主成分分析
什么是主成分分析(PCA)
定义:高维数据转化为低维数据的过程,在此过程中可能会舍弃原有数据、创造新的变量
作用:是数据维数压缩,尽可能降低原数据的维数(复杂度),损失少量信息。
应用:回归分析或者聚类分析当中
API
sklearn.decomposition.PCA(n_components=None)
- 将数据分解为较低维数空间
- n_components: 小数:表示保留百分之多少的信息 整数:减少到多少特征
- PCA.fit_transform(X) X:numpy array格式的数据[n_samples,n_features]
- 返回值:转换后指定维度的array
数据计算
先拿个简单的数据计算一下
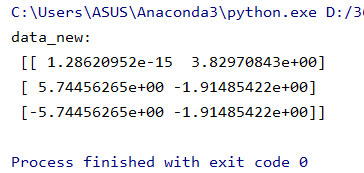
[[2,8,4,5], [6,3,0,8], [5,4,9,1]]
from sklearn.decomposition import PCA def pca_demo(): """ PCA降维 :return: """ data = [[2,8,4,5], [6,3,0,8], [5,4,9,1]] # 1、实例化一个转换器类 transfer = PCA(n_components=0.95) # 2、调用fit_transform data_new = transfer.fit_transform(data) print("data_new: ", data_new) return None if __name__ == "__main__": # 代码11:PCA降维 pca_demo()
- 小数:表示保留百分之多少的信息
- 整数:减少到多少特征
案例:探究用户对物品类别的喜好细分降维
数据网盘链接:
链接:https://pan.baidu.com/s/1gJIegOiAAYhK3dtcpVr4Mw
提取码:irg9
数据如下:
-
order_products__prior.csv:订单与商品信息
- 字段:order_id, product_id, add_to_cart_order, reordered
-
products.csv:商品信息
- 字段:product_id, product_name, aisle_id, department_id
- orders.csv:用户的订单信息
- 字段:order_id,user_id,eval_set,order_number,….
- aisles.csv:商品所属具体物品类别
- 字段: aisle_id, aisle
需求
分析
- 合并表,使得user_id与aisle在一张表当中
- 进行交叉表变换
- 进行降维
完整代码
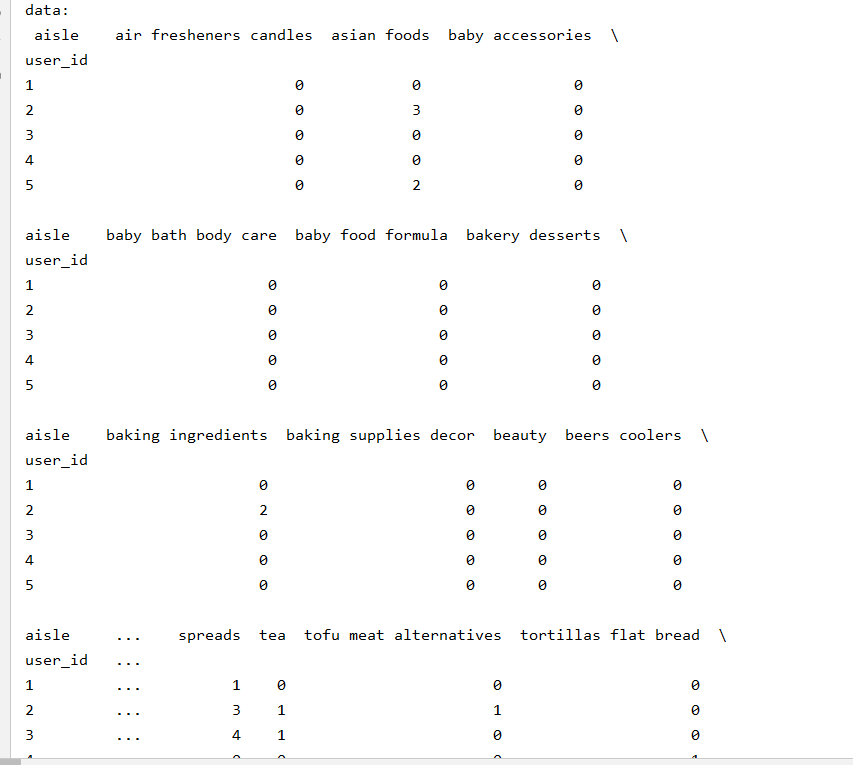
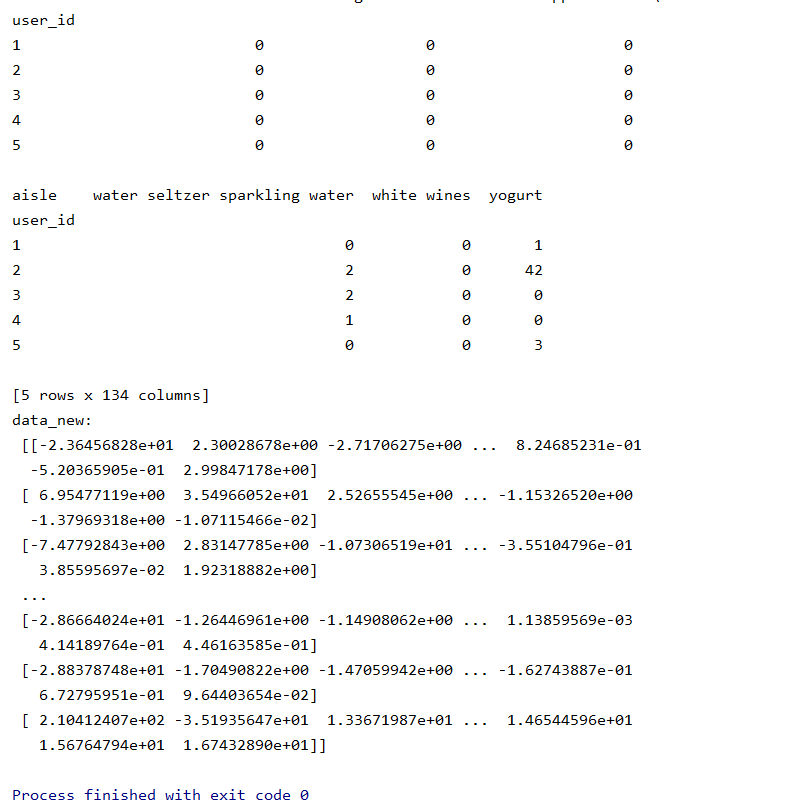
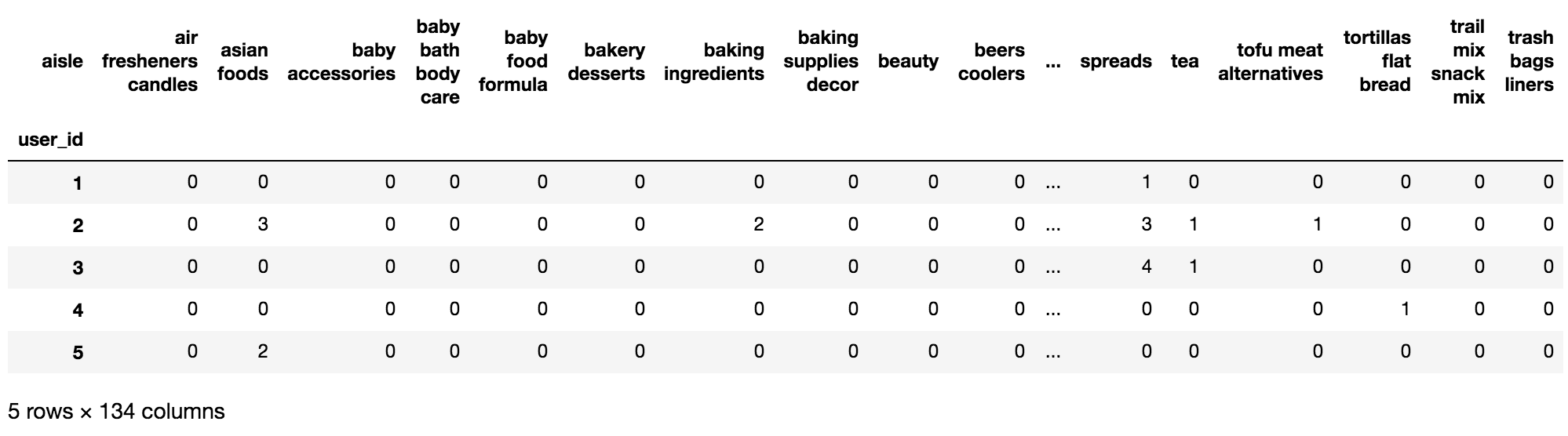
import pandas as pd # 1、获取数据 order_products = pd.read_csv("../../instacart/order_products__prior.csv") products = pd.read_csv("../../instacart/products.csv") orders = pd.read_csv("../../instacart/orders.csv") aisles = pd.read_csv("../../instacart/aisles.csv") # 2、合并表 # order_products__prior.csv:订单与商品信息 # 字段:order_id, product_id, add_to_cart_order, reordered # products.csv:商品信息 # 字段:product_id, product_name, aisle_id, department_id # orders.csv:用户的订单信息 # 字段:order_id,user_id,eval_set,order_number,…. # aisles.csv:商品所属具体物品类别 # 字段: aisle_id, aisle # 合并aisles和products aisle和product_id tab1 = pd.merge(aisles, products, on=["aisle_id", "aisle_id"]) tab2 = pd.merge(tab1, order_products, on=["product_id", "product_id"]) tab3 = pd.merge(tab2, orders, on=["order_id", "order_id"]) print("tab3: ",tab3.head()) # 3、找到user_id和aisle之间的关系 table = pd.crosstab(tab3["user_id"], tab3["aisle"]) data = table[:10000] print("data: ",data.head()) # 4、PCA降维 from sklearn.decomposition import PCA # 1)实例化一个转换器类 transfer = PCA(n_components=0.95) # 2)调用fit_transform data_new = transfer.fit_transform(data) print("data_new: ",data_new)
返回结果: