一、什么是Redis?
1.redis是一款高性能的NOSQL系列的非关系型数据库
键值(Key-Value)存储数据库
相关产品: Tokyo Cabinet/Tyrant、Redis、Voldemort、Berkeley DB
典型应用: 内容缓存,主要用于处理大量数据的高访问负载。
数据模型: 一系列键值对
优势: 快速查询
劣势: 存储的数据缺少结构化
2.redis的应用场景
• 缓存(数据查询、短连接、新闻内容、商品内容等等)
• 聊天室的在线好友列表
• 任务队列。(秒杀、抢购、12306等等)
• 应用排行榜
• 网站访问统计
• 数据过期处理(可以精确到毫秒
• 分布式集群架构中的session分离
使用redis缓存一些不经常发生变化的数据。
3.数据结构
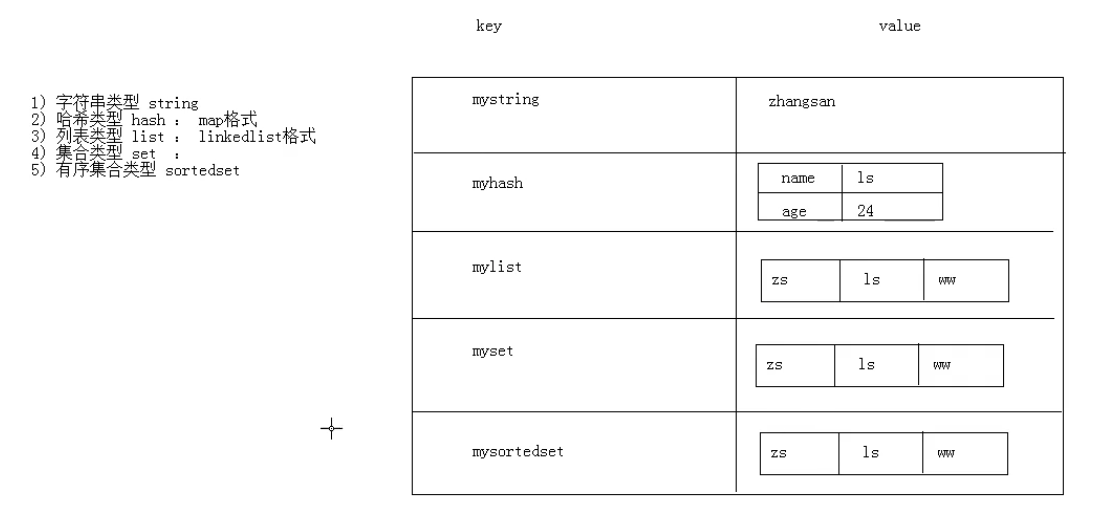
Redis是key/value键值对形式的数据库。key是字符串,value可以是以下五种类型
value的数据结构:
1) 字符串类型 string
2) 哈希类型 hash : map格式
3) 列表类型 list : linkedlist格式。支持重复元素
4) 集合类型 set : 不允许重复元素
5) 有序集合类型 sortedset:不允许重复元素,且元素有顺序
4.操作命令:
https://www.redis.net.cn/tutorial/3517.html
命令操作 1. redis的数据结构: * redis存储的是:key,value格式的数据,其中key都是字符串,value有5种不同的数据结构 * value的数据结构: 1) 字符串类型 string 2) 哈希类型 hash : map格式 3) 列表类型 list : linkedlist格式。支持重复元素 4) 集合类型 set : 不允许重复元素 5) 有序集合类型 sortedset:不允许重复元素,且元素有顺序 2. 字符串类型 string 1. 存储: set key value 127.0.0.1:6379> set username zhangsan OK 2. 获取: get key 127.0.0.1:6379> get username "zhangsan" 3. 删除: del key 127.0.0.1:6379> del age (integer) 1 3. 哈希类型 hash 1. 存储: hset key field value 127.0.0.1:6379> hset myhash username lisi (integer) 1 127.0.0.1:6379> hset myhash password 123 (integer) 1 2. 获取: * hget key field: 获取指定的field对应的值 127.0.0.1:6379> hget myhash username "lisi" * hgetall key:获取所有的field和value 127.0.0.1:6379> hgetall myhash 1) "username" 2) "lisi" 3) "password" 4) "123" 3. 删除: hdel key field 127.0.0.1:6379> hdel myhash username (integer) 1 4. 列表类型 list:可以添加一个元素到列表的头部(左边)或者尾部(右边) 1. 添加: 1. lpush key value: 将元素加入列表左表 2. rpush key value:将元素加入列表右边 127.0.0.1:6379> lpush myList a (integer) 1 127.0.0.1:6379> lpush myList b (integer) 2 127.0.0.1:6379> rpush myList c (integer) 3 2. 获取: * lrange key start end :范围获取 127.0.0.1:6379> lrange myList 0 -1 1) "b" 2) "a" 3) "c" 3. 删除: * lpop key: 删除列表最左边的元素,并将元素返回 * rpop key: 删除列表最右边的元素,并将元素返回 5. 集合类型 set : 不允许重复元素 1. 存储:sadd key value 127.0.0.1:6379> sadd myset a (integer) 1 127.0.0.1:6379> sadd myset a (integer) 0 2. 获取:smembers key:获取set集合中所有元素 127.0.0.1:6379> smembers myset 1) "a" 3. 删除:srem key value:删除set集合中的某个元素 127.0.0.1:6379> srem myset a (integer) 1 6. 有序集合类型 sortedset:不允许重复元素,且元素有顺序.每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。 1. 存储:zadd key score value 127.0.0.1:6379> zadd mysort 60 zhangsan (integer) 1 127.0.0.1:6379> zadd mysort 50 lisi (integer) 1 127.0.0.1:6379> zadd mysort 80 wangwu (integer) 1 2. 获取:zrange key start end [withscores] 127.0.0.1:6379> zrange mysort 0 -1 1) "lisi" 2) "zhangsan" 3) "wangwu" 127.0.0.1:6379> zrange mysort 0 -1 withscores 1) "zhangsan" 2) "60" 3) "wangwu" 4) "80" 5) "lisi" 6) "500" 3. 删除:zrem key value 127.0.0.1:6379> zrem mysort lisi (integer) 1 7. 通用命令 1. keys * : 查询所有的键 2. type key : 获取键对应的value的类型 3. del key:删除指定的key value
二、NOSQL和关系型数据库(MySql)比较
1.查询速度:nosql数据库将数据存储于缓存之中,关系型数据库将数据存储在硬盘中,自然查询速度远不及nosql数据库。
2.存储数据的格式:nosql的存储格式是key,value形式、文档形式、图片形式等等,所以可以存储基础类型以及对象或者是集合等各种格式,而数据库则只支持基础类型。
非关系型数据库的优势:
1)性能NOSQL是基于键值对的,可以想象成表中的主键和值的对应关系,而且不需要经过SQL层的解析,所以性能非常高。
2)可扩展性同样也是因为基于键值对,数据之间没有耦合性,所以非常容易水平扩展。
关系型数据库的优势:
1)复杂查询可以用SQL语句方便的在一个表以及多个表之间做非常复杂的数据查询。
2)事务支持使得对于安全性能很高的数据访问要求得以实现。对于这两类数据库,对方的优势就是自己的弱势,反之亦然。
三、持久化
1. redis是一个内存数据库,当redis服务器重启,获取电脑重启,数据会丢失,我们可以将redis内存中的数据持久化保存到硬盘的文件中。
2. redis持久化机制:
- RDB(redis database):默认方式,不需要进行配置,默认就使用这种机制
* 在一定的间隔时间中,检测key的变化情况,然后持久化数据
1. 编辑redis.windows.conf文件

参数解释
| #after 900 sec (15 min) if at least 1 key changed | 15分钟有一个键变化就进行持久化 |
| save 900 1 | |
| #after 300 sec (5 min) if at least 10 keys changed | 5分钟有10个键变化就进行持久化 |
| save 300 10 | |
|
#after 60 sec if at least 10000 keys changed save 60 10000 |
1分钟有1000个键变化就进行持久化 |
当发生持久化后,就会在dump.rdb文件
- AOF(append only file)
日志记录的方式,可以记录每一条命令的操作。可以每一次命令操作后,持久化数据
RDB优点:
1 适合大规模的数据恢复。
2 如果业务对数据完整性和一致性要求不高,RDB是很好的选择。
缺点:
1 数据的完整性和一致性不高,因为RDB可能在最后一次备份时宕机了。
2 备份时占用内存
Redis 针对 AOF文件大的问题,提供重写的瘦身机制。
四、Redis缓存相关问题
1.缓存穿透
2.缓存雪崩
3.缓存击穿
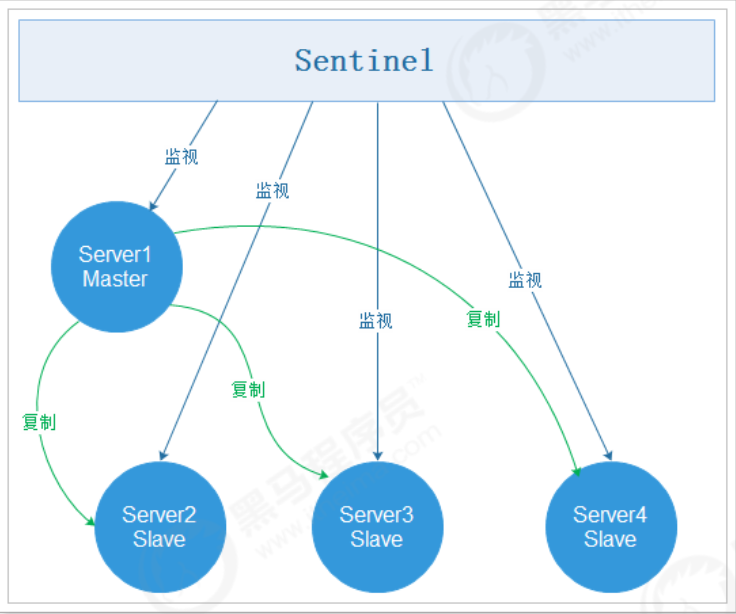
五、Redis集群方案
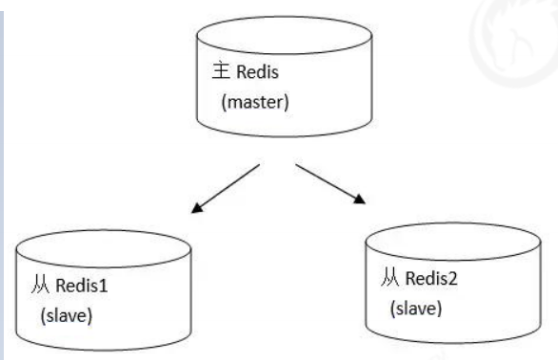
这是一个典型的分布式读写分离模型。我们可以利用master来处理写操作,slave提供读操作。这样可以有效减少单个机器的并发访问数量。
2. 通过架构设计而保证系统高可用的,其核心准则是:冗余。
3. 实现自动故障转移