1、新增document
在索引中增加文档。在index中增加document。
ES有自动识别机制。如果增加的document对应的index不存在。自动创建,如果index存在,type不存在自动创建。如果index和type都存在,则使用现有的。
put语法新增:
此操作为手工指定id的document新增方式
PUT /index_name/type_name/id{field_name:field_value}
PUT test_index/my_type/1
{
"name":"test_doc_01",
"remark":"first test elastic search",
"order_no":1
}
返回值说明:
{
"_index": "test_index", # 新增的document在什么index中
"_type": "my_type", # 新增的document在index中的哪一个type中
"_id": "1", # 指定的id是多少
"_version": 7, #版本号(每次有增删改操作,版本+1)
"result": "updated", # 执行结果 created 新增成功 updated 修改成功 deleted 删除成功
"_shards": { # 分片信息
"total": 2, #分片数量只提示primary shard
"successful": 2, #数据document一定只存放在index中的某一个primary shard中 replica shard 中也会执行 1+1=2
"failed": 0
},
"_seq_no": 6, #执行的序列号
"_primary_term": 1 #词条比对
}
POST 语法:
此操作作为ES自动生成id的新增Document方式。
语法: POST /index_name/type_name{"field_name":"filed_value"}
POST test_index/my_type
{
"name":"post create first",
"remark":"post remark first",
"order_no":4
}
注意:在ES中,一个index中的所有type类型的Document是存储在一起的,如果index中的不同的type之间的field差别太大,也会影响到磁盘的存储结构和存储空间的占用。如:test_index中有test_type1和test_type2两个不同的类型,type1中的document结构为:{"_id":"1","f1":"v1","f2":"v2"},type2中的document结构为:{"_id":"2","f3":"v3","f4":"v4"},那么ES在存储的时候,统一的存储方式是{"_id":"1","f1":"v1","f2":"v2","f3":"","f4":""}, {"_id":"2","f1":"","f2":"","f3":"v3","f4","v4"}、建议,每个index中存储的document结构不要有太大的差别。尽量控制在总计字段数据的10%以内。
2、查询document
GET 方式查询
GET /index_name/type_name/id
如: GET /test_index/my_type/1
结果:
{
"_index": "test_index",
"_type": "my_type",
"_id": "1",
"_version": 7,
"found": true,
"_source": { # 找到document的数据内容
"name": "test_doc_01",
"remark": "first test elastic search",
"order_no": 1
}
}
GET _mget 批量查询
批量查询可以提高查询效率。推荐使用(相对于单数据查询来说)
GET /_mget
{
"docs" : [
{
"_index":"test_index",
"_type":"my_type",
"_id":"1"
}, {
"_index":"test_index",
"_type":"my_type",
"_id":"2"
}
]
}
GET test_index/_mget
{
"docs" :[
{
"_type":"my_type",
"_id":"1"
}, {
"_type":"my_type",
"_id":"2"
}
]
}
GET test_index/my_type/_mget
{
"docs":[
{
"_id":"1"
}, {
"_id":"2"
}
]
}
3、修改document
PUT 替换document(全量替换)
和新增PUT语法是一样的
PUT /index_name/type_name/id{field_name:field_value}
要求新数据的字段信息和原数据的字段信息一致。也就是必须包括Document中的所有field才行。本操作相当于覆盖操作。全量替换的过程中,ES不会真的修改Document中的数据,而是标记ES中原有的Document为deleted状态,再创建一个新的Document来存储数据,当ES中的数据量过大时,ES后台回收deleted状态的Document(现阶段理解,后续课程中会详细说明)。
PUT test_index/my_type/1
{
"name":"test_doc_01_bak",
"remark":"first test elastic search_bak"
}
再次查询数据得到值:GET test_index/my_type/3
{
"_index": "test_index",
"_type": "my_type",
"_id": "3",
"_version": 2,
"found": true,
"_source": {
"name": "test_doc_01_bak",
"remark": "first test elastic search_bak"
# order_no 已被替换掉
}
}
PUT语法强制新增
如果使用PUT语法对同一个Document执行多次操作。是一种全量替换操作。如果需要ES辅助检查PUT的Document是否已存在,可以使用强制新增语法。
使用强制新增语法时,如果Document的id在ES中已存在,则会报错。(version conflict, document already exists)
语法:
PUT /index_name/type_name/id/_create{"field_name":"field_value"}
或:
put /index_name/type_name/id?op_type=create{"field_name":"field_value"}
PUT test_index/my_type/04/_create
{
"name":"fore_doc_04",
"remark":"fore test elastic search",
"order_no":4
}
# 返回:
{
"_index": "test_index",
"_type": "my_type",
"_id": "04",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 2
}
?op_type=create
PUT test_index/my_type/04?op_type=create
{
"name":"fore_doc_04",
"remark":"fore test elastic search",
"order_no":4
}
# 返回:
{
"error": {
"root_cause": [
{
"type": "version_conflict_engine_exception",
"reason": "[my_type][04]: version conflict, document already exists (current version [1])",
"index_uuid": "oGaO5Tt_TjGPGm4X6R4rnQ",
"shard": "1",
"index": "test_index"
}
],
"type": "version_conflict_engine_exception",
"reason": "[my_type][04]: version conflict, document already exists (current version [1])",
"index_uuid": "oGaO5Tt_TjGPGm4X6R4rnQ",
"shard": "1",
"index": "test_index"
},
"status": 409
}
POST 更新document(partial update)
POST /index_name/type_name/id?_update{"field_name":"field_value"}
只更新某Document中的部分字段。这种更新方式也是标记原有数据为deleted状态,创建一个新的Document数据,将新的字段和未更新的原有字段组成这个新的Document,并创建。对比全量替换而言,只是操作上的方便,在底层执行上几乎没有区别。
POST test_index/my_type/05/_update
{
"doc": {
"name":"five_doc_05_bak" # 只会更新字段name
}
}
4、删除document
ES中执行删除操作时,ES先标记Document为deleted状态,而不是直接物理删除。当ES存储空间不足或工作空闲时,才会执行物理删除操作。标记为deleted状态的数据不会被查询搜索到。
ES中删除index,也是标记。后续才会执行物理删除。所有的标记动作都是为了NRT实现(近实时)。
DELETE /index_name/type_name/id
DELETE test_index/my_type/05
# 返回:
{
"_index": "test_index",
"_type": "my_type",
"_id": "05",
"_version": 3,
"result": "deleted",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_seq_no": 3,
"_primary_term": 2
}
5、bulk批量增删改
使用bulk语法执行批量增删改。语法格式如下
POST /_bulk
{"action_type":{"metadata_name":"metadata_value"}}
{documents data | action datas}
语法中的action_type可选值为:
create:强制创建,相当于 PUT/index_name/type_name/id/_create
index:普通的put操作,相当于创建Document或全量替换
update:更新操作(partial update), 相当于 POST /index_name/type_name/id/_update{"filed_name":"field_value"}
delete: 删除操作
案例如下:下述案例中将所有的操作语法分离了。可以一次性执行增删改的所有功能。最后的语法是批量操作语法
POST /_bulk
{"create":{"_index":"test_index","_type":"my_type","_id":"06"}}
{"name":"name6","remark":"remark6","order_no":"06"}
{"index":{"_index":"test_index","_type":"my_type","_id":"06"}}
{"name":"name6_bak","remark":"remark06_bak","order_no":"06"}
{"create":{"_index":"test_index","_type":"my_type","_id":"06"}}
{"name":"name_cover"}
{"update":{"_index":"test_index","_type":"my_type","_id":"06"}}
{"doc":{"name":"name6 partial update"}}
{"delete":{"_index":"test_index","_type":"my_type","_id":"05"}}
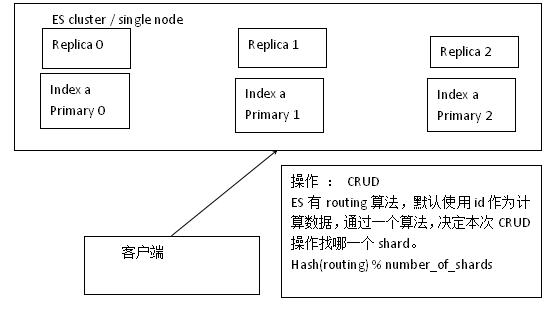
6、 Document routing 机制
ES对Document的管理有一个路由算法,这种算法决定了Document存放在哪一个primary shard中。算法为:primary shard = hash(routing) % number_of_primary_shards。其中的routing默认为Document中的元数据_id,也可以手工指定routing的值,指定方式为:PUT /index_name/type_name/id?routing=xxx。手工指定routing在海量数据中非常有用,通过手工指定的routing,ES会将相关联的Document存储在同一个shard中,方便后期进行应用级别的负载均衡并可以提高数据检索的效率。如:存电商中的商品,使用商品类型的编号作为routing,ES会把同一个类型的商品document数据,存在同一个shard中。查询的时候,同一个类型的商品,在一个shard上查询,效率最高。
如果是写操作。计算routing结果后,决定本次写操作定位到哪一个primary shard分片上,primary shard 分片写成功后,自动同步到对应replica shard上。如果是读操作,计算routing结果后,决定本次读操作定位到哪一个primary shard 或其对应的replica shard上。实现读负载均衡,replica shard数量越多,并发读能力越强。
PUT /test_index/my_type/10?routing=type_id{}
7、Document增删改原理简图
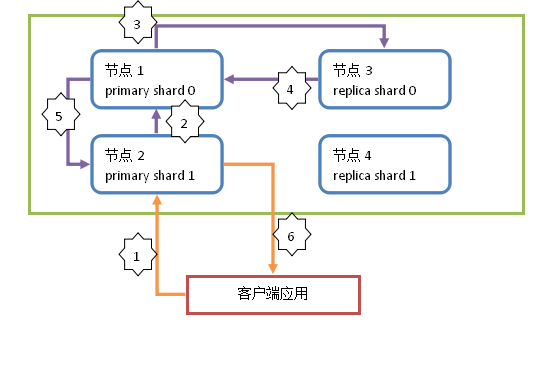
解释:
1 : 客户端发起请求,执行增删改操作。所有的增删改操作都由primary shard直接处理,replica shard只被动的备份数据。此操作请求到节点2(请求发送到的节点随机),这个节点称为协调节点(coordinate node)。
2 : 协调节点通过路由算法,计算出本次操作的Document所在的shard。假设本次操作的Document所在shard为 primary shard 0。协调节点计算后,会将操作请求转发到节点1。
3 : 节点1中的primary shard 0在处理请求后,会将数据的变化同步到对应的replica shard 0中,也就是发送一个同步数据的请求到节点3中。
4 : replica shard 0在同步数据后,会响应通知请求这同步成功,也就是响应给primary shard 0(节点1)。
5 : primary shard 0(节点1)接收到replica shard 0的同步成功响应后,会响应请求者,本次操作完成。也就是响应给协调节点(节点2)。
6 : 协调节点返回响应给客户端,通知操作结果。
8、Document查询简图
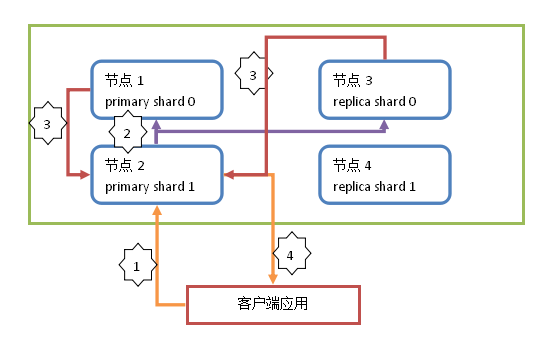
解释:
1 : 客户端发起请求,执行查询操作。查询操作都由primary shard和replica shard共同处理。此操作请求到节点2(请求发送到的节点随机),这个节点称为协调节点(coordinate node)。
2 : 协调节点通过路由算法,计算出本次查询的Document所在的shard。假设本次查询的Document所在shard为 shard 0。协调节点计算后,会将操作请求转发到节点1或节点3。分配请求到节点1还是节点3通过随机算法计算,ES会保证当请求量足够大的时候,primary shard和replica shard处理的查询请求数是均等的(是不绝对一致)。
3 : 节点1或节点3中的primary shard 0或replica shard 0在处理请求后,会将查询结果返回给协调节点(节点2)。
4 : 协调节点得到查询结果后,再将查询结果返回给客户端。