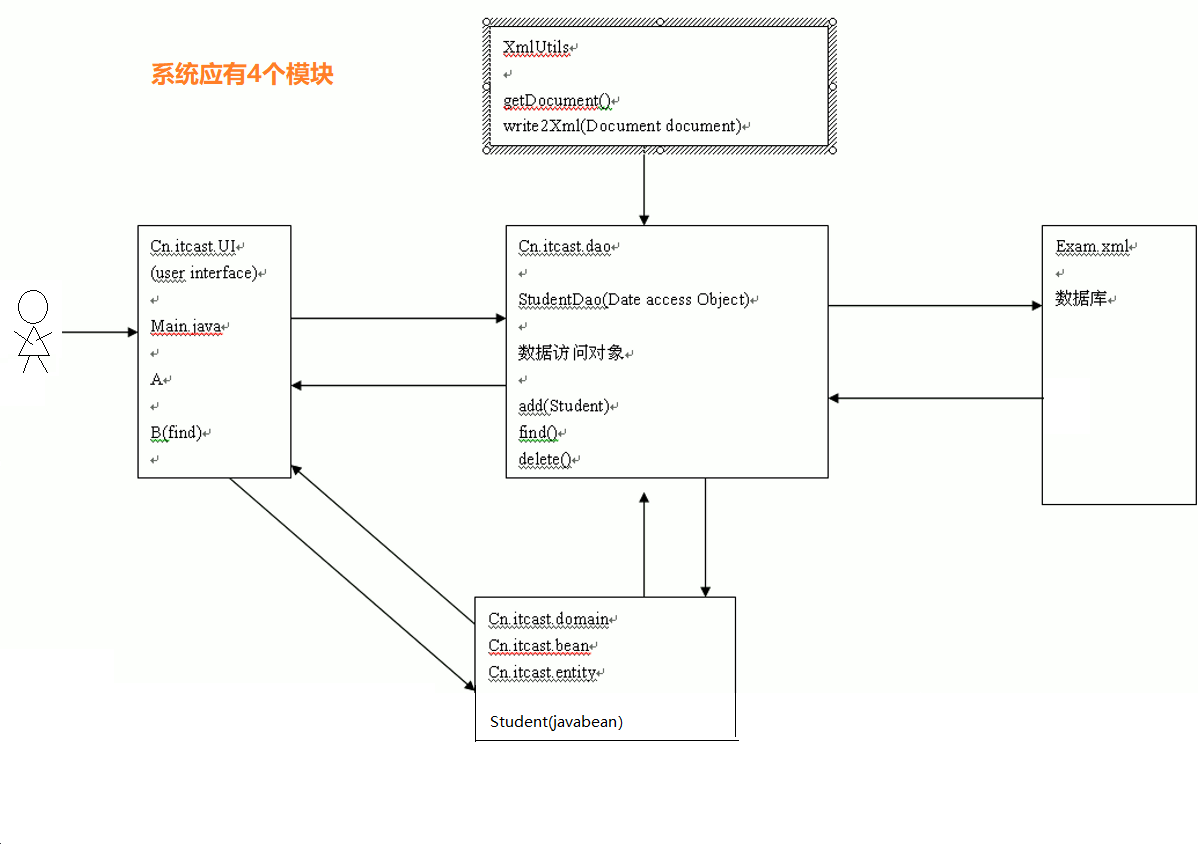
上图所示,该系统大体应有四个模块:
domain:依据需求建立项目所需的基本对象模板(习惯用的包名为:domain, bean, entity);dao: 用于数据对象访问, 这个例子中用来对 xml 文档进行 crud 操作;Uitls: Xml工具包,作为辅助;UI: 用户交互界面。
在实际操作中,发现还需建立以下包:
5. exception: 用于存放自定义异常类;
6. junit.test: 用于对 dao 包中的类的方法进行测试;
项目所用到的 xml 文档命名为exam.xml,初始内容如下(已有2个学生):
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<exam>
<student idcard="111" examid="222">
<name>张三</name>
<location>沈阳</location>
<grade>89</grade>
</student>
<student idcard="333" examid="444">
<name>李四</name>
<location>大连</location>
<grade>97</grade>
</student>
</exam>
(重要)该项目编写顺序大体如下:
domain -> dao -> UI
但在编写 dao 时,需建立 utils 包并建立 XmlUtils 类,用以简化 dao 内代码的书写。
同时,在写 dao 的时候,需根据需要建立自定义异常类(在 exception)包中。
编写完 dao 后,必须对 dao 做测试,所以又建立了 junit.test 包以及该包中建立测试类。
本项目难点是体会建立异常以及如何处理异常,是抛还是处理异常,怎么处理异常的问题。我们需仔细体会,弄清楚为什么那样做。
4.5.1 cn.wk.domain代码
package cn.wk.domain;
public class Student {
private String idcard;
private String examid;
private String name;
private String location;
private double grade;
// alt+shift+s 生成 get set 方法
public String getIdcard() {
return idcard;
}
public void setIdcard(String idcard) {
this.idcard = idcard;
}
public String getExamid() {
return examid;
}
public void setExamid(String examid) {
this.examid = examid;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getLocation() {
return location;
}
public void setLocation(String location) {
this.location = location;
}
public double getGrade() {
return grade;
}
public void setGrade(double grade) {
this.grade = grade;
}
}
4.5.2 cn.wk.utils代码
package cn.wk.utils;
import java.io.FileOutputStream;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.w3c.dom.Document;
//工具类
public class XmlUtils {
private static String filename = "src/exam.xml";
public static Document getDocument() throws Exception {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
return builder.parse(filename);
}
public static void write2Xml(Document document) throws Exception {
TransformerFactory factory = TransformerFactory.newInstance();
Transformer tf = factory.newTransformer();
tf.transform(new DOMSource(document), new StreamResult(
new FileOutputStream(filename)));
}
}
4.5.3 cn.wk.dao代码(同时还需编写处理异常的代码,在cn.wk.exception包中)
package cn.wk.dao;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.NodeList;
import cn.wk.domain.Student;
import cn.wk.exception.StudentNotExistException;
import cn.wk.utils.XmlUtils;
public class StudentDao {
public void add(Student s) {
// 这是 checked 异常(编译时异常)
// 为避免给上一层带麻烦,将此异常转型为unchecked异常(运行时异常)
try {
Document document = XmlUtils.getDocument();
// 创建封装学生的标签
Element student_tag = document.createElement("student");
student_tag.setAttribute("idcard", s.getIdcard());
student_tag.setAttribute("examid", s.getExamid());
// 创建用于封装学生姓名、所在地和成绩的标签
Element name_tag = document.createElement("name");
Element location_tag = document.createElement("location");
Element grade_tag = document.createElement("grade");
name_tag.setTextContent(s.getName());
location_tag.setTextContent(s.getLocation());
grade_tag.setTextContent(s.getGrade() + "");
student_tag.appendChild(name_tag);
student_tag.appendChild(location_tag);
student_tag.appendChild(grade_tag);
// 把封装了信息的学生标签,挂到document上
document.getElementsByTagName("exam").item(0)
.appendChild(student_tag);
// 更新内存
XmlUtils.write2Xml(document);
} catch (Exception e) {
throw new RuntimeException(e);
}
}
public Student find(String examid) {
try {
Document document = XmlUtils.getDocument();
NodeList list = document.getElementsByTagName("student");
for (int i = 0; i < list.getLength(); i++) {
Element student_tag = (Element) list.item(i);
if (student_tag.getAttribute("examid").equals(examid)) {
// 找到与 examid 相匹配的学生
Student s = new Student();
s.setExamid(examid);
s.setIdcard(student_tag.getAttribute("idcard"));
s.setGrade(Double.parseDouble(student_tag
.getElementsByTagName("grade").item(0)
.getTextContent()));
s.setLocation(student_tag.getElementsByTagName("location")
.item(0).getTextContent());
s.setName(student_tag.getElementsByTagName("name").item(0)
.getTextContent());
return s;
}
}
return null;
} catch (Exception e) {
throw new RuntimeException(e);
}
}
public void delete(String name) throws StudentNotExistException {
try {
Document document = XmlUtils.getDocument();
NodeList list = document.getElementsByTagName("name");
for (int i = 0; i < list.getLength(); i++) {
if (list.item(i).getTextContent().equals(name)) {
Element parent = (Element) list.item(i).getParentNode();
parent.getParentNode().removeChild(parent);
XmlUtils.write2Xml(document);
return;
}
}
// 学生不存在,这是应抛一个自定义的 编译时异常
throw new StudentNotExistException(name + "不存在!!");
} catch (StudentNotExistException e) {
throw e;
} catch (Exception e) {
// TODO Auto-generated catch block
throw new RuntimeException(e);
}
}
}
4.5.4 cn.wk.exception异常处理代码(与 dao 相关的)
下面代码,根据需求,将 StudentNotExistException 建成了Exceptinon异常(编译时异常 or called "checked exception"), 而不是RuntimeException异常(运行时异常 or named "unchecked exception")。
package cn.wk.exception;
// checked Exception
public class StudentNotExistException extends Exception {
public StudentNotExistException() {
// TODO Auto-generated constructor stub
}
public StudentNotExistException(String message) {
super(message);
// TODO Auto-generated constructor stub
}
public StudentNotExistException(Throwable cause) {
super(cause);
// TODO Auto-generated constructor stub
}
public StudentNotExistException(String message, Throwable cause) {
super(message, cause);
// TODO Auto-generated constructor stub
}
public StudentNotExistException(String message, Throwable cause,
boolean enableSuppression, boolean writableStackTrace) {
super(message, cause, enableSuppression, writableStackTrace);
// TODO Auto-generated constructor stub
}
}
4.5.5 junit.test包
junit.test包,用于测试 dao 中的类的方法。其中,在对testFind()的测试中,用到了断点,用于查看dao.find()的返回值内容,用以验证该方法的正确性。
package junit.test;
import org.junit.Test;
import cn.wk.dao.StudentDao;
import cn.wk.domain.Student;
import cn.wk.exception.StudentNotExistException;
public class StudentDaoTest {
@Test
public void testAdd() {
StudentDao dao = new StudentDao();
Student s = new Student();
s.setExamid("121");
s.setGrade(89);
s.setIdcard("121");
s.setLocation("北京");
s.setName("aa");
dao.add(s);
}
@Test
public void testFind() {
StudentDao dao = new StudentDao();
dao.find("121"); // 此处设为断点
// 然后点debug as,然后选中dao.find("121")右键点击watch
// 观察后再点红色方框结束,再在Breakpoints选项卡处清除断点并切换回java视图
}
@Test
public void testDelete() throws StudentNotExistException {
StudentDao dao = new StudentDao();
// dao.delete("xxxxxxxxx"); // 不存在的名字,应抛异常
dao.delete("aa");
}
}
4.5.6 cn.wk.ui包,此包中的类最后写
重点:UI(用户界面程序) 不能再抛异常了,必须抓起异常,后台作记录并给用户友好提示!!!
通常来说,ui中的异常,必须抓起,然后处理。处理的步骤大致有以下2步:
- 首先,必须要让后台记录异常:日志记录器,便于日后迭代修正程序(对能预知的事件,不记录,但仍然要给用户友好提示。如当用户删除的学生不存在时,发生异常,但后台不需记录该事件。);
- 其次,给用户友好的提示。
下面代码中,注意用于读取键盘的字节流 br.readLine()的用法。
package cn.wk.ui;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import cn.wk.dao.StudentDao;
import cn.wk.domain.Student;
import cn.wk.exception.StudentNotExistException;
public class Main {
// 重点:UI(用户界面程序) 不能再抛异常了,必须抓起异常,后台作记录并给用户友好提示!!!
public static void main(String[] args) {
try {
System.out.println("添加学生:(a) 删除学生:(b) 查找学生:(c)");
System.out.print("请输入操作类型: ");
// 读键盘
BufferedReader br = new BufferedReader(new InputStreamReader(
System.in));
// 重要:这是用户层,不能再抛了,再抛拿不到钱了。
String type = br.readLine();
if ("a".equals(type)) {
System.out.print("请输入学生姓名: ");
String name = br.readLine();
System.out.print("请输入学生准考证号: ");
String examid = br.readLine();
System.out.print("请输入学生身份证号: ");
String idcard = br.readLine();
System.out.print("请输入学生所在地: ");
String location = br.readLine();
System.out.print("请输入学生成绩: ");
String grade = br.readLine();
Student s = new Student();
s.setExamid(examid);
s.setGrade(Double.parseDouble(grade));
s.setIdcard(idcard);
s.setLocation(location);
s.setName(name);
StudentDao dao = new StudentDao();
dao.add(s); // 虽不报编译异常,但add可能抛运行时异常
System.out.println("添加成功!");
} else if ("b".equals(type)) {
System.out.print("请输入要删除的学生的姓名: ");
String name = br.readLine();
try {
StudentDao dao = new StudentDao();
dao.delete(name);
System.out.println("学生 " + name + " 删除成功!");
} catch (StudentNotExistException e) {
// 不需要记录该异常,只记录意料不到的才记录
System.out.println("您要删除的用户不存在!!");
}
} else if ("c".equals(type)) {
System.out.print("请输入要查找的学生的准考证号: ");
String examid = br.readLine();
StudentDao dao = new StudentDao();
Student s = dao.find(examid);
if (s != null) {
System.out.println("===========================");
System.out.println("已找到准考证号为 " + examid + " 的学生,其信息为:");
System.out.println("准考证号: " + s.getExamid());
System.out.println("身份证号: " + s.getIdcard());
System.out.println("姓名: " + s.getName());
System.out.println("成绩: " + s.getGrade());
System.out.println("所在地: " + s.getLocation());
System.out.println("===========================");
} else {
System.out.println("准考证号为 " + examid + " 的学生不存在!");
}
} else {
System.out.println("不支持您的操作!!");
}
} catch (Exception e) {
e.printStackTrace(); // 1. 后台记录异常:日志记录器,便于日后迭代修正程序
System.out.println("对不起,俺出错了!!"); // 2. 给用户友好提示
}
}
}
4.6 SAX 解析
在使用DOM解析XML文档时,需读取整个 XML 文档,在内存中构架代表整个 DOM 树的 Document 对象, 从而再对 XML 文档进行操作。此种情况下,如果 XML 文档特别大,就会消耗计算机大朗内存,且易导致内存溢出。
SAX 解析允许在读文档的时候,就对文档进行处理,而不必等到整个文档加载完才对文档进行操作。
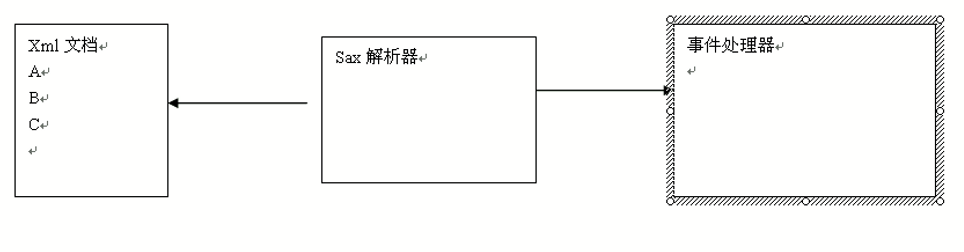
SAX解析:
SAX采用事件处理的方式解析XML文档,涉及2个部分:解析器 + 事件处理器:
- 解析器可由 jaxp 的 API 创建,创建出 SAX 解析器后,就可以指定解析器去解析某 XML 文档;
- 解析器采用SAX方式在解析某XML文档时,它只要解析到XML文档的一个组成部分,都会去调用事件处理器的一个方法,解析器在调用时间处理的方法时,会把当前解析到的xml文件内容作为方法的参数传递给时间处理器;
- 事件处理器由程序员编写,程序员通过事件处理器中方法的参数,就可以得到sax解析器解析到的数据,从而可以决定如何对数据进行处理。
如下图所示:
官网对SAX解析的示意图,如下:
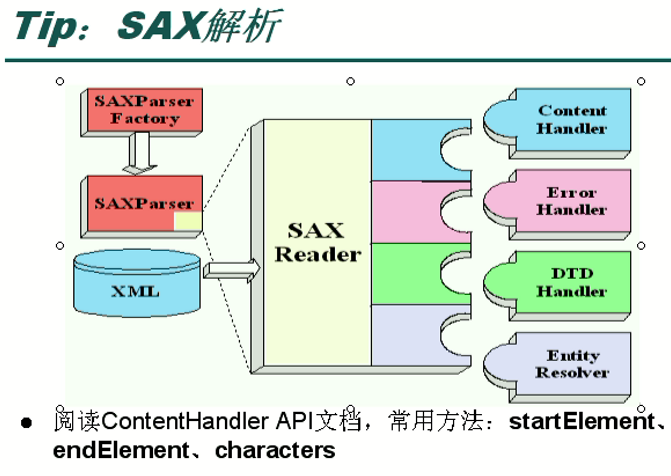
其中,由工厂SAXParserFactory生成的SAXParser解析器,并由该解析器搞出了SAXReader,由这个SAXReader去解析 xml 文档(这和DOM解析是不同的)。在SAXReader中,对应着4个事件处理器,其中ContentHandler是内容处理器,也是我们最应该关注的。
ContentHandler中常用方法为:开始标签startElement(),结束标签endElement(),标签内容characters()。
sax示例:
需求1:用 sax 解析方式向控制台输出 book.xml 的内容。
材料:book.xml文件
建立新工程,将 book.xml 放入 src 目录,建立 Demo1 类,并加入 main 函数,Demo1 类代码如下:
public class Demo1 {
/**
* sax 解析 xml 文档
*
* @throws SAXException
* @throws ParserConfigurationException
* @throws IOException
*/
public static void main(String[] args) throws ParserConfigurationException,
SAXException, IOException {
// 1.创建解析工厂
SAXParserFactory factory = SAXParserFactory.newInstance();
// 2.得到解析器
SAXParser sp = factory.newSAXParser();
// 3.得到读取器
XMLReader reader = sp.getXMLReader();
// 4.设置内容处理器
reader.setContentHandler(new ListHandler()); // 假设只关心内容
// 5.读取 xml 文档内容
reader.parse("src/book.xml");
}
}
当上面代码所示的读取器读取到xml文档的内容时,需预先设置好内容处理器,做相应处理。
内容处理器由程序员编写。如当读取器读到起始标签(如 <a>)时要做什么,读到标签内容字符串时要做什么,读到结束标签(如 </a>)时要做什么。
需求为列出book.xml文档内容,我们为此目的创建一个名为ListHandler的处理器,该处理器实现了ContentHandler接口,并且,因为需求,导致我们只关心ContentHandler接口中startElement()、 characters() 和 endElement()的实现即可!
ListHandler代码如下:
// 得到 xml 文档所有内容
class ListHandler implements ContentHandler {
// 读取器读取到开始标签时要调用的方法
@Override
public void startElement(String uri, String localName, String qName,
Attributes atts) throws SAXException {
// 获取标签
System.out.println("<" + qName + ">");
// 获取属性
for (int i = 0; atts!=null && i < atts.getLength(); i++) {
String attName = atts.getQName(i);
String attValue = atts.getValue(i);
System.out.println(attName + "=" + attValue);
}
}
// 读取器读到内容时要调用的方法
@Override
public void characters(char[] ch, int start, int length)
throws SAXException {
System.out.println(new String(ch, start, length));
}
// 读取器读到结束标签时要调用的方法
@Override
public void endElement(String uri, String localName, String qName)
throws SAXException {
System.out.println("<" + qName + ">");
}
// 其他已覆盖的方法,只写了方法体,没实际内容,因篇幅限制,就不列出了
}
需求2:获取指定标签值,如获得作者标签里的值
此时,只需改变处理器。我们建立新的处理器TagValueHandler,继承 DefaultHandler类,而不是实现ContentHandler接口。 DefaultHandler类是java自带的,已经实现了ContentHandler接口。我们只需覆盖DefaultHandler类中某些方法即可,简化了代码。
代码如下:
// 获取指定标签值,如获得作者标签里的值,并只想获得第一个作者标签的内容
class TagValueHandler extends DefaultHandler {
private String currentTag; // 记录当前解析到的是什么标签
private int needNumber = 2; // 只想获得第几个作者标签的值
private int currentNumber; // 表示当前解析到第几个作者标签
@Override
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
currentTag = qName; // 记录标签名
if(currentTag.equals("作者")){
currentNumber++;
}
}
@Override
public void characters(char[] ch, int start, int length)
throws SAXException {
if ("作者".equals(currentTag) && currentNumber == needNumber) {
System.out.println(new String(ch, start, length));
}
}
@Override
public void endElement(String uri, String localName, String qName)
throws SAXException {
currentTag = null; // 将标签名置空,方便下一次读取标签名
}
}
上述代码编写起来感觉很绕,原因是我们编写的处理器需配合 sax 解析器工作(我们写的处理器代码由人家 sax 解析器来调),而不像 dom 解析中获得整个
document所代表的对象树后,我们可自主操作那个对象树(自己调自己的代码)。
4.6.1 sax解析案例(javabean封装xml文档数据,人家都这么干)
需求:用sax解析,把在book.xml中查询到的书封装成Book对象
建立2个java文件,包括3个类。
Demo2.java 如下:
package cn.wk.sax;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.parsers.SAXParser;
import javax.xml.parsers.SAXParserFactory;
import org.xml.sax.Attributes;
import org.xml.sax.SAXException;
import org.xml.sax.XMLReader;
import org.xml.sax.helpers.DefaultHandler;
public class Demo2 {
/**
* sax 解析 xml 文档
*
* @throws SAXException
* @throws ParserConfigurationException
* @throws IOException
*/
public static void main(String[] args) throws ParserConfigurationException,
SAXException, IOException {
// 1.创建解析工厂
SAXParserFactory factory = SAXParserFactory.newInstance();
// 2.得到解析器
SAXParser sp = factory.newSAXParser();
// 3.得到读取器
XMLReader reader = sp.getXMLReader();
// 4.设置内容处理器
BeanListHandler handle = new BeanListHandler();
reader.setContentHandler(handle); // 假设只关心内容
// 5.读取 xml 文档内容
reader.parse("src/book.xml");
@SuppressWarnings("unchecked")
List<Book> list = handle.getBooks();
System.out.println(list);
}
}
// 把xml文档中的每一本书封装到一个book对象,并把多个book对象放在一个list集合中返回
class BeanListHandler extends DefaultHandler {
private List list = new ArrayList();
private String currentTag;
private Book book;
@Override
public void startElement(String uri, String localName, String qName,
Attributes attributes) throws SAXException {
currentTag = qName;
if ("书".equals(currentTag)) {
book = new Book();
}
}
@Override
public void characters(char[] ch, int start, int length)
throws SAXException {
if ("书名".equals(currentTag)) {
String name = new String(ch, start, length);
book.setName(name);
}
if ("作者".equals(currentTag)) {
String author = new String(ch, start, length);
book.setAuthor(author);
}
if ("售价".equals(currentTag)) {
String price = new String(ch, start, length);
book.setPrice(price);
}
}
@Override
public void endElement(String uri, String localName, String qName)
throws SAXException {
if (qName.equals("书")) {
list.add(book);
book = null;
}
currentTag = null;
}
public List getBooks() {
return list;
}
}
Book.java如下:
// Book.java
package cn.wk.sax;
public class Book {
private String name;
private String author;
private String price;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public String getPrice() {
return price;
}
public void setPrice(String price) {
this.price = price;
}
}
通过设置断点查看main()中List<Book> list = handle.getBooks();里list中存的书,做验证。
4.7 DOM4J 解析 XML 文档
dom4j不是sun公司的产品,它是一个开源项目,所以需将dom4j的开发包导入到项目中。dom4j下载地址 https://dom4j.github.io/
根据工程环境选择版本,我们选择了2005年发布的dom4j-1.6.1版本。把下载的包解压后,将该包变成奶瓶,导入自己的项目里。操作如下:
- myEclipse2014环境下,右击自己的项目建立名为
lib的文件夹; - 将
dom4j-1.6.1.jar放入lib文件夹; - 右击
lib中的dom4j-1.6.1.jar,选择build path将该包变成奶瓶即可。
关于dom4j的快速入门介绍在所下载的包的docs文件夹里的index.html中找 Quick start 即可。
实验材料 book.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<书架>
<书>
<书名>Java培训教程</书名>
<作者>张三</作者>
<售价>39.00</售价>
</书>
<书>
<书名 name = "xxx">JavaScript网页开发</书名>
<作者>李四</作者>
<售价>28.00</售价>
</书>
</书架>
下面代码解决了2个需求,如下:
package cn.wk.dom4j;
import java.io.File;
import java.io.FileOutputStream;
import org.dom4j.Document;
import org.dom4j.Element;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.SAXReader;
import org.dom4j.io.XMLWriter;
import org.junit.Test;
public class Demo1 {
// 需求1:用dom4j读取book.xml第二本书的<书名>JavaScript网页开发</书名>
// 并获取第二本书的属性值
@Test
public void read() throws Exception {
SAXReader reader = new SAXReader();
Document document = reader.read(new File("src/book.xml"));
Element root = document.getRootElement();
Element book = (Element) root.elements("书").get(1);
// 获得第二本书的<书名>JavaScript网页开发</书名>的内容
String value = book.element("书名").getText();
System.out.println(value);
// 获得第二本书的属性值
String att = book.element("书名").attributeValue("name");
System.out.println(att);
}
// 需求2: 向第一本书再添加售价
@Test
public void add() throws Exception {
SAXReader reader = new SAXReader();
Document document = reader.read(new File("src/book.xml"));
Element book = document.getRootElement().element("书");
book.addElement("售价").setText("208元");
// 更新内存
// xml的encoding是什么类型, 格式化输入器就用什么码表
OutputFormat format = OutputFormat.createPrettyPrint();
format.setEncoding("UTF-8");
XMLWriter writer = new XMLWriter(new FileOutputStream("src/book.xml"),
format); // 字节流 自己才去查码表
writer.write(document); // writer 自动查 格式化器 得到码表
writer.close();
}
}
4.7.1 DOM4J 解析 XML 文档时的乱码问题
在解决上一节的需求2时,存在码表的问题。为了不出现乱码并保证和原book.xml中的encoding一致,需设置格式化器,并用底层为字节流的writer向src/book.xml文件中写入document。代码已在上面需求2中展示,为强调,把重要的部分代码再次在下面展示:
// 更新内存
// xml的encoding是什么类型, 格式化输入器就用什么码表
OutputFormat format = OutputFormat.createPrettyPrint();
format.setEncoding("UTF-8");
XMLWriter writer = new XMLWriter(new FileOutputStream("src/book.xml"),
format); // 字节流 自己才去查码表
writer.write(document); // writer 自动查 格式化器 得到码表
writer.close();
4.7.2 DOM4J 做 CRUD
book.xml文件:
<?xml version="1.0" encoding="UTF-8"?>
<书架>
<书>
<书名>Java程序设计</书名>
<作者>张三</作者>
<售价>39.00元</售价>
</书>
<书>
<书名 name="xxxx">JavaScript网页开发</书名>
<作者>李四</作者>
<售价>28.00元</售价>
</书>
</书架>
增加(涉及用 List 集合做带 index 的插入操作):
// 在第一本制定位置上添加一个新的售价:<售价>209.00元</售价>
// 方法:更改保存了所有孩子的list集合元素顺序
@Test
public void add2() throws Exception {
SAXReader reader = new SAXReader();
Document document = reader.read(new File("src/book.xml"));
Element book = document.getRootElement().element("书");
// 很别扭的操作,需生成一个List
List<Element> list = book.elements(); // 获得该书的孩子[书名,作者,售价]
// 创建售价标签
Element price = DocumentHelper.createElement("售价");
price.setText("209.00元");
list.add(2, price); // [书名,作者,售价,售价]
// 设置格式
OutputFormat format = OutputFormat.createPrettyPrint();
format.setEncoding("UTF-8");
// 写回xml文档
XMLWriter writer = new XMLWriter(new FileOutputStream("src/book.xml"),
format);
writer.write(document);
writer.close();
}
删除:
// 删除上面添加的售价节点
@Test
public void add2() throws Exception {
SAXReader reader = new SAXReader();
Document document = reader.read(new File("src/book.xml"));
Element book = document.getRootElement().element("书");
List<Element> list = book.elements(); // 获得该书的孩子[书名,作者,售价,售价]
list.remove(2); // [书名,作者,售价]
// 设置格式
OutputFormat format = OutputFormat.createPrettyPrint();
format.setEncoding("UTF-8");
// 写回xml文档
XMLWriter writer = new XMLWriter(new FileOutputStream("src/book.xml"),
format);
writer.write(document);
writer.close();
}
更新:
// 第二本书的作者改为"王二麻子"
@Test
public void update() throws Exception {
SAXReader reader = new SAXReader();
Document document = reader.read(new File("src/book.xml"));
// 获得第二本书
Element book = (Element) document.getRootElement().elements("书").get(1);
book.element("作者").setText("王二麻子");
// 设置格式
OutputFormat format = OutputFormat.createPrettyPrint();
format.setEncoding("UTF-8");
// 写回xml文档
XMLWriter writer = new XMLWriter(new FileOutputStream("src/book.xml"),
format);
writer.write(document);
writer.close();
}
4.7.3 XPath 提取 xml 文档数据 -- Powerful Navigation with XPath
当 xml 文档标签层数很多时,用上一节的方法,通过 root 一层层地找到所需标签根本就是不可行的。XPath 可以迅速定位到所需元素,解决上述尴尬问题。
XPath 提供了强大的标签导航功能,详情请访问: http://www.zvon.org/xxl/XPathTutorial/Output_chi/example1.html
XPath例子1:
里面涉及到2个方法:selectSingleNode()和selectNodes()。他们可接受 XPath 参数。
package cn.wk.dom4j;
import java.io.File;
import java.util.List;
import org.dom4j.Document;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
public class Demo2 {
// 应用xpath提取xml文档的数据
public static void main(String[] args) throws Exception {
SAXReader reader = new SAXReader();
Document document = reader.read(new File("src/book.xml"));
// 得到所有作者的第一个作者
// 若报异常,就把dom4j的lib中的某jar包引入本项目,变成奶瓶
// selectSingleNode()
String value1 = document.selectSingleNode("//作者").getText();
System.out.println(value1);
// selectNodes()
List list = document.selectNodes("//作者");
Element el = (Element) list.get(1);
String value2 = el.getText();
System.out.println(value2);
}
}
XPath例子2:
需求:在 users.xml 中查询是否有和给定用户名和密码相匹配的users
材料准备:users.xml 文件如下:
<?xml version="1.0" encoding="UTF-8"?>
<users>
<user id="1" username="aaa" password="123" email="aa@163.com"/>
<user id="2" username="bbb" password="123" email="bb@163.com"/>
</users>
代码如下(重点是xpath的写法):
public class Demo3 {
public static void main(String[] args) throws Exception {
// 假设用户传来了 用户名和密码
String username = "aa";
String password = "123";
SAXReader reader = new SAXReader();
Document document = reader.read(new File("src/users.xml"));
// xpath 写法是重点:先单引,再双引,再双加号,加入变量
String xpath = "//user[@username='" + username + "' and @password='"
+ password + "']";
Node node = document.selectSingleNode(xpath);
if (node == null)
System.out.println("要查的用户不存在");
else
System.out.println("登陆成功");
}
}
4.8 xml 约束技术之 Schema(特别重要)
做 web services 时用到 Schema 约束技术。
Schema简介:

Schema快速入门:

URI = 名称空间 = Uniform Resource Identifier
试验所需材料:book.xsd和book.xml。
book.xsd:
<?xml version="1.0" encoding="UTF-8"?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.wk.cn" elementFormDefault="qualified">
<!-- shema约束文档的根标签必须是 schema -->
<!-- URI: 名称空间 -->
<!-- 上面qualified表达书架所有元素都被绑定到 "http://www.wk.cn"这个URI上-->
<!-- <xs:complexType>: 元素为复杂类型 -->
<!-- <xs:sequence maxOccurs='unbounded'>: 元素要有顺序,且个数无上限 -->
<xs:element name='书架'>
<xs:complexType>
<xs:sequence maxOccurs='unbounded'>
<xs:element name='书'>
<xs:complexType>
<xs:sequence>
<xs:element name='书名' type='xs:string' />
<xs:element name='作者' type='xs:string' />
<xs:element name='售价' type='xs:string' />
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>
book.xml:
<?xml version="1.0" encoding="UTF-8"?>
<wk:书架 xmlns:wk="http://www.wk.cn" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.wk.cn book.xsd">
<wk:书>
<wk:书名>JavaScript网页开发</wk:书名>
<wk:作者>张三</wk:作者>
<wk:售价>28.00元</wk:售价>
</wk:书>
</wk:书架>
book.xml 内容解释:wk:书架表达了根节点书架来自于wk;xmlns:wk="http://www.wk.cn"又指示了wk代表"http://www.wk.cn"所表达的名称空间 URI。可该命名空间所指示的约束文档在哪里?xsi:schemaLocation="{http://www.wk.cn} {book.xsd}"给出了答案,表示"http://www.wk.cn"这个 URI 所对应的约束文档是book.xsd。因为当前实验约束文档book.xsd和xml文档book.xml在同一个文件夹,所以不必写出约束文档的绝对路径。可schemaLocation又来自于哪里?由谁约束?从xsi:schemaLocation="{http://www.wk.cn} {book.xsd}"可以看到,schemaLocation来自xsi所表达的约束。可是xsi所表达的约束文档又在哪呢?xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"表明xsi表达了 URI 是"http://www.w3.org/2001/XMLSchema-instance",但约束文档在哪呢?因为"http://www.w3.org/2001/XMLSchema-instance"是著名的 URI,与其对应的 Schema 文档我们的解析引擎自己可以找到,不用我们程序员操心了。
4.8.1 名称空间 URI

4.8.2 用名称空间引入 Schema -- schemaLocation

4.8.3 默认名称空间

上图所示的书架来自于默认名称空间xmlns="http://www.it315.org/xmlbook/shema"。
4.8.4 使用 URI 引入多个 XML Schema 约束文档

上图中有1个默认 URI, 2个自定义 URI(demo, xsi)。默认 URI 约束了所有标签,名称空间demo约束了售价标签里的币种属性,xsi约束了schemaLocation。这个例子表明,一个 xml 文档可由多个 Schema 来约束。
4.8.5 不使用名称空间引入 XML Schema 文档(一般不使用这种方式)

上图例子中所有标签直接由 noNamespaceSchemaLocation="xmlbook.xsd" 中定义的xmlbook.xsd这个 schema 文档所约束,但却没有与该文档对应的名称空间。
4.9 Schema 语法详解和案例
XML Schema 语言也称作 XML Schema 定义(XML Schema Definition,XSD)
本节内容均参考 w3school 的 Schema 教程: http://www.w3school.com.cn/schema/index.asp 学习。
4.9.1 简单的类型
4.9.1.1 XSD 简易元素
参考 http://www.w3school.com.cn/schema/schema_simple.asp 自行阅读。
4.9.1.2 XSD 属性
参考 http://www.w3school.com.cn/schema/schema_simple_attributes.asp 自行阅读。
4.9.1.3 XSD 限定 / Facets
里面涉及了正则表达式。
参考 http://www.w3school.com.cn/schema/schema_facets.asp 自行阅读。
4.9.2 复杂的类型
4.9.2.1 XSD 复合元素
参考 http://www.w3school.com.cn/schema/schema_complex.asp 自行阅读。
看的过程中逐渐感受到 Shecma 快要变成 Java 了,果然最后一个例子涉及到了所谓的继承!牛逼的飞起!
4.9.2.2 XSD 复合类型指示器
参考 http://www.w3school.com.cn/schema/schema_complex_indicators.asp 自行阅读。
其中 Order 指示器和 Occurrence 指示器 较为常用。
4.10 自检是否能读懂 Schema 文档
参考 http://www.w3school.com.cn/schema/schema_example.asp。
试验材料:
工程里 src 目录下建立名为 shiporder.xsd的Schema文档:
<?xml version="1.0" encoding="UTF-8" ?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://www.wk.cn" elementFormDefault="qualified">
<xs:element name="shiporder">
<xs:complexType>
<xs:sequence>
<xs:element name="orderperson" type="xs:string" />
<xs:element name="shipto">
<xs:complexType>
<xs:sequence>
<xs:element name="name" type="xs:string" />
<xs:element name="address" type="xs:string" />
<xs:element name="city" type="xs:string" />
<xs:element name="country" type="xs:string" />
</xs:sequence>
</xs:complexType>
</xs:element>
<xs:element name="item" maxOccurs="unbounded">
<xs:complexType>
<xs:sequence>
<xs:element name="title" type="xs:string" />
<xs:element name="note" type="xs:string" minOccurs="0" />
<xs:element name="quantity" type="xs:positiveInteger" />
<xs:element name="price" type="xs:decimal" />
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:sequence>
<xs:attribute name="orderid" type="xs:string" use="required" />
</xs:complexType>
</xs:element>
</xs:schema>
注意到:上面的代码中,我们为这个xsd文档又添加了个名称空间targetNamespace="http://www.wk.cn"(对网上的那个shiporder.xsd做了修改)。
按照上面的 shcema文档写xml命名为shiporder.xml:
<?xml version="1.0" encoding="UTF-8"?>
<!-- 使用了默认名称空间 "http://www.wk.cn" -->
<shiporder orderid="xxxx" xmlns="http://www.wk.cn"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.wk.cn shiporder.xsd">
<orderperson>xxx</orderperson>
<shipto>
<name>xxx</name>
<address>xxx</address>
<city>xxx</city>
<country>xxx</country>
</shipto>
<item>
<title>xxx</title>
<!-- <note>标签最少可以出现0次,即可以不出现 -->
<note>xxx</note>
<quantity>12</quantity>
<price>0.1</price>
</item>
</shiporder>