实验目的
1.准确理解MapReduce去重的设计原理
2.熟练掌握MapReduce去重的程序编写
3.学会自己编写MapReduce去重代码解决实际问题
实验原理
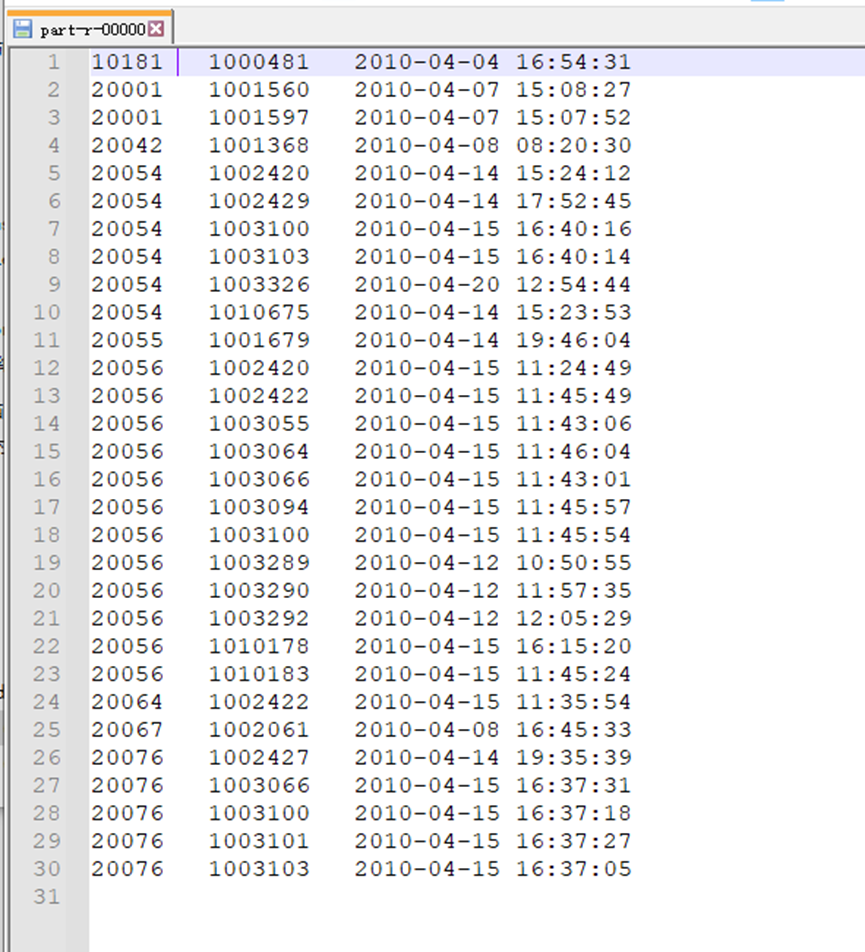
“数据去重”主要是为了掌握和利用并行化思想来对数据进行有意义的筛选。统计大数据集上的数据种类个数、从网站日志中计算访问地等这些看似庞杂的任务都会涉及数据去重。
数据去重的最终目标是让原始数据中出现次数超过一次的数据在输出文件中只出现一次。在MapReduce流程中,map的输出<key,value>经过shuffle过程聚集成<key,value-list>后交给reduce。我们自然而然会想到将同一个数据的所有记录都交给一台reduce机器,无论这个数据出现多少次,只要在最终结果中输出一次就可以了。具体就是reduce的输入应该以数据作为key,而对value-list则没有要求(可以设置为空)。当reduce接收到一个<key,value-list>时就直接将输入的key复制到输出的key中,并将value设置成空值,然后输出<key,value>。
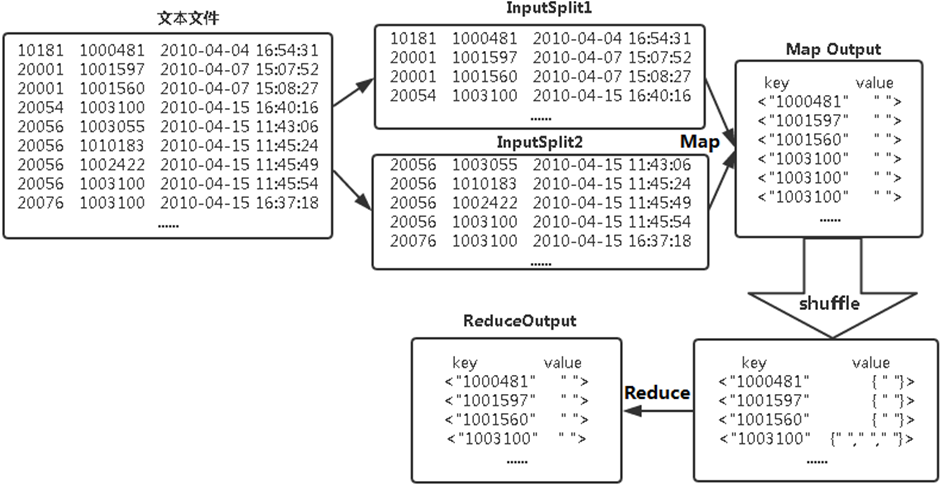
MaprReduce去重流程如下图所示:
启动hadoop
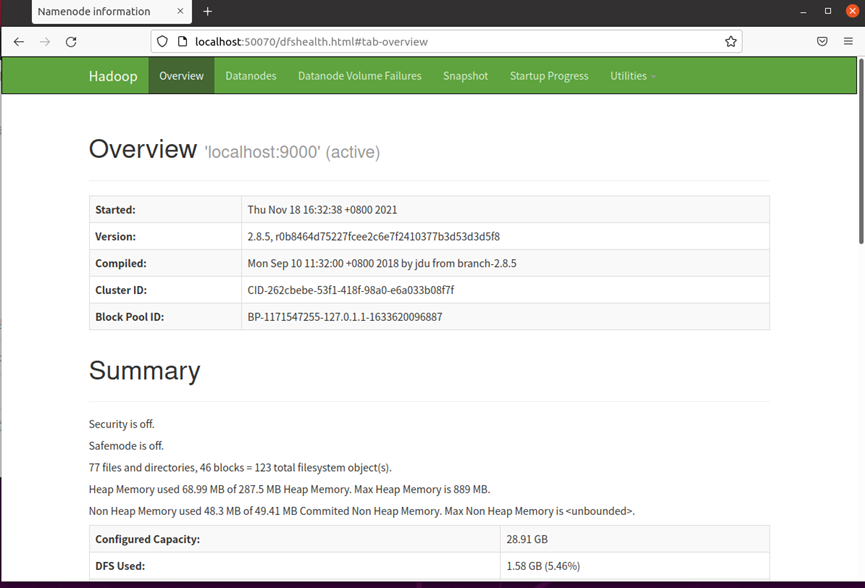
启动成功
生成文件
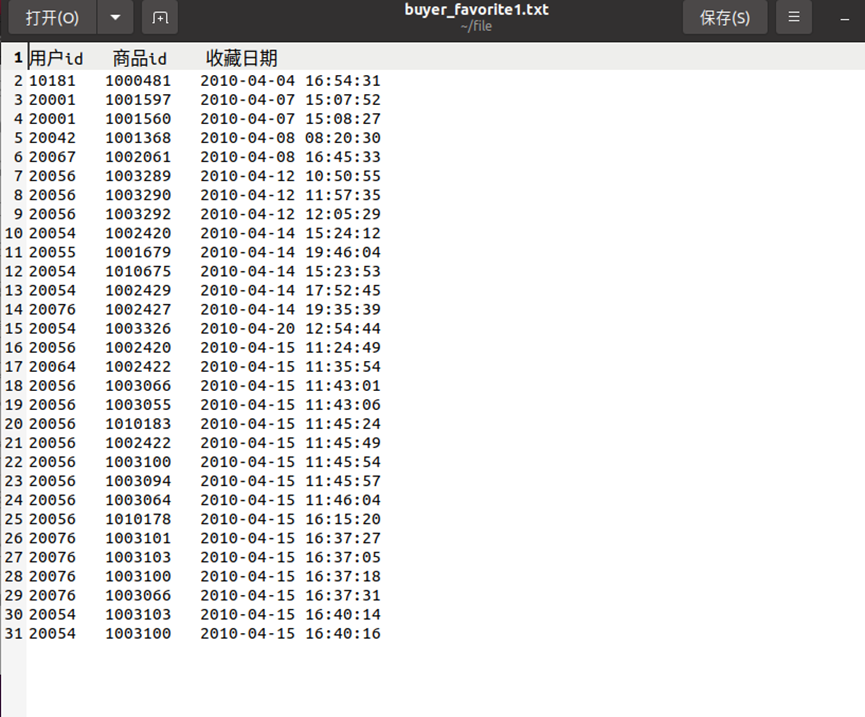
创建java项目
写入代码
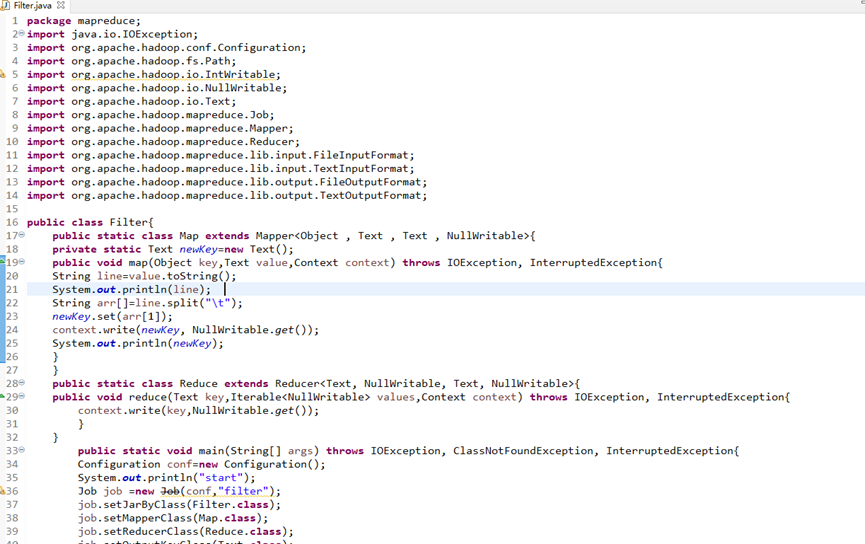
运行
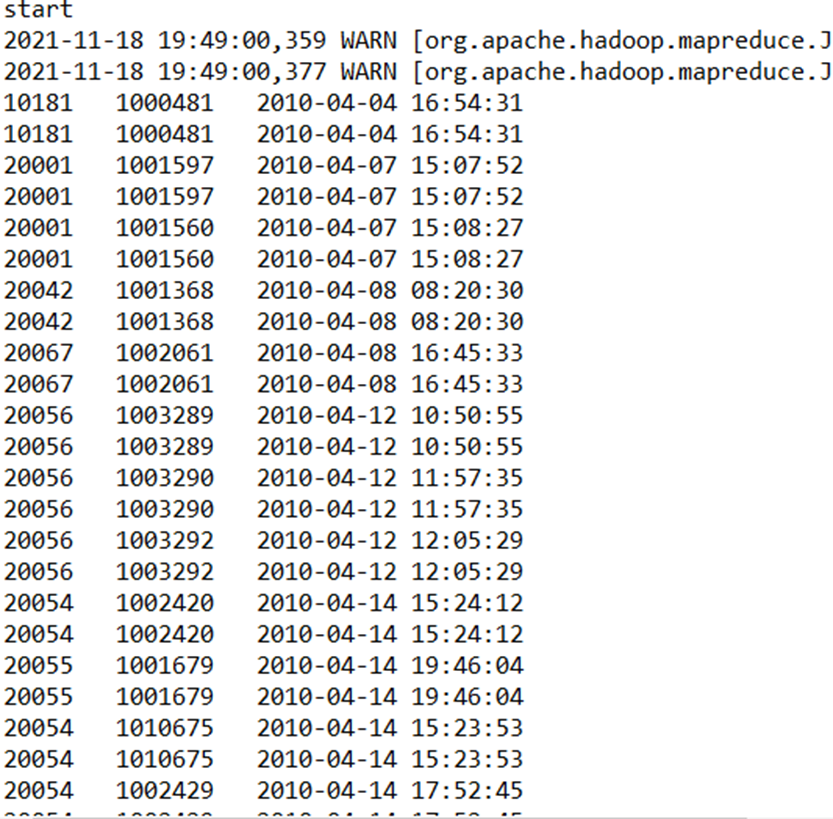
最后结果