Apache Kafka 是一个快速、可扩展的、高吞吐的、可容错的分布式“发布-订阅”消息系统, 使用 Scala 与 Java 语言编写,能够将消息从一个端点传递到另一个端点。
较之传统的消息中间件(例如 ActiveMQ、RabbitMQ),Kafka 具有高吞吐量、内置分区、支持消息副本和高容错的特性,非常适合大规模消息处理应用程序。
Kafka 官网:http://kafka.apache.org/
Kafka 主要设计目标如下:
-
以时间复杂度为 O(1) 的方式提供消息持久化能力,即使对 TB 级以上数据也能保证常数时间的访问性能。
-
高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒 100K 条消息的传输。
-
支持 Kafka Server 间的消息分区,及分布式消费,同时保证每个 Partition 内的消息顺序传输。
-
同时支持离线数据处理和实时数据处理。
-
支持在线水平扩展。
Kafka 通常用于两大类应用程序:
-
建立实时流数据管道,以可靠地在系统或应用程序之间获取数据。
-
构建实时流应用程序,以转换或响应数据流。
要了解 Kafka 如何执行这些操作,让我们从头开始深入研究 Kafka 的功能。
首先几个概念:
-
Kafka 在一个或多个可以跨越多个数据中心的服务器上作为集群运行。
-
Kafka 集群将记录流存储在称为主题的类别中。
-
每个记录由一个键,一个值和一个时间戳组成。
Kafka 架构体系如下图

Kafka 的应用场景非常多, 下面我们就来举几个我们最常见的场景:
-
用户的活动跟踪:用户在网站的不同活动消息发布到不同的主题中心,然后可以对这些消息进行实时监测、实时处理。当然,也可以加载到 Hadoop 或离线处理数据仓库,对用户进行画像。像淘宝、天猫、京东这些大型电商平台,用户的所有活动都要进行追踪的。
-
日志收集如下图:
-
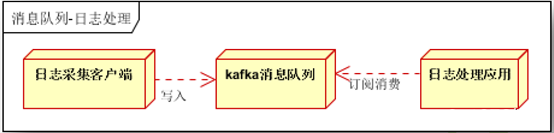
-
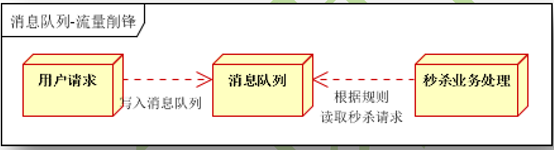
限流削峰如下图:
高吞吐率实现:Kafka 与其他 MQ 相比,最大的特点就是高吞吐率。为了增加存储能力,Kafka 将所有的消息都写入到了低速大容量的硬盘。按理说,这将导致性能损失,但实际上,Kafka 仍然可以保持超高的吞吐率,并且其性能并未受到影响。
其主要采用如下方式实现了高吞吐率:
-
顺序读写:Kafka 将消息写入到了分区 Partition 中,而分区中的消息又是顺序读写的。顺序读写要快于随机读写。
-
零拷贝:生产者、消费者对于 Kafka 中的消息是采用零拷贝实现的。
-
批量发送:Kafka 允许批量发送模式。
-
消息压缩:Kafka 允许对消息集合进行压缩。
Kafka 的优点如下:
-
解耦:在项目启动之初来预测将来项目会碰到什么需求,是极其困难的。消息系统在处理过程中间插入了一个隐含的、基于数据的接口层,两边的处理过程都要实现这一接口。这允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
-
冗余(副本):有些情况下,处理数据的过程会失败。除非数据被持久化,否则将造成丢失。消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险。许多消息队列所采用的"插入-获取-删除"范式中,在把一个消息从队列中删除之前,需要你的处理系统明确的指出该消息已经被处理完毕,从而确保你的数据被安全的保存直到你使用完毕。
-
扩展性:因为消息队列解耦了你的处理过程,所以增大消息入队和处理的频率是很容易的,只要另外增加处理过程即可。不需要改变代码、不需要调节参数。扩展就像调大电力按钮一样简单。
-
灵活性&峰值处理能力:在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见;如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
-
可恢复性:系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理。
-
顺序保证:在大多使用场景下,数据处理的顺序都很重要。大部分消息队列本来就是排序的,并且能保证数据会按照特定的顺序来处理。Kafka 保证一个 Partition 内的消息的有序性。
-
缓冲:在任何重要的系统中,都会有需要不同的处理时间的元素。例如,加载一张图片比应用过滤器花费更少的时间。消息队列通过一个缓冲层来帮助任务最高效率的执行,写入队列的处理会尽可能的快速。该缓冲有助于控制和优化数据流经过系统的速度。
-
异步通信:很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们。
Kafka 与其他 MQ 对比如下:
-
RabbitMQ:RabbitMQ 是使用 Erlang 编写的一个开源的消息队列,本身支持很多的协议:AMQP,XMPP,SMTP,STOMP,也正因如此,它非常重量级,更适合于企业级的开发。同时实现了 Broker 构架,这意味着消息在发送给客户端时先在中心队列排队。对路由,负载均衡或者数据持久化都有很好的支持。
-
Redis:Redis 是一个基于 Key-Value 对的 NoSQL 数据库,开发维护很活跃。虽然它是一个 Key-Value 数据库存储系统,但它本身支持 MQ 功能,所以完全可以当做一个轻量级的队列服务来使用。对于 RabbitMQ 和 Redis 的入队和出队操作,各执行 100 万次,每 10 万次记录一次执行时间。测试数据分为 128Bytes、512Bytes、1K 和 10K 四个不同大小的数据。实验表明:入队时,当数据比较小时 Redis 的性能要高于 RabbitMQ,而如果数据大小超过了 10K,Redis 则慢的无法忍受;出队时,无论数据大小,Redis 都表现出非常好的性能,而 RabbitMQ 的出队性能则远低于 Redis。
-
ZeroMQ:ZeroMQ 号称最快的消息队列系统,尤其针对大吞吐量的需求场景。ZeroMQ 能够实现 RabbitMQ 不擅长的高级/复杂的队列,但是开发人员需要自己组合多种技术框架,技术上的复杂度是对这 MQ 能够应用成功的挑战。ZeroMQ 具有一个独特的非中间件的模式,你不需要安装和运行一个消息服务器或中间件,因为你的应用程序将扮演这个服务器角色。你只需要简单的引用 ZeroMQ 程序库,可以使用 NuGet 安装,然后你就可以愉快的在应用程序之间发送消息了。但是 ZeroMQ 仅提供非持久性的队列,也就是说如果宕机,数据将会丢失。其中,Twitter 的 Storm 0.9.0 以前的版本中默认使用 ZeroMQ 作为数据流的传输(Storm 从 0.9 版本开始同时支持 ZeroMQ 和 Netty 作为传输模块)。
-
ActiveMQ:ActiveMQ 是 Apache 下的一个子项目。类似于 ZeroMQ,它能够以代理人和点对点的技术实现队列。同时类似于 RabbitMQ,它少量代码就可以高效地实现高级应用场景。
-
Kafka/Jafka:Kafka 是 Apache 下的一个子项目,是一个高性能跨语言分布式发布/订阅消息队列系统,而 Jafka 是在 Kafka 之上孵化而来的,即 Kafka 的一个升级版。
具有以下特性:
-
快速持久化,可以在 O(1) 的系统开销下进行消息持久化。
-
高吞吐,在一台普通的服务器上既可以达到 10W/s 的吞吐速率。
-
完全的分布式系统,Broker、Producer、Consumer 都原生自动支持分布式,自动实现负载均衡。
-
支持 Hadoop 数据并行加载,对于像 Hadoop 的一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。
Kafka 通过 Hadoop 的并行加载机制统一了在线和离线的消息处理。Apache Kafka 相对于 ActiveMQ 是一个非常轻量级的消息系统,除了性能非常好之外,还是一个工作良好的分布式系统。
Kafka 的几种重要角色如下:
Kafka 作为存储系统:任何允许发布与使用无关的消息发布的消息队列都有效地充当了运行中消息的存储系统。Kafka 的不同之处在于它是一个非常好的存储系统。写入 Kafka 的数据将写入磁盘并进行复制以实现容错功能。Kafka 允许生产者等待确认,以便直到完全复制并确保即使写入服务器失败的情况下写入也不会完成。
Kafka 的磁盘结构可以很好地扩展使用-无论服务器上有 50KB 还是 50TB 的持久数据,Kafka 都将执行相同的操作。由于认真对待存储并允许客户端控制其读取位置,因此您可以将 Kafka 视为一种专用于高性能,低延迟提交日志存储,复制和传播的专用分布式文件系统。
Kafka 作为消息传递系统:Kafka 的流概念与传统的企业消息传递系统相比如何?传统上,消息传递具有两种模型:排队和发布订阅。在队列中,一组使用者可以从服务器中读取内容,并且每条记录都将转到其中一个。在发布-订阅记录中广播给所有消费者。这两个模型中的每一个都有优点和缺点。排队的优势在于,它允许您将数据处理划分到多个使用者实例上,从而扩展处理量。
不幸的是,队列不是多用户的—一次进程读取了丢失的数据。发布-订阅允许您将数据广播到多个进程,但是由于每条消息都传递给每个订阅者,因此无法扩展处理。Kafka 的消费者群体概念概括了这两个概念。与队列一样,使用者组允许您将处理划分为一组进程(使用者组的成员)。与发布订阅一样,Kafka 允许您将消息广播到多个消费者组。
Kafka 模型的优点在于,每个主题都具有这些属性-可以扩展处理范围,并且是多订阅者,无需选择其中一个。与传统的消息传递系统相比,Kafka 还具有更强的订购保证。传统队列将记录按顺序保留在服务器上,如果多个使用者从队列中消费,则服务器将按记录的存储顺序分发记录。但是,尽管服务器按顺序分发记录,但是这些记录是异步传递给使用者的,因此它们可能在不同的使用者上乱序到达。
这实际上意味着在并行使用的情况下会丢失记录的顺序。消息传递系统通常通过“专有使用者”的概念来解决此问题,该概念仅允许一个进程从队列中使用,但是,这当然意味着在处理中没有并行性。Kafka 做得更好,通过在主题内具有并行性(即分区)的概念,Kafka 能够在用户进程池中提供排序保证和负载均衡。
这是通过将主题中的分区分配给消费者组中的消费者来实现的,以便每个分区都由组中的一个消费者完全消费。通过这样做,我们确保使用者是该分区的唯一读取器,并按顺序使用数据。由于存在许多分区,因此仍然可以平衡许多使用者实例上的负载。但是请注意,使用者组中的使用者实例不能超过分区。
Kafka 用作流处理:仅读取,写入和存储数据流是不够的,目的是实现对流的实时处理。在 Kafka 中,流处理器是指从输入主题中获取连续数据流,对该输入进行一些处理并生成连续数据流以输出主题的任何东西。例如,零售应用程序可以接受销售和装运的输入流,并输出根据此数据计算出的重新订购和价格调整流。
可以直接使用生产者和消费者 API 进行简单处理。但是,对于更复杂的转换,Kafka 提供了完全集成的 Streams API。这允许构建执行非重要处理的应用程序,这些应用程序计算流的聚合或将流连接在一起。该功能有助于解决此类应用程序所面临的难题:处理无序数据,在代码更改时重新处理输入,执行状态计算等。
流 API 建立在 Kafka 提供的核心原语之上:它使用生产者和使用者 API 进行输入,使用 Kafka 进行状态存储,并使用相同的组机制来实现流处理器实例之间的容错。
Kafka 中的关键术语解释

Topic:主题。在 Kafka 中,使用一个类别属性来划分消息的所属类,划分消息的这个类称为 Topic。Topic 相当于消息的分类标签,是一个逻辑概念。物理上不同 Topic 的消息分开存储,逻辑上一个 Topic 的消息虽然保存于一个或多个 Broker 上但用户只需指定消息的 Topic 即可生产或消费数据而不必关心数据存于何处。
Partition:分区。Topic 中的消息被分割为一个或多个 Partition,其是一个物理概念,对应到系统上 就是一个或若干个目录。Partition 内部的消息是有序的,但 Partition 间的消息是无序的。
Segment 段。将 Partition 进一步细分为了若干的 Segment,每个 Segment 文件的大小相等。
Broker:Kafka 集群包含一个或多个服务器,每个服务器节点称为一个 Broker。Broker 存储 Topic 的数据。如果某 Topic 有 N 个 Partition,集群有 N 个 Broker,那么每个 Broker 存储该 Topic 的一个 Partition。
如果某 Topic 有 N 个 Partition,集群有(N+M)个 Broker,那么其中有 N 个 Broker 存储该 Topic 的一个 Partition,剩下的 M 个 Broker 不存储该 Topic 的 Partition 数据。如果某 Topic 有 N 个 Partition,集群中 Broker 数目少于 N 个,那么一个 Broker 存储该 Topic 的一个或多个 Partition。在实际生产环境中,尽量避免这种情况的发生,这种情况容易导致 Kafka 集群数据不均衡。
Producer:生产者。即消息的发布者,生产者将数据发布到他们选择的主题。生产者负责选择将哪个记录分配给主题中的哪个分区。即:生产者生产的一条消息,会被写入到某一个 Partition。
Consumer:消费者。可以从 Broker 中读取消息。一个消费者可以消费多个 Topic 的消息;一个消费者可以消费同一个 Topic 中的多个 Partition 中的消息;一个 Partiton 允许多个 Consumer 同时消费。
Consumer Group:Consumer Group 是 Kafka 提供的可扩展且具有容错性的消费者机制。组内可以有多个消费者,它们共享一个公共的 ID,即 Group ID。组内的所有消费者协调在一起来消费订阅主题 的所有分区。Kafka 保证同一个 Consumer Group 中只有一个 Consumer 会消费某条消息。
实际上,Kafka 保证的是稳定状态下每一个 Consumer 实例只会消费某一个或多个特定的 Partition,而某个 Partition 的数据只会被某一个特定的 Consumer 实例所消费。
下面我们用官网的一张图, 来标识 Consumer 数量和 Partition 数量的对应关系。
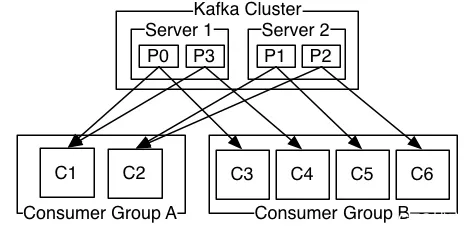
由两台服务器组成的 Kafka 群集,其中包含四个带有两个使用者组的分区(P0-P3)。消费者组 A 有两个消费者实例,组 B 有四个。
对于这个消费组, 以前一直搞不明白, 我自己的总结是:Topic 中的 Partitoin 到 Group 是发布订阅的通信方式。
即一条 Topic 的 Partition 的消息会被所有的 Group 消费,属于一对多模式;Group 到 Consumer 是点对点通信方式,属于一对一模式。
举个例子:不使用 Group 的话,启动 10 个 Consumer 消费一个 Topic,这 10 个 Consumer 都能得到 Topic 的所有数据,相当于这个 Topic 中的任一条消息被消费 10 次。
使用 Group 的话,连接时带上 groupid,Topic 的消息会分发到 10 个 Consumer 上,每条消息只被消费 1 次。
Replizcas of partition:分区副本。副本是一个分区的备份,是为了防止消息丢失而创建的分区的备份。
Partition Leader:每个 Partition 有多个副本,其中有且仅有一个作为 Leader,Leader 是当前负责消息读写的 Partition。即所有读写操作只能发生于 Leader 分区上。
Partition Follower:所有 Follower 都需要从 Leader 同步消息,Follower 与 Leader 始终保持消息同步。Leader 与 Follower 的关系是主备关系,而非主从关系。
ISR:
-
ISR,In-Sync Replicas,是指副本同步列表。ISR 列表是由 Leader 负责维护。
-
AR,Assigned Replicas,指某个 Partition 的所有副本, 即已分配的副本列表。
-
OSR,Outof-Sync Replicas,即非同步的副本列表。
-
AR=ISR+OSR
Offset:偏移量。每条消息都有一个当前 Partition 下唯一的 64 字节的 Offset,它是相当于当前分区第一条消息的偏移量。
Broker Controller:Kafka集群的多个 Broker 中,有一个会被选举 Controller,负责管理整个集群中 Partition 和 Replicas 的状态。
只有 Broker Controller 会向 Zookeeper 中注册 Watcher,其他 Broker 及分区无需注册。即 Zookeeper 仅需监听 Broker Controller 的状态变化即可。
HW 与 LEO:
-
HW,HighWatermark,高水位,表示 Consumer 可以消费到的最高 Partition 偏移量。HW 保证了 Kafka 集群中消息的一致性。确切地说,是保证了 Partition 的 Follower 与 Leader 间数 据的一致性。
-
LEO,Log End Offset,日志最后消息的偏移量。消息是被写入到 Kafka 的日志文件中的, 这是当前最后一个写入的消息在 Partition 中的偏移量。
-
对于 Leader 新写入的消息,Consumer 是不能立刻消费的。Leader 会等待该消息被所有 ISR 中的 Partition Follower 同步后才会更新 HW,此时消息才能被 Consumer 消费。
我相信你看完上面的概念还是懵逼的,好吧!下面我们就用图来形象话的表示两者的关系吧:
ZooKeeper:ZooKeeper 负责维护和协调 Broker,负责 Broker Controller 的选举。在 Kafka 0.9 之前版本,Offset 是由 ZooKeeper 负责管理的。
总结:ZooKeeper 负责 Controller 的选举,Controller 负责 Leader 的选举。
Coordinator:一般指的是运行在每个 Broker 上的 Group Coordinator 进程,用于管理 Consumer Group 中的各个成员,主要用于 Offset 位移管理和 Rebalance。一个 Coordinator 可以同时管理多个消费者组。
Rebalance:当消费者组中的数量发生变化,或者 Topic 中的 Partition 数量发生了变化时,Partition 的所有权会在消费者间转移,即 Partition 会重新分配,这个过程称为再均衡 Rebalance。
再均衡能够给消费者组及 Broker 带来高性能、高可用性和伸缩,但在再均衡期间消费者是无法读取消息的,即整个 Broker 集群有小一段时间是不可用的。因此要避免不必要的再均衡。
Offset Commit:Consumer 从 Broker 中取一批消息写入 Buffer 进行消费,在规定的时间内消费完消息后,会自动将其消费消息的 Offset 提交给 Broker,以记录下哪些消息是消费过的。当然,若在时限内没有消费完毕,其是不会提交 Offset 的。
Kafka的工作原理和过程
消息写入算法
消息发送者将消息发送给 Broker, 并形成最终的可供消费者消费的 log,是已给比较复杂的过程:
-
Producer 先从 ZooKeeper 中找到该 Partition 的 Leader。
-
Producer 将消息发送给该 Leader。
-
Leader 将消息接入本地的 log,并通知 ISR 的 Followers。
-
ISR 中的 Followers 从 Leader 中 Pull 消息, 写入本地 log 后向 Leader 发送 Ack。
-
Leader 收到所有 ISR 中的 Followers 的 Ack 后,增加 HW 并向 Producer 发送 Ack,表示消息写入成功。
消息路由策略
在通过 API 方式发布消息时,生产者是以 Record 为消息进行发布的。
Record 中包含 Key 与 Value,Value 才是我们真正的消息本身,而 Key 用于路由消息所要存放的 Partition。
消息要写入到哪个 Partition 并不是随机的,而是有路由策略的:
-
若指定了 Partition,则直接写入到指定的 Partition。
-
若未指定 Partition 但指定了 Key,则通过对 Key 的 Hash 值与 Partition 数量取模,该取模。
-
结果就是要选出的 Partition 索引。 若 Partition 和 Key 都未指定,则使用轮询算法选出一个 Partition。
HW 截断机制
如果 Partition Leader 接收到了新的消息, ISR 中其它 Follower 正在同步过程中,还未同步完毕时 leader 宕机。
此时就需要选举出新的 Leader。若没有 HW 截断机制,将会导致 Partition 中 Leader 与 Follower 数据的不一致。
当原 Leader 宕机后又恢复时,将其 LEO 回退到其宕机时的 HW,然后再与新的 Leader 进行数据同步,这样就可以保证老 Leader 与新 Leader 中数据一致了,这种机制称为 HW 截断机制。
消息发送的可靠性
生产者向 Kafka 发送消息时,可以选择需要的可靠性级别。通过 request.required.acks 参数的值进行设置。
0 值:异步发送。生产者向 Kafka 发送消息而不需要 Kafka 反馈成功 Ack。该方式效率最高,但可靠性最低。
其可能会存在消息丢失的情况:
-
在传输过程中会出现消息丢失。
-
在 Broker 内部会出现消息丢失。
-
会出现写入到 Kafka 中的消息的顺序与生产顺序不一致的情况。
1 值:同步发送。生产者发送消息给 Kafka,Broker 的 Partition Leader 在收到消息后马上发送成功 Ack(无需等等 ISR 中的 Follower 同步)。
生产者收到后知道消息发送成功,然后会再发送消息。如果一直未收到 Kafka 的 Ack,则生产者会认为消息发送失败,会重发消息。
该方式对于 Producer 来说,若没有收到 Ack,一定可以确认消息发送失败了,然后可以重发。
但是,即使收到了 ACK,也不能保证消息一定就发送成功了。故,这种情况,也可能会发生消息丢失的情况。
-1 值:同步发送。生产者发送消息给 Kafka,Kafka 收到消息后要等到 ISR 列表中的所有副本都 同步消息完成后,才向生产者发送成功 Ack。
如果一直未收到 Kafka 的 Ack,则认为消息发送 失败,会自动重发消息。该方式会出现消息重复接收的情况。
消费者消费过程解析
生产者将消息发送到 Topitc 中,消费者即可对其进行消费,其消费过程如下:
-
Consumer 向 Broker 提交连接请求,其所连接上的 Broker 都会向其发送Broker Controller 的通信 URL,即配置文件中的 Listeners 地址。
-
当 Consumer 指定了要消费的 Topic 后,会向 Broker Controller 发送消费请求。
-
Broker Controller 会为 Consumer 分配一个或几个 Partition Leader,并将该 Partition 的当前 Offset 发送给 Consumer。
-
Consumer 会按照 Broker Controller 分配的 Partition 对其中的消息进行消费。
-
当 Consumer 消费完该条消息后,Consumer 会向 Broker 发送一个消息已经被消费反馈,即该消息的 Offset。
-
在 Broker 接收到 Consumer 的 Offset 后,会更新相应的 __consumer_offset 中。
-
以上过程会一直重复,知道消费者停止请求消费。
-
Consumer 可以重置 Offset,从而可以灵活消费存储在 Broker 上的消息。
Partition Leader 选举范围
当 Leader 宕机后,Broker Controller 会从 ISR 中挑选一个 Follower 成为新的 Leader。
如果 ISR 中没有其他副本怎么办?可以通过 unclean.leader.election.enable 的值来设置 Leader 选举范围。
False:必须等到 ISR 列表中所有的副本都活过来才进行新的选举。该策略可靠性有保证,但可用性低。
True:在 ISR 列表中没有副本的情况下,可以选择任意一个没有宕机的主机作为新的 Leader,该策略可用性高,但可靠性没有保证。
重复消费问题的解决方案
同一个 Consumer 重复消费:当 Consumer 由于消费能力低而引发了消费超时,则可能会形成重复消费。
在某数据刚好消费完毕,但是正准备提交 Offset 时候,消费时间超时,则 Broker 认为这条消息未消费成功。这时就会产生重复消费问题。其解决方案:延长 Offset 提交时间。
不同的 Consumer 重复消费:当 Consumer 消费了消息,但还没有提交 Offset 时宕机,则这些已经被消费过的消息会被重复消费。其解决方案:将自动提交改为手动提交。
从架构设计上解决 Kafka 重复消费的问题
我们在设计程序的时候,比如考虑到网络故障等一些异常的情况,我们都会设置消息的重试次数,可能还有其他可能出现消息重复,那我们应该如何解决呢?下面提供三个方案:
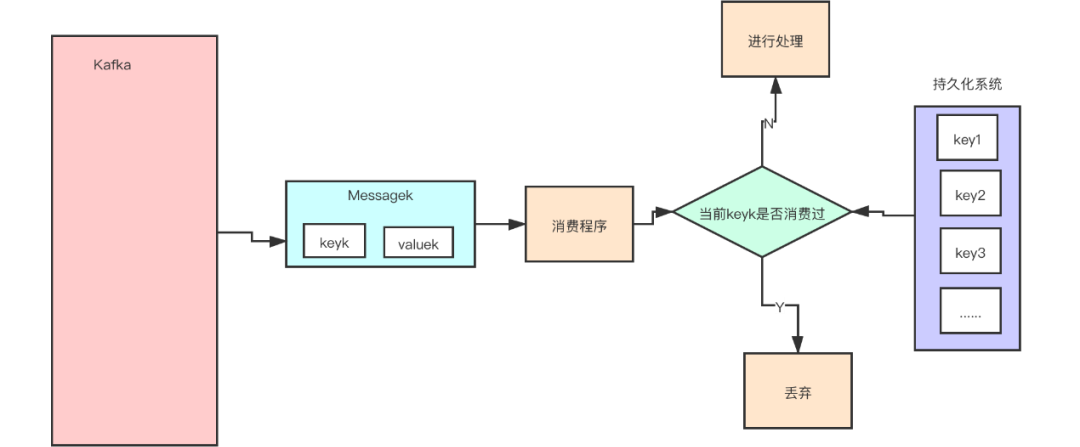
方案一:保存并查询
给每个消息都设置一个独一无二的 uuid,所有的消息,我们都要存一个 uuid。
我们在消费消息的时候,首先去持久化系统中查询一下看这个看是否以前消费过,如没有消费过,在进行消费,如果已经消费过,丢弃就好了。
下图表明了这种方案:
方案二:利用幂等
幂等(Idempotence)在数学上是这样定义的,如果一个函数 f(x) 满足:f(f(x)) = f(x),则函数 f(x) 满足幂等性。
这个概念被拓展到计算机领域,被用来描述一个操作、方法或者服务。一个幂等操作的特点是,其任意多次执行所产生的影响均与一次执行的影响相同。
一个幂等的方法,使用同样的参数,对它进行多次调用和一次调用,对系统产生的影响是一样的。所以,对于幂等的方法,不用担心重复执行会对系统造成任何改变。
我们举个例子来说明一下。在不考虑并发的情况下,“将 X 老师的账户余额设置为 100 万元”,执行一次后对系统的影响是,X 老师的账户余额变成了 100 万元。只要提供的参数 100 万元不变,那即使再执行多少次,X 老师的账户余额始终都是 100 万元,不会变化,这个操作就是一个幂等的操作。
再举一个例子,“将 X 老师的余额加 100 万元”,这个操作它就不是幂等的,每执行一次,账户余额就会增加 100 万元,执行多次和执行一次对系统的影响(也就是账户的余额)是不一样的。
所以,通过这两个例子,我们可以想到如果系统消费消息的业务逻辑具备幂等性,那就不用担心消息重复的问题了,因为同一条消息,消费一次和消费多次对系统的影响是完全一样的。也就可以认为,消费多次等于消费一次。
那么,如何实现幂等操作呢?最好的方式就是,从业务逻辑设计上入手,将消费的业务逻辑设计成具备幂等性的操作。
但是,不是所有的业务都能设计成天然幂等的,这里就需要一些方法和技巧来实现幂等。
下面我们介绍一种常用的方法:利用数据库的唯一约束实现幂等。
例如,我们刚刚提到的那个不具备幂等特性的转账的例子:将 X 老师的账户余额加 100 万元。在这个例子中,我们可以通过改造业务逻辑,让它具备幂等性。
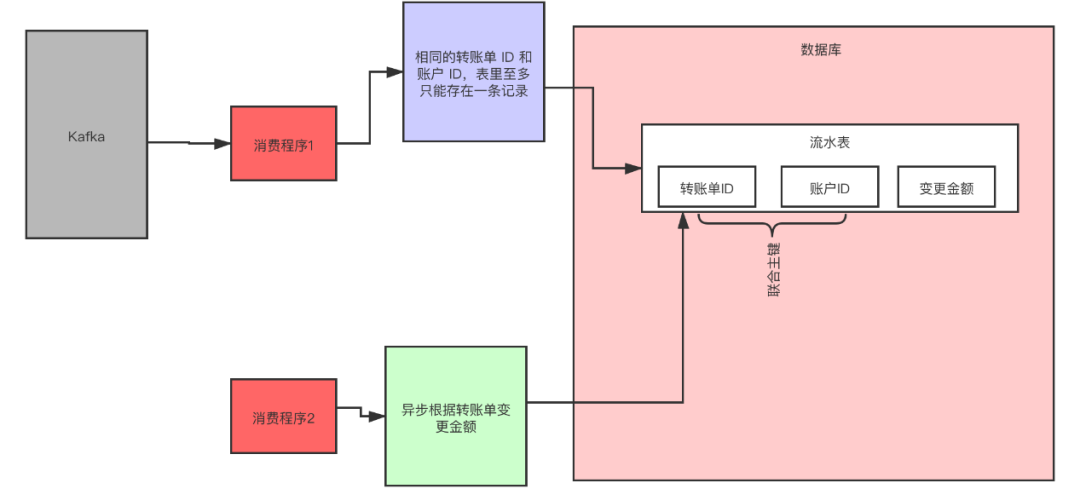
首先,我们可以限定,对于每个转账单每个账户只可以执行一次变更操作,在分布式系统中,这个限制实现的方法非常多,最简单的是我们在数据库中建一张转账流水表。
这个表有三个字段:转账单 ID、账户 ID 和变更金额,然后给转账单 ID 和账户 ID 这两个字段联合起来创建一个唯一约束,这样对于相同的转账单 ID 和账户 ID,表里至多只能存在一条记录。
这样,我们消费消息的逻辑可以变为:“在转账流水表中增加一条转账记录,然后再根据转账记录,异步操作更新用户余额即可。”
在转账流水表增加一条转账记录这个操作中,由于我们在这个表中预先定义了“账户 ID 转账单 ID”的唯一约束,对于同一个转账单同一个账户只能插入一条记录,后续重复的插入操作都会失败,这样就实现了一个幂等的操作。
方案三:设置前提条件
为更新的数据设置前置条件另外一种实现幂等的思路是,给数据变更设置一个前置条件,如果满足条件就更新数据,否则拒绝更新数据,在更新数据的时候,同时变更前置条件中需要判断的数据。
这样,重复执行这个操作时,由于第一次更新数据的时候已经变更了前置条件中需要判断的数据,不满足前置条件,则不会重复执行更新数据操作。
比如,刚刚我们说过,“将 X 老师的账户的余额增加 100 万元”这个操作并不满足幂等性,我们可以把这个操作加上一个前置条件,变为:“如果 X 老师的账户当前的余额为 500 万元,将余额加 100 万元”,这个操作就具备了幂等性。
对应到消息队列中的使用时,可以在发消息时在消息体中带上当前的余额,在消费的时候进行判断数据库中,当前余额是否与消息中的余额相等,只有相等才执行变更操作。
但是,如果我们要更新的数据不是数值,或者我们要做一个比较复杂的更新操作怎么办?用什么作为前置判断条件呢?
更加通用的方法是,给你的数据增加一个版本号属性,每次更数据前,比较当前数据的版本号是否和消息中的版本号一致,如果不一致就拒绝更新数据,更新数据的同时将版本号 +1,一样可以实现幂等。

Kafka 集群搭建
我们在工作中,为了保证环境的高可用,防止单点,Kafka 都是以集群的方式出现的,下面就带领大家一起搭建一套 Kafka 集群环境。
我们在官网下载 Kafka,下载地址为:http://kafka.apache.org/downloads,下载我们需要的版本,推荐使用稳定的版本。
搭建集群
下载并解压:
cd /usr/local/src wget http://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.4.0/kafka_2.11-2.4.0.tgz mkdir /data/servers tar xzvf kafka_2.11-2.4.0.tgz -C /data/servers/ cd /data/servers/kafka_2.11-2.4.0
修改配置文件:
Kafka 的配置文件 $KAFKA_HOME/config/server.properties,主要修改一下下面几项:
确保每个机器上的 id 不一样 broker.id=0 配置服务端的监控地址 listeners=PLAINTEXT://192.168.51.128:9092 Kafka 日志目录 log.dirs=/data/servers/kafka_2.11-2.4.0/logs #Kafka 设置的 partitons 的个数 num.partitions=1 ZooKeeper 的连接地址,如果有自己的 ZooKeeper 集群,请直接使用自己搭建的 ZooKeeper 集群 zookeeper.connect=192.168.51.128:2181
因为我自己是本机做实验,所有使用的是一个主机的不同端口,在线上,就是不同的机器,大家参考即可。
我们这里使用 Kafka 的 ZooKeeper,只启动一个节点,但是正真的生产过程中,是需要 ZooKeeper 集群,自己搭建就好,后期我们也会出 ZooKeeper 的教程,大家请关注就好了。
拷贝 3 份配置文件:
#创建对应的日志目录
mkdir -p /data/servers/kafka_2.11-2.4.0/logs/9092 mkdir -p /data/servers/kafka_2.11-2.4.0/logs/9093 mkdir -p /data/servers/kafka_2.11-2.4.0/logs/9094
#拷贝三份配置文件
cp server.properties server_9092.properties
cp server.properties server_9093.properties
cp server.properties server_9094.properties
修改不同端口对应的文件:
#9092 的 id 为 0,9093 的 id 为 1,9094 的 id 为 2 broker.id=0 # 配置服务端的监控地址,在不通的配置文件中写入不同的端口 listeners=PLAINTEXT://192.168.51.128:9092 # Kafka 日志目录,目录也是对应不同的端口 log.dirs=/data/servers/kafka_2.11-2.4.0/logs/9092 # Kafka 设置的 partitons 的个数 num.partitions=1 # ZooKeeper 的连接地址,如果有自己的 ZooKeeper 集群,请直接使用自己搭建的 ZooKeeper 集群 zookeeper.connect=192.168.51.128:2181
修改 ZooKeeper 的配置文件:
dataDir=/data/servers/zookeeper server.1=192.168.51.128:2888:3888
然后创建 ZooKeeper 的 myid 文件:
echo "1"> /data/servers/zookeeper/myid
启动 ZooKeeper:
使用 Kafka 内置的 ZooKeeper:
cd /data/servers/kafka_2.11-2.4.0/bin zookeeper-server-start.sh -daemon ../config/zookeeper.properties netstat -anp |grep 2181
启动 Kafka:
./kafka-server-start.sh -daemon ../config/server_9092.properties ./kafka-server-start.sh -daemon ../config/server_9093.properties ./kafka-server-start.sh -daemon ../config/server_9094.properties
Kafka 的操作
Topic
我们先来看一下创建 Topic 常用的参数吧:
-
--create:创建 topic
-
--delete:删除 topic
-
--alter:修改 topic 的名字或者 partition 个数
-
--list:查看 topic
-
--describe:查看 topic 的详细信息
-
--topic <String: topic>:指定 topic 的名字
-
--zookeeper <String: hosts>:指定 Zookeeper 的连接地址参数提示并不赞成这样使用(DEPRECATED, The connection string for the zookeeper connection in the form host:port. Multiple hosts can be given to allow fail-over.)
-
--bootstrap-server <String: server to connect to>:指定 Kafka 的连接地址,推荐使用这个,参数的提示信息显示(REQUIRED: The Kafka server to connect to. In case of providing this, a direct Zookeeper connection won't be required.)。
-
--replication-factor <Integer: replication factor>:对于每个 Partiton 的备份个数。(The replication factor for each partition in the topic being created. If not supplied, defaults to the cluster default.)
-
--partitions <Integer: # of partitions>:指定该 topic 的分区的个数。
示例:
cd /data/servers/kafka_2.11-2.4.0/bin # 创建 topic test1 kafka-topics.sh --create --bootstrap-server=192.168.51.128:9092,10.231.128.96:9093,192.168.51.128:9094 --replication-factor 1 --partitions 1 --topic test1 # 创建 topic test2 kafka-topics.sh --create --bootstrap-server=192.168.51.128:9092,10.231.128.96:9093,192.168.51.128:9094 --replication-factor 1 --partitions 1 --topic test2 # 查看 topic kafka-topics.sh --list --bootstrap-server=192.168.51.128:9092,10.231.128.96:9093,192.168.51.128:9094
自动创建 Topic
我们在工作中,如果我们不想去管理 Topic,可以通过 Kafka 的配置文件来管理。
我们可以让 Kafka 自动创建 Topic,需要在我们的 Kafka 配置文件中加入如下配置文件:
auto.create.topics.enable=true
如果删除 Topic 想达到物理删除的目的,也是需要配置的:
delete.topic.enable=true
发送消息
他们可以通过客户端的命令生产消息,先来看看 kafka-console-producer.sh 常用的几个参数吧:
-
--topic <String: topic>:指定 topic
-
--timeout <Integer: timeout_ms>:超时时间
-
--sync:异步发送消息
-
--broker-list <String: broker-list>:官网提示:REQUIRED: The broker list string in the form HOST1:PORT1,HOST2:PORT2.
这个参数是必须的:
kafka-console-producer.sh --broker-list 192.168.51.128:9092,192.168.51.128:9093,192.168.51.128:9094 --topic test1
消费消息
我们也还是先来看看 kafka-console-consumer.sh 的参数吧:
-
--topic <String: topic>:指定 topic
-
--group <String: consumer group id>:指定消费者组
-
--from-beginning:指定从开始进行消费, 如果不指定, 就从当前进行消费
-
--bootstrap-server:Kafka 的连接地址
kafka-console-consumer.sh --bootstrap-server 192.168.51.128:9092,192.168.51.128:9093,192.168.51.128:9094 --topic test1 ---beginning

Kafka 的日志
Kafka 的日志分两种:
-
第一种日志是我们的 Kafka 的启动日志,就是我们排查问题,查看报错信息的日志。
-
第二种日志就是我们的数据日志,Kafka 是我们的数据是以日志的形式存在存盘中的,我们第二种所说的日志就是我们的 Partiton 与 Segment。
那我们就来说说备份和分区吧:我们创建一个分区,一个备份,那么 test 就应该在三台机器上或者三个数据目录只有一个 test-0。(分区的下标是从 0 开始的)
如果我们创建 N 个分区,我们就会在三个服务器上发现,test_0-n,如果我们创建 M 个备份,我们就会在发现,test_0 到 test_n 每一个都是 M 个。
Kafka API
使用 Kafka 原生的 API
消费者自动提交
定义自己的生产者:
import org.apache.kafka.clients.producer.Callback; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.ProducerRecord; import org.apache.kafka.clients.producer.RecordMetadata; import java.util.Properties; /** * @ClassName MyKafkaProducer * @Description TODO * @Author lingxiangxiang * @Date 3:37 PM * @Version 1.0 **/ public class MyKafkaProducer { private org.apache.kafka.clients.producer.KafkaProducer<Integer, String> producer; public MyKafkaProducer() { Properties properties = new Properties(); properties.put("bootstrap.servers", "192.168.51.128:9092,192.168.51.128:9093,192.168.51.128:9094"); properties.put("key.serializer", "org.apache.kafka.common.serialization.IntegerSerializer"); properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 设置批量发送 properties.put("batch.size", 16384); // 批量发送的等待时间 50ms, 超过 50ms, 不足批量大小也发送 properties.put("linger.ms", 50); this.producer = new org.apache.kafka.clients.producer.KafkaProducer<Integer, String>(properties); } public boolean sendMsg() { boolean result = true; try { // 正常发送, test2 是 topic, 0 代表的是分区, 1 代表的是 key, hello world 是发送的消息内容 final ProducerRecord<Integer, String> record = new ProducerRecord<Integer, String>("test2", 0, 1, "hello world"); producer.send(record); // 有回调函数的调用 producer.send(record, new Callback() { @Override public void onCompletion(RecordMetadata recordMetadata, Exception e) { System.out.println(recordMetadata.topic()); System.out.println(recordMetadata.partition()); System.out.println(recordMetadata.offset()); } }); // 自己定义一个类 producer.send(record, new MyCallback(record)); } catch (Exception e) { result = false; } return result; } }
定义生产者发送成功的回调函数:
import org.apache.kafka.clients.producer.Callback; import org.apache.kafka.clients.producer.RecordMetadata; /** * @ClassName MyCallback * @Description TODO * @Author lingxiangxiang * @Date 3:51 PM * @Version 1.0 **/ public class MyCallback implements Callback { private Object msg; public MyCallback(Object msg) { this.msg = msg; } @Override public void onCompletion(RecordMetadata metadata, Exception e) { System.out.println("topic = " + metadata.topic()); System.out.println("partiton = " + metadata.partition()); System.out.println("offset = " + metadata.offset()); System.out.println(msg); } }
生产者测试类:在生产者测试类中,自己遇到一个坑,就是最后自己没有加 sleep,就是怎么检查自己的代码都没有问题,但是最后就是没法发送成功消息,最后加了一个 sleep 就可以了。
因为主函数 main 已经执行完退出,但是消息并没有发送完成,需要进行等待一下。当然,你在生产环境中可能不会遇到这样问题,呵呵!
代码如下:
import static java.lang.Thread.sleep; /** * @ClassName MyKafkaProducerTest * @Description TODO * @Author lingxiangxiang * @Date 3:46 PM * @Version 1.0 **/ public class MyKafkaProducerTest { public static void main(String[] args) throws InterruptedException { MyKafkaProducer producer = new MyKafkaProducer(); boolean result = producer.sendMsg(); System.out.println("send msg " + result); sleep(1000); } }
消费者类:
import kafka.utils.ShutdownableThread; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import java.util.Arrays; import java.util.Collections; import java.util.Properties; /** * @ClassName MyKafkaConsumer * @Description TODO * @Author lingxiangxiang * @Date 4:12 PM * @Version 1.0 **/ public class MyKafkaConsumer extends ShutdownableThread { private KafkaConsumer<Integer, String> consumer; public MyKafkaConsumer() { super("KafkaConsumerTest", false); Properties properties = new Properties(); properties.put("bootstrap.servers", "192.168.51.128:9092,192.168.51.128:9093,192.168.51.128:9094"); properties.put("group.id", "mygroup"); properties.put("enable.auto.commit", "true"); properties.put("auto.commit.interval.ms", "1000"); properties.put("session.timeout.ms", "30000"); properties.put("heartbeat.interval.ms", "10000"); properties.put("auto.offset.reset", "earliest"); properties.put("key.deserializer", "org.apache.kafka.common.serialization.IntegerDeserializer"); properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); this.consumer = new KafkaConsumer<Integer, String>(properties); } @Override public void doWork() { consumer.subscribe(Arrays.asList("test2")); ConsumerRecords<Integer, String>records = consumer.poll(1000); for (ConsumerRecord record : records) { System.out.println("topic = " + record.topic()); System.out.println("partition = " + record.partition()); System.out.println("key = " + record.key()); System.out.println("value = " + record.value()); } } }
消费者的测试类:
/** * @ClassName MyConsumerTest * @Description TODO * @Author lingxiangxiang * @Date 4:23 PM * @Version 1.0 **/ public class MyConsumerTest { public static void main(String[] args) { MyKafkaConsumer consumer = new MyKafkaConsumer(); consumer.start(); System.out.println("=================="); } }

消费者同步手动提交
前面的消费者都是以自动提交 Offset 的方式对 Broker 中的消息进行消费的,但自动提交 可能会出现消息重复消费的情况。
所以在生产环境下,很多时候需要对 Offset 进行手动提交, 以解决重复消费的问题。
手动提交又可以划分为同步提交、异步提交,同异步联合提交。这些提交方式仅仅是 doWork() 方法不相同,其构造器是相同的。
所以下面首先在前面消费者类的基础上进行构造器的修改,然后再分别实现三种不同的提交方式。
同步提交方式是,消费者向 Broker 提交 Offset 后等待 Broker 成功响应。若没有收到响应,则会重新提交,直到获取到响应。
而在这个等待过程中,消费者是阻塞的。其严重影响了消费者的吞吐量。
修改前面的 MyKafkaConsumer.java, 主要修改下面的配置:
import kafka.utils.ShutdownableThread; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import java.util.Arrays; import java.util.Collections; import java.util.Properties; /** * @ClassName MyKafkaConsumer * @Description TODO * @Author lingxiangxiang * @Date 4:12 PM * @Version 1.0 **/ public class MyKafkaConsumer extends ShutdownableThread { private KafkaConsumer<Integer, String> consumer; public MyKafkaConsumer() { super("KafkaConsumerTest", false); Properties properties = new Properties(); properties.put("bootstrap.servers", "192.168.51.128:9092,192.168.51.128:9093,192.168.51.128:9094"); properties.put("group.id", "mygroup"); // 这里要修改成手动提交 properties.put("enable.auto.commit", "false"); // properties.put("auto.commit.interval.ms", "1000"); properties.put("session.timeout.ms", "30000"); properties.put("heartbeat.interval.ms", "10000"); properties.put("auto.offset.reset", "earliest"); properties.put("key.deserializer", "org.apache.kafka.common.serialization.IntegerDeserializer"); properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); this.consumer = new KafkaConsumer<Integer, String>(properties); } @Override public void doWork() { consumer.subscribe(Arrays.asList("test2")); ConsumerRecords<Integer, String>records = consumer.poll(1000); for (ConsumerRecord record : records) { System.out.println("topic = " + record.topic()); System.out.println("partition = " + record.partition()); System.out.println("key = " + record.key()); System.out.println("value = " + record.value()); //手动同步提交 consumer.commitSync(); } } }
消费者异步手工提交
手动同步提交方式需要等待 Broker 的成功响应,效率太低,影响消费者的吞吐量。
异步提交方式是,消费者向 Broker 提交 Offset 后不用等待成功响应,所以其增加了消费者的吞吐量。
import kafka.utils.ShutdownableThread; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import java.util.Arrays; import java.util.Collections; import java.util.Properties; /** * @ClassName MyKafkaConsumer * @Description TODO * @Author lingxiangxiang * @Date 4:12 PM * @Version 1.0 **/ public class MyKafkaConsumer extends ShutdownableThread { private KafkaConsumer<Integer, String> consumer; public MyKafkaConsumer() { super("KafkaConsumerTest", false); Properties properties = new Properties(); properties.put("bootstrap.servers", "192.168.51.128:9092,192.168.51.128:9093,192.168.51.128:9094"); properties.put("group.id", "mygroup"); // 这里要修改成手动提交 properties.put("enable.auto.commit", "false"); // properties.put("auto.commit.interval.ms", "1000"); properties.put("session.timeout.ms", "30000"); properties.put("heartbeat.interval.ms", "10000"); properties.put("auto.offset.reset", "earliest"); properties.put("key.deserializer", "org.apache.kafka.common.serialization.IntegerDeserializer"); properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); this.consumer = new KafkaConsumer<Integer, String>(properties); } @Override public void doWork() { consumer.subscribe(Arrays.asList("test2")); ConsumerRecords<Integer, String>records = consumer.poll(1000); for (ConsumerRecord record : records) { System.out.println("topic = " + record.topic()); System.out.println("partition = " + record.partition()); System.out.println("key = " + record.key()); System.out.println("value = " + record.value()); //手动同步提交 // consumer.commitSync(); //手动异步提交 // consumer.commitAsync(); // 带回调公共的手动异步提交 consumer.commitAsync((offsets, e) -> { if(e != null) { System.out.println("提交次数, offsets = " + offsets); System.out.println("exception = " + e); } }); } } }
Spring Boot 使用 Kafka
现在大家的开发过程中,很多都用的是 Spring Boot 的项目,直接启动了,如果还是用原生的 API,就是有点 Low 了啊,那 Kafka 是如何和 Spring Boot 进行联合的呢?
Maven 配置:
<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka-clients --> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>2.1.1</version> </dependency>
添加配置文件,在 application.properties 中加入如下配置信息:
Kafka 连接地址:
spring.kafka.bootstrap-servers = 192.168.51.128:9092,10.231.128.96:9093,192.168.51.128:9094
生产者:
spring.kafka.producer.acks = 0 spring.kafka.producer.key-serializer = org.apache.kafka.common.serialization.StringSerializer spring.kafka.producer.value-serializer = org.apache.kafka.common.serialization.StringSerializer spring.kafka.producer.retries = 3 spring.kafka.producer.batch-size = 4096 spring.kafka.producer.buffer-memory = 33554432 spring.kafka.producer.compression-type = gzip
消费者:
spring.kafka.consumer.group-id = mygroup spring.kafka.consumer.auto-commit-interval = 5000 spring.kafka.consumer.heartbeat-interval = 3000 spring.kafka.consumer.key-deserializer = org.apache.kafka.common.serialization.StringDeserializer spring.kafka.consumer.value-deserializer = org.apache.kafka.common.serialization.StringDeserializer spring.kafka.consumer.auto-offset-reset = earliest spring.kafka.consumer.enable-auto-commit = true # listenner, 标识消费者监听的个数 spring.kafka.listener.concurrency = 8 # topic的名字 kafka.topic1 = topic1
生产者:
import lombok.extern.slf4j.Slf4j; import org.springframework.beans.factory.annotation.Value; import org.springframework.kafka.core.KafkaTemplate; @Service @Slf4j public class MyKafkaProducerServiceImpl implements MyKafkaProducerService { @Resource private KafkaTemplate<String, String> kafkaTemplate; // 读取配置文件 @Value("${kafka.topic1}") private String topic; @Override public void sendKafka() { kafkaTemplate.send(topic, "hell world"); } }
消费者:
@Component @Slf4j public class MyKafkaConsumer { @KafkaListener(topics = "${kafka.topic1}") public void listen(ConsumerRecord<?, ?> record) { Optional<?> kafkaMessage = Optional.ofNullable(record.value()); if (kafkaMessage.isPresent()) { log.info("----------------- record =" + record); log.info("------------------ message =" + kafkaMessage.get()); }