TF-IDF算法是一种简单快捷的文档特征词抽取方法,通过统计文档中的词频来对文档进行主题分类。TF-IDF(term frequency–inverse document frequency)是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级。
TF-IDF其主要思想是,如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TF词频(Term Frequency)指的是某一个给定的词语在该文件中出现的次数。IDF反文档频率(Inverse Document Frequency)是指,如果包含词条的文档越少,IDF越大,则说明词条具有很好的类别区分能力。使用TF-IDF可以计算某个关键字在某篇文章里面的重要性,可以用此关键词来表达文档所包含的含义。
词频Term Frequency(tfij)表示文档i中词汇j出现的频率,计算公式如下:
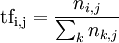
其中,nij表示词j在文档i中出现的次数,分母则是文档j中所有字词出现的次数之和。
逆向文档频率Inverse Document Frequency(idfj):是一个词普遍重要性的度量,由下面的式子计算:
其中,|D|是文档总数,分母是包含词ti的文档数目。
tfidfij权值(wij):wij = tfij * idfi。权值就是最终要得到的结果,权值的高低直接表明了该题词是否反应了文档的主题。
实验的第一个步骤是分词,英文的分词很简单,中文分词就是个难题了。在实验中使用了中科院的ICTCLAS(Institute of Computing Technology, Chinese Lexical Analysis System)系统。该系统应该说是国内较好的分词系统,是中国科学院计算技术研究所在多年研究工作积累的基础上,基于多层隐马模型研制出的汉语词法分析系统,主要功能包括中文分词;词性标注;命 名实体识别;新词识别;同时支持用户词典。
在分词时为了提高分词效果,我加入了自己的用户词典 。不过词语不多,只有17个,如果要准确一点的话,应该再多一点。
分词后,去掉里面的词性标注,然后在去掉里面的停用词(这一步做得不是很好,停用词表有900个词,但是在最后统计中发现还是有一些停用词)。
最后一步就是利用上面的公式进行词频统计了。统计的方法很多,可以些程序,也可以处理后放到数据库、Excel或装用的统计软件统计。我这里主要是放到数据库后用程序来统计。
统计的结果还算满意。我选择了学生心理在线上关于大学生心理健康的文章13篇,主要关于爱情、就业、性教育、学习、人际交往等几个方面。统计的结果表明,抽取的主题词70%左右的表明文章的主题,还有一些则是由于分词错误,使得该词没有体现主题,但权值较高。
这个实验只是一个验证实验,要达到实际应用需求,在TF-IDF中还需要做很多的改进。比如考虑语句关系、词性关系、文章关系、文章标题的重要程度等。