主题
公司在basecode的用法上是比较有新意的,所以准备记录分享下公司的用法.
说明
basecode公司的一个主要用途就是用于一些基础的代码表,参数表的前台操作.这些表有很多,用spring data jpa(hibernate)的时候,又不想为每个表写个实体,因为太多了,每个实体还需要dao和service等等..这些表用法很单一,主要用于前台表单的下拉框,比如证件种类有:身份证,军官证,学生证....这些证件的代码和名称等信息就是存在一个代码表里的.前台下拉的时候可能会列出所有值,也可能会有一些过滤.
这种用法下需要前后台配合,前台我们使用的是miniui,需要对miniui现有的组件进行一些封装来实现自动查询数据库,后台也需要有对应的查询的逻辑..这里主要介绍后台的一些封装.
用途
主要用于前台下拉框自动填充数据库里不同参数表,代码表的代码的参数的值(比如中国行政区划地区代码和对应的代码值),开发过程中不需要自己手写JS或者后台代码,全部都有封装.只需要配置一下即可实现前台下拉框填充后台数据库里的代码表的值.
主要实现原理
1.配置表:因为没有实体去对应代码表或者参数表,所以肯定要有个配置表去记录有哪些代码表,哪些参数表,应该怎么去不同的表中根据何种逻辑去取值.这张表我们简称def表吧.
2.代码逻辑:有了配置表以后我们相当于有了规则,知道根据配置的规则应该如何去找数据.那么还需要有一套代码逻辑去实现这个规则.这套代码逻辑其实不复杂.就是利用先自己根据不同情况拼接不同的SQL,然后通过JPA的执行原生SQL的方法去查询各个配置的表的数据.
具体实现
配置表
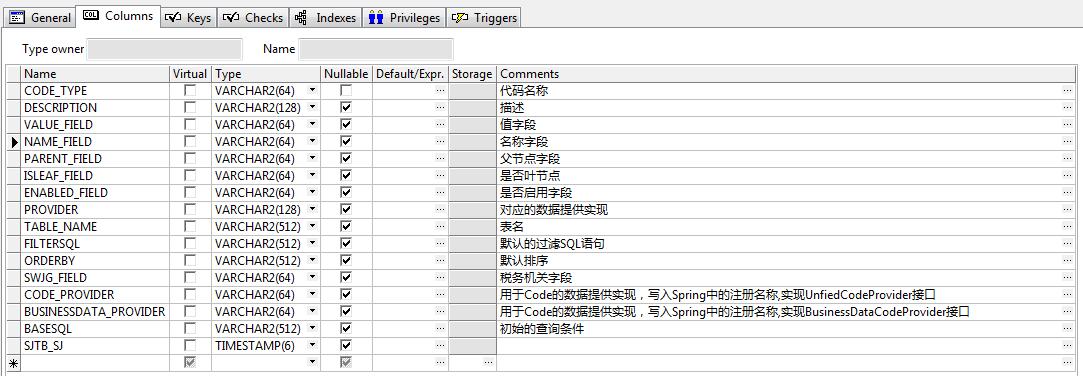
字段很多,说明配置还是比较灵活的.不过大部分情况下大部分字段是用不到的.我介绍一下最主要的用法.
code_type:像ID一样,为了找到一条配置
value_field:表明下拉框的显示的值对应的代码的对应SQL查出来的哪一列
name_field:表明下拉框的显示的值对应SQL查出来的哪一列
value_field和name_field就是前台下拉框组件里显示值和传给后台的参数值对应数据库里的SQL查询结果的哪一列.比如下拉框显示值'有效'对应的代码是'Y'.或者说就是前台下拉框的key和value.
parent_field和isLeaf_field和enabled_field用于构建树组件.树组件和普通下拉框相比主要多了上级节点属性(parent_field)和当前节点是否有下级节点(isLeaf_field)属性.
Table_name就是要查哪张表的表名,或者直接写SQL查询也一样.
FilterSQL就是前台传给后台一些参数的情况下根据参数动态在Table_name后拼接where条件,达到过滤查询结果的目的.
code_provider和bussinessdata_provider就是不走一般的查询逻辑,自己定义比较复杂的查询逻辑的时候用到.相当于一般情况下会有个默认的provider,你不用他默认的查询逻辑,就需要自己配置.
实现
光有配置没有什么用,我们来看看主要实现吧.
首先,既然我们把这么多不同业务场景的相同需求抽象出来做了一个统一处理,那我们肯定要有个统一入口.这个入口Controller我们就叫他basecode controller好了.
前面配置表中提到一条配置相当于是一种查数据的方式,对应一种下拉框取值的方式.那问我这个下拉框要怎么取值,相当于是问我配置表中怎么确定一条配置数据咯.
配置表中的主键,codeType能确定一条数据,所以每个下拉框向后台发送请求查找数据的时候肯定要把这个codeType传过啦.(下拉框这个请求是在页面加载的时候就会发起的,是公司封装了miniui的组件,这篇文章主要涉及后台basecode,所以前台的封装就暂时不说了.后面会再写文章分享的).

controller中其实也没做什么操作,就只是组装一下和codeType同时传过来的,用于数据过滤的参数,放到paramMap里和codeType一起传给codeHelper,委托codeHelper去做具体的查询与过滤数据.
1 @Override 2 public List<?> getCodeList(String codeType, Map<String, ?> paramMap) { 3 List<BaseCodeDTO> result = null; 4 try { 5 BaseCodeDefDTO defDto = codeDefService.getCodeDefByCodeType(codeType); 6 if (defDto != null) { 7 result = this.getProvider(defDto).getCodeList(defDto, paramMap); 8 } 9 } catch (Exception ex) { 10 LOGGER.info(ex.getMessage(), ex); 11 throw new RuntimeException(ex);// NOSONAR 12 } 13 return result; 14 }
从getCodeList方法可以看出,第5行先得到这个def表对应的java对象(jpa的映射方法).然后L7得到def表配置的Porvider(codeProvider成员域).再委托Provider去查找数据.所以说到底还是通过Provider去查找数据.
我们先来看看怎么getProvider的.
1 private UnifiedCodeProvider getProvider(BaseCodeDefDTO defDto) { 2 String providerDef = StringUtils.isNotEmpty(defDto.getCodeProvider()) ? defDto.getCodeProvider() 3 : "defaultCodeProvider"; 4 Object provider = SpringContextUtil.getBean(providerDef); 5 if (provider instanceof UnifiedCodeProvider) { 6 provider = (UnifiedCodeProvider) provider; 7 } else { 8 provider = (UnifiedCodeProvider) SpringContextUtil.getBean("defaultCodeProvider"); 9 } 10 if (provider == null) { 11 // TODO:异常抛出修改 12 throw new RuntimeException("basecode provider:" + defDto.getProvider() + " is not exist! ");// NOSONAR 13 } 14 return (UnifiedCodeProvider) provider; 15 16 }
从上面的代码中可以看出,如果在def里配置了provider,那就从Spring的context中根据bean名字取出provider,同时也说明配置的provider是需要在项目启动的时候由Spring加载的.
如果没配置,那就用公共的provider,这个provider的名字叫做defaultCodeProvider.
取到provider以后我们就可以getCodeList了.我们主要看看公共的provider吧,因为绝大多数情况下用的是这个provider.
1 @Override 2 public List<BaseCodeDTO> getCodeList(BaseCodeDefDTO defDto, Map<String, ?> paramMap) { 3 // 重组参数 4 Map<String, Object> realMap = new HashMap<String, Object>(); 5 if (paramMap != null && !paramMap.isEmpty()) { 6 for (Entry<String, ?> entry : paramMap.entrySet()) { 7 if ("basevalue".equalsIgnoreCase(entry.getKey())) { 8 realMap.put(defDto.getParentField(), entry.getValue()); 9 } else if ("value".equalsIgnoreCase(entry.getKey())) { 10 realMap.put(defDto.getValueField(), entry.getValue()); 11 } else if ("label".equalsIgnoreCase(entry.getKey())) { 12 realMap.put(defDto.getNameField(), entry.getValue()); 13 } else if ("isleaf".equalsIgnoreCase(entry.getKey())) { 14 realMap.put(defDto.getIsleafField(), entry.getValue()); 15 } else if ("swjg".equalsIgnoreCase(entry.getKey())) { 16 realMap.put(defDto.getSwjgField(), entry.getValue()); 17 } else if ("enabled".equalsIgnoreCase(entry.getKey())) { 18 realMap.put(defDto.getEnabledField(), entry.getValue()); 19 } else if ("parent".equalsIgnoreCase(entry.getKey())) { 20 realMap.put(defDto.getParentField(), entry.getValue()); 21 } else { 22 realMap.put(entry.getKey(), entry.getValue()); 23 } 24 } 25 } 26 return codeService.getCodeListParamMap(defDto, realMap); 27 }
getCodeList里对传过来的Map里的参数进行了一些加工,如果map里有key是"value"呀,"label"呀,"parent"呀类似这些值的话会被替换成def里配置的字符串,相当于是修改了map里的key,替换成了数据库里配置的值,除此之外的key原封不动的放进新的map里.
然后委托codeService去查数据
1 public List<BaseCodeDTO> getCodeListParamMap(BaseCodeDefDTO codeModel, Map<String, Object> param) { 2 List<BaseCodeDTO> result = null; 3 try { 4 String baseSql = this.buildBaseSql(codeModel, false); 5 List<Object> paramList = new ArrayList<Object>(); 6 String whereCause = this.buildWhereCauseFromMap(codeModel, param, paramList); 7 if (param == null) { 8 param = new HashMap<String, Object>();// NOSONAR 9 } 10 StringBuilder sqlbuffer = new StringBuilder(); 11 sqlbuffer.append(baseSql).append(" WHERE ").append(whereCause).append(" ") 12 .append(StringUtils.isNotEmpty(codeModel.getOrderby()) ? codeModel.getOrderby() : ""); 13 Map<String, Object> paramMap = new HashMap<String, Object>(); 14 if (param != null && !param.isEmpty()) { 15 for (Entry<String, Object> entry : param.entrySet()) { 16 if (!"filterParam".equalsIgnoreCase(entry.getKey()) 17 && !"initParam".equalsIgnoreCase(entry.getKey())) { 18 paramMap.put(entry.getKey(), entry.getValue()); 19 } 20 } 21 } 22 result = navtiveRepository.executeQuerySql(sqlbuffer.toString(), paramMap, BaseCodeDTO.class); 23 } catch (Exception ex) { 24 LOGGER.info(ex.getMessage(), ex); 25 throw new RuntimeException(ex);// NOSONAR 26 } 27 return result; 28 29 }
getCodeListParamMap方法有点长,但是核心就是4行代码:
L4:先拼接出要查的代码表或者参数表的基本的查询SQL,这里是通过调用buildBaseSql方法做到的.
L6:根据传过来的Map里的参数拼接得到where条件字符串,这里是通过调用buildWhereCauseFromMap方法.
L11:L4+L6得到完整SQL语句,如果有配置order by的话,同时拼接order by.
L22:调用公司对JPA原生SQL的封装的类来执行SQL(之前分享过这部分封装).
1 private String buildBaseSql(BaseCodeDefDTO codeModel, boolean distinckSign) { 2 StringBuilder sqlBuffer = new StringBuilder(); 3 if (codeModel.getValueField() == null) { 4 throw new RuntimeException("代码模型未设置值字段CodeField");// NOSONAR 5 } 6 if (codeModel.getNameField() == null) { 7 throw new RuntimeException("代码模型未设置名称字段NameField");// NOSONAR 8 } 9 if (codeModel.getTableName() == null) { 10 throw new RuntimeException("代码模型未设置TABLE");// NOSONAR 11 } 12 13 sqlBuffer.append(" SELECT "); 14 if (distinckSign) { 15 sqlBuffer.append(" distinct "); 16 } 17 sqlBuffer.append(codeModel.getValueField()).append(" as value ,").append(codeModel.getNameField()); 18 sqlBuffer.append(" as label ,").append(codeModel.getParentField() != null ? codeModel.getParentField() : "''"); 19 sqlBuffer.append(" as parent, "); 20 sqlBuffer.append(codeModel.getEnabledField() != null ? codeModel.getEnabledField() : "''"); 21 sqlBuffer.append(" as enabled, "); 22 sqlBuffer.append(codeModel.getIsleafField() != null ? codeModel.getIsleafField() : "'false'"); 23 sqlBuffer.append(" as isleaf, ").append(codeModel.getSwjgField() != null ? codeModel.getSwjgField() : "''"); 24 sqlBuffer.append(" as swjgdm ").append(" from( ").append(codeModel.getTableName()).append(" ) t "); 25 return sqlBuffer.toString(); 26 27 }
buildBaseSql方法就是根据def表里的table_name列构造出了一个select语句.这个select语句select的内容是统一的.都是select value,label,parent等内容.因为前端下拉框组件需要的就是这么几个内容,所以这里做到了统一处理.
同时def表里table列可以配置SQL或者Table name的原因在于这里是在table列的值会被当做子查询(L24),所以写SQL或者直接写表名都是可以的.
1 @SuppressWarnings("unchecked") 2 private String buildWhereCauseFromMap(BaseCodeDefDTO codeModel, Map<String, Object> param, List<Object> paramList) 3 throws IllegalArgumentException, IllegalAccessException, InvocationTargetException { 4 StringBuilder sqlBuffer = new StringBuilder(" 1=1 "); 5 if (param != null && param.size() > 0) { 6 Map<String, Object> scenarioParamMap = new HashMap<String, Object>(); 7 for (Entry<String, Object> entry : param.entrySet()) { 8 Object value = entry.getValue(); 9 if (value != null) { 10 if ("filterParam".equalsIgnoreCase(entry.getKey()) || "initParam".equalsIgnoreCase(entry.getKey())) { 11 if (StringUtils.isNotEmpty(codeModel.getFiltersql())) { 12 sqlBuffer.append(" AND "); 13 try { 14 Map<String, Object> map = (Map<String, Object>) value; 15 boolean hasMultipleScenarios = map.containsKey("SCENARIO"); 16 if (hasMultipleScenarios) { 17 Map<String, String> dataMap = new HashMap<String, String>(); 18 dataMap.put("SCENARIO", (String) map.get("SCENARIO")); 19 map.remove("SCENARIO"); 20 StringWriter sw = new StringWriter(); 21 processor.processPlainText(codeModel.getFiltersql(), dataMap, sw); 22 sqlBuffer.append(sw.toString()); 23 } else { 24 sqlBuffer.append(codeModel.getFiltersql()); 25 } 26 scenarioParamMap.putAll(map); 27 } catch (Exception e) { 28 LOGGER.info(e.getMessage(), e); 29 throw new RuntimeException(e);// NOSONAR 30 } 31 } 32 } else { 33 sqlBuffer.append(" AND "); 34 sqlBuffer.append(entry.getKey()).append(" = :" + entry.getKey()); 35 paramList.add(value); 36 } 37 } 38 } 39 param.putAll(scenarioParamMap); 40 } 41 return sqlBuffer.toString(); 42 43 }
buildWhereCauseFromMap方法略复杂.
除去各种校验以外核心代码为:
1 if ("filterParam".equalsIgnoreCase(entry.getKey()) || "initParam".equalsIgnoreCase(entry.getKey())) { 2 if (StringUtils.isNotEmpty(codeModel.getFiltersql())) { 3 sqlBuffer.append(" AND "); 4 try { 5 Map<String, Object> map = (Map<String, Object>) value; 6 boolean hasMultipleScenarios = map.containsKey("SCENARIO"); 7 if (hasMultipleScenarios) { 8 Map<String, String> dataMap = new HashMap<String, String>(); 9 dataMap.put("SCENARIO", (String) map.get("SCENARIO")); 10 map.remove("SCENARIO"); 11 StringWriter sw = new StringWriter(); 12 processor.processPlainText(codeModel.getFiltersql(), dataMap, sw); 13 sqlBuffer.append(sw.toString()); 14 } else { 15 sqlBuffer.append(codeModel.getFiltersql()); 16 } 17 scenarioParamMap.putAll(map); 18 } catch (Exception e) { 19 LOGGER.info(e.getMessage(), e); 20 throw new RuntimeException(e);// NOSONAR 21 } 22 } 23 } else { 24 sqlBuffer.append(" AND "); 25 sqlBuffer.append(entry.getKey()).append(" = :" + entry.getKey()); 26 paramList.add(value); 27 }
里面有2条分支:
1.L23 else路线:如果前面param的map里没有filterParam或者initParam的key的话就直接把map里和key作为参数绑定拼接到SQL上,比如yxbz=:yxbz,后面jpa执行原生SQL的时候会把:yxbz替换成具体的值.
2.L1 filterParam和initParam路线:
这里就比较复杂了.
所谓initParam就是组件第一次加载的时候需要显示的数据需要用到的参数.后续组件再发起请求的时候不会再传这个参数.
所谓filterParam就是组件每次加载的时候需都要用到的参数.
initParam这种用法经常用在树组件上,比如第一次加载树组件的时候可能需要N个过滤条件,所以需要在initParam里传递N个过滤的参数,后续加载只需要加载你点击的那个父节点下的子节点就行了这个时候initParam就什么参数都不用传递了.再传递一个parant参数表示父节点的值就行了.所以可能2次传过来的参数是不同的.
而filterParam是每次都会传的.
如果走这条路线的话def表里肯定会配置filterSQL,即where里要拼接的过滤的SQL.
filterSQL可以配合SCENARIO来使用,所谓SCENARIO就是在不同场景下拼接不同的SQL,具体拼接什么SQL.是根据传递过来的参数Map来生成相应的字符串SQL.主要实现是通过freemarker来解析的(可能公司架构师觉得这里用freemarker解析生成字符串比较简单吧,至少不需要自己去写解析方法.....),所以这里依赖freeMarker.
来看个def表里filterSQL的例子:
<#if SCENARIO=="ZSXMCLAUSE"> YXBZ='Y' and XYBZ='Y' and ZSXM_DM=:ZSXMDM <#elseif SCENARIO== "YXBZ"> YXBZ='Y' and XYBZ='Y' <#elseif SCENARIO== "SJZSPM"> YXBZ='Y'</#if>
比如的filterSQL配置了3种场景,如果传过来的SCENARIO是ZSXMCLAUSE那就只拼接YXBZ='Y' and XYBZ='Y' and ZSXM_DM=:ZSXMDM 字符串
如果是SCENARIO是YXBZ那就只拼接YXBZ='Y' and XYBZ='Y'...
如果是.......
稍微总结一下的话就是说:
initParam可以让组件在第一次和后续的请求传递不同的参数.
filterParam是组件每次请求都会传递参数
initParam和filterParam配合SCENARIO可以多个miniui组件公用一条def表配置但是拼接出不同的where条件SQL.
当然initParam和filterSQL也可以不配合 SCENARIO 来使用,这种用法下就直接把filterParam或者initParam里面的变量通过JPA的Query的setParamter方法绑定到SQL中去.但是只有一种SCENARIO的时候可以把filterSQL直接放到table_name里.反正只有一种情景..所以说一般用到filterParam的时候都会有N个SCENARIO,不同组件选择不同的SCENARIO .
这段代码写的比较一般...本来有个缺陷就是当传了SCENARIO过来走filterParam和initParam路线的时候其他的key和value会被忽略,导致部分绑定的参数没有被设值.
所以后来修改了代码,就是增加了各种remove和addAll什么的调用...然后在getCodeListParamMap方法里再次判断param Map是否非空.....显得代码逻辑很混乱..当然....能用就行了....
有了拼接的SQL,就只要调用JPA去执行原生SQL就可以了.
小结
公司的basecode功能展示了不通过JPA映射,通过配置来实现不同表通过统一规则查数据的一种方式.还是比较方便的.
除此之外basecode还有些其他的功能,比如通过name找code,通过code找name等等.....都是通过def表来实现的...不过其他的功能都是比较简单的,即使不通过这套代码也可以很方便的实现...所以我就不再仔细介绍了..